Best Practices for Integrating Python Airflow With DolphinDB
As a high-performance time-series database, DolphinDB often faces requirements for data cleaning, transformation, and loading (ETL) in production environments. Airflow provides an effective framework to organize and manage these ETL workflows. This tutorial provides a practical solution for ETL operations in production scenarios by integrating Python Airflow with a high-availability DolphinDB cluster. By leveraging the capabilities provided by Airflow, we can achieve better management of DolphinDB data ETL tasks.
The overall architecture is as follows:
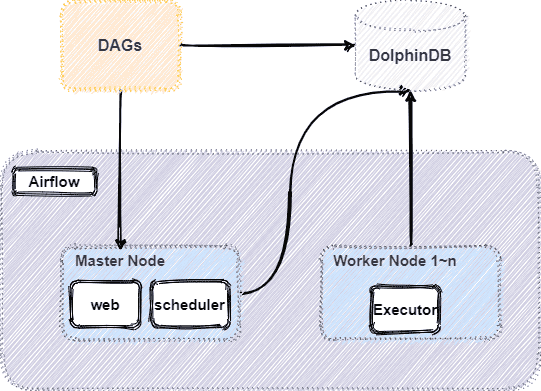
1. Introducing Airflow
1.1 Apache Airflow
Apache Airflow is a programmable, schedulable, and monitorable workflow platform based on Directed Acyclic Graphs (DAGs). It defines tasks with dependencies and executes them in order. Airflow includes command-line tools for system management and a web interface for task scheduling and real-time monitoring, simplifying operations and maintenance.
1.2 Core Features
- Incremental Data Loading: For small datasets, full data loads are feasible. As data grows, incremental loading at fixed intervals (hourly, daily, weekly) becomes essential. Airflow facilitates easy scheduling (e.g., hourly, daily or weekly) of incremental data loads.
- Historical Data Processing: To backfill data after deploying new workflows, set the start_date parameter in the DAG. Airflow will execute tasks retrospectively, supporting backfills spanning weeks, months, or years.
- Partitioned Data Extraction: Partitioning data enables parallel DAG execution, reducing lock contention and optimizing performance. Archived or obsolete data can be removed to maintain efficiency.
- Enforcing Idempotency: The results of DAG runs should always be idempotent. This means that repeated executions with identical parameters produce consistent results.
- Conditional Execution: Airflow supports conditional task execution based on prior task success or failure.
1.3 DolphinDBOperator
DolphinDBOperator is a specialized Airflow operator for executing DolphinDB scripts, queries, and computations within workflows. Key parameters include:
- dolphindb_conn_id: DolphinDB connection identifier.
- sql: DolphinDB script to execute.
- file_path: Path to a DolphinDB .dos script file.
Example:
- Execute inline DolphinDB script by setting
sql
// create a shared table in DolphinDB create_parameter_table = DolphinDBOperator( task_id='create_parameter_table', dolphindb_conn_id='dolphindb_test', sql=''' undef(`paramTable,SHARED) t = table(1:0, `param`value, [STRING, STRING]) share t as paramTable ''' ) - Execute DolphinDB script from file by setting
file_path
// CalAlpha001.dos is a DolphinDB script file case1 = DolphinDBOperator( task_id='case1', dolphindb_conn_id='dolphindb_test', file_path=path + "/StreamCalculating/CalAlpha001.dos" )
1.4 Installation and Deployment
Hardware Environment
| Hardware | Information |
|---|---|
| Host | HostName |
| Extranet IP | xxx.xxx.xxx.122 |
| OS | Linux (Kernel 3.10 and above) |
| Memory | 64 GB |
| CPU | x86_64 with 12 CPU cores |
Software Environment
| Software | Version |
|---|---|
| DolphinDB | 2.00.9 |
| Airflow | 2.5.1 |
| Python | 3.7 and above |
Note:
- This tutorial uses SQLite as the backend database for Airflow. If Airflow fails to start due to an outdated SQLite version, upgrade SQLite, switch the backend, or refer to Set up a Database Backend.
- Before proceeding, ensure the DolphinDB service is deployed. For setup instructions, see High-availability Cluster Deployment or Multi-Container Cluster Deployment with Docker Compose.
Host Environment Configuration
Execute the following command to install Airflow:
pip install airflow-provider-dolphindbAfter installing the airflow.provider.dolphindb plugin, start Airflow. For detailed deployment and installation steps, refer to Airflow Quick Start.
# Initialize the database
airflow db init
# Create a user
airflow users create --username admin --firstname Peter --lastname Parker --role Admin --email spiderman@superhero.org --password admin
# Run the webserver in daemon mode
airflow webserver --port 8080 -D
# Run the scheduler in daemon mode
airflow scheduler -DVerify Airflow startup:
ps -aux | grep airflowExpected output is as shown below.

After successful startup, access the Airflow web interface in your browser. The
default address is http://<IP>:8080. Login with the username
and password created during database initialization.
In the Airflow UI, fill in the DolphinDB connection details to connect to the
DolphinDB database. Once connected, specify
dolphindb_conn_id='dolphindb_test' in the DolphinDBOperator
to run DolphinDB scripts.
2. Airflow Scheduling for Market Data ETL
2.1 Overall ETL Architecture
ETL Module Directory
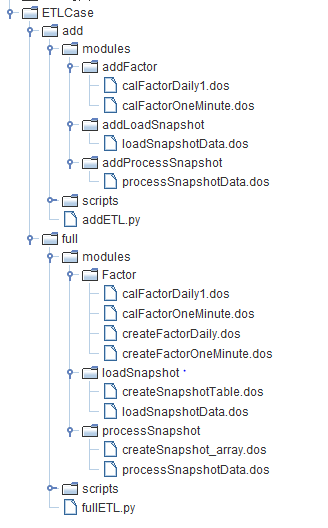
- add: Incremental data ETL
addLoadSnapshot: Daily import of new snapshot raw data.addProcessSnapshot: Process incremental snapshot data into array vectors and clean the data.addFactor: Generate daily and 1-minute OHLC data, and store it.addETL.py: Construct the DAG for incremental data ETL.
- full: Full data ETL
loadSnapshot: Create tables and import snapshot data.processSnapshot: Create tables for cleaned snapshot data, process data into array vectors, and store it.Factor: Create factor storage tables, generate daily and 1-minute OHLC data, and store it.fullETL.py: Construct the DAG for full data ETL.
Data Flow Process
- External data source > ODS data source: Import raw data from external sources into DolphinDB.
- ODS data source > DWD Data Details: Clean raw data, convert multi-level data into array vectors, and remove duplicates.
- DWD Data Details > DWB/DWS Data Aggregation: Generate OHLC data from cleaned snapshot data.
Note: This tutorial uses DolphinDB modules and client tools for engineering management. For more details, see DolphinDB Tutorial: Modules.
2.2 Data Overview
This tutorial uses Level 2 snapshot data from 2020.01.04 to 2021.01.08. Below is the structure of the snapshot table in DolphinDB. Fields such as BidOrderQty and BidPrice contain multi-level data, stored as array vectors in DolphinDB:
| Field | Description | Data Type |
|---|---|---|
| SecurityID | Stock code | SYMBOL |
| DateTime | Date and time | TIMESTAMP |
| PreClosePx | Previous close price | DOUBLE |
| OpenPx | Open price | DOUBLE |
| HighPx | High price | DOUBLE |
| LowPx | Low price | DOUBLE |
| LastPx | Latest price | DOUBLE |
| TotalVolumeTrade | Total trade volume | INT |
| TotalValueTrade | Total trade value | DOUBLE |
| InstrumentStatus | Trading status | SYMBOL |
| BidPrice | Bid prices (10 levels) | DOUBLE[] |
| BidOrderQty | Bid order quantities (10 levels) | INT[] |
| BidNumOrders | Bid order counts (10 levels) | INT[] |
| BidOrders | Bid orders (50 levels) | INT[] |
| OfferPrice | Offer prices (10 levels) | DOUBLE[] |
| OfferOrderQty | Offer order quantities (10 levels) | INT[] |
| OfferNumOrders | Offer order counts (10 levels) | INT[] |
| OfferOrders | Offer orders (50 levels) | INT[] |
| … | … | … |
2.3 DolphinDB Scripts for Data Cleaning
2.3.1 Creating Distributed Databases and Tables
Create raw snapshot data table
module loadSnapshot::createSnapshotTable
// Create a table for raw snapshot data
def createSnapshot(dbName, tbName){
login("admin", "123456")
if(existsDatabase(dbName)){
dropDatabase(dbName)
}
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 50])
// Partitioned by day and stock code
db = database(dbName,COMPO,[db1,db2],engine='TSDB')
colName = ["SecurityID","DateTime","PreClosePx","OpenPx","HighPx","LowPx","LastPx","TotalVolumeTrade","TotalValueTrade","InstrumentStatus","BidPrice0","BidPrice1","BidPrice2","BidPrice3","BidPrice4","BidPrice5","BidPrice6","BidPrice7","BidPrice8","BidPrice9","BidOrderQty0","BidOrderQty1","BidOrderQty2","BidOrderQty3","BidOrderQty4","BidOrderQty5","BidOrderQty6","BidOrderQty7","BidOrderQty8","BidOrderQty9","BidNumOrders0","BidNumOrders1","BidNumOrders2","BidNumOrders3","BidNumOrders4","BidNumOrders5","BidNumOrders6","BidNumOrders7","BidNumOrders8","BidNumOrders9","BidOrders0","BidOrders1","BidOrders2","BidOrders3","BidOrders4","BidOrders5","BidOrders6","BidOrders7","BidOrders8","BidOrders9","BidOrders10","BidOrders11","BidOrders12","BidOrders13","BidOrders14","BidOrders15","BidOrders16","BidOrders17","BidOrders18","BidOrders19","BidOrders20","BidOrders21","BidOrders22","BidOrders23","BidOrders24","BidOrders25","BidOrders26","BidOrders27","BidOrders28","BidOrders29","BidOrders30","BidOrders31","BidOrders32","BidOrders33","BidOrders34","BidOrders35","BidOrders36","BidOrders37","BidOrders38","BidOrders39","BidOrders40","BidOrders41","BidOrders42","BidOrders43","BidOrders44","BidOrders45","BidOrders46","BidOrders47","BidOrders48","BidOrders49","OfferPrice0","OfferPrice1","OfferPrice2","OfferPrice3","OfferPrice4","OfferPrice5","OfferPrice6","OfferPrice7","OfferPrice8","OfferPrice9","OfferOrderQty0","OfferOrderQty1","OfferOrderQty2","OfferOrderQty3","OfferOrderQty4","OfferOrderQty5","OfferOrderQty6","OfferOrderQty7","OfferOrderQty8","OfferOrderQty9","OfferNumOrders0","OfferNumOrders1","OfferNumOrders2","OfferNumOrders3","OfferNumOrders4","OfferNumOrders5","OfferNumOrders6","OfferNumOrders7","OfferNumOrders8","OfferNumOrders9","OfferOrders0","OfferOrders1","OfferOrders2","OfferOrders3","OfferOrders4","OfferOrders5","OfferOrders6","OfferOrders7","OfferOrders8","OfferOrders9","OfferOrders10","OfferOrders11","OfferOrders12","OfferOrders13","OfferOrders14","OfferOrders15","OfferOrders16","OfferOrders17","OfferOrders18","OfferOrders19","OfferOrders20","OfferOrders21","OfferOrders22","OfferOrders23","OfferOrders24","OfferOrders25","OfferOrders26","OfferOrders27","OfferOrders28","OfferOrders29","OfferOrders30","OfferOrders31","OfferOrders32","OfferOrders33","OfferOrders34","OfferOrders35","OfferOrders36","OfferOrders37","OfferOrders38","OfferOrders39","OfferOrders40","OfferOrders41","OfferOrders42","OfferOrders43","OfferOrders44","OfferOrders45","OfferOrders46","OfferOrders47","OfferOrders48","OfferOrders49","NumTrades","IOPV","TotalBidQty","TotalOfferQty","WeightedAvgBidPx","WeightedAvgOfferPx","TotalBidNumber","TotalOfferNumber","BidTradeMaxDuration","OfferTradeMaxDuration","NumBidOrders","NumOfferOrders","WithdrawBuyNumber","WithdrawBuyAmount","WithdrawBuyMoney","WithdrawSellNumber","WithdrawSellAmount","WithdrawSellMoney","ETFBuyNumber","ETFBuyAmount","ETFBuyMoney","ETFSellNumber","ETFSellAmount","ETFSellMoney"]
colType = ["SYMBOL","TIMESTAMP","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","INT","DOUBLE","SYMBOL","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","INT","DOUBLE","DOUBLE","INT","INT","INT","INT","INT","INT","INT","INT","DOUBLE","INT","INT","DOUBLE","INT","INT","INT","INT","INT","INT"]
schemaTable = table(1:0,colName, colType)
db.createPartitionedTable(table=schemaTable, tableName=tbName, partitionColumns=`DateTime`SecurityID, compressMethods={DateTime:"delta"}, sortColumns=`SecurityID`DateTime, keepDuplicates=ALL)
}For snapshot data, composite partitioning scheme is used: first partitioned by day, then split into 50 partitions based on stock code.
Create cleaned snapshot data table with array vectors
module processSnapshot::createSnapshot_array
// Create a table for cleaned snapshot data
def createProcessTable(dbName, tbName){
if(existsDatabase(dbName)){
dropDatabase(dbName)
}
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 50])
// Partitioned by day and stock code
db = database(dbName,COMPO,[db1,db2],engine='TSDB')
colName = ["SecurityID","DateTime","PreClosePx","OpenPx","HighPx","LowPx","LastPx","TotalVolumeTrade","TotalValueTrade","InstrumentStatus","BidPrice","BidOrderQty","BidNumOrders","BidOrders","OfferPrice","OfferOrderQty","OfferNumOrders","OfferOrders","NumTrades","IOPV","TotalBidQty","TotalOfferQty","WeightedAvgBidPx","WeightedAvgOfferPx","TotalBidNumber","TotalOfferNumber","BidTradeMaxDuration","OfferTradeMaxDuration","NumBidOrders","NumOfferOrders","WithdrawBuyNumber","WithdrawBuyAmount","WithdrawBuyMoney","WithdrawSellNumber","WithdrawSellAmount","WithdrawSellMoney","ETFBuyNumber","ETFBuyAmount","ETFBuyMoney","ETFSellNumber","ETFSellAmount","ETFSellMoney"]
colType = ["SYMBOL","TIMESTAMP","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","INT","DOUBLE","SYMBOL","DOUBLE[]","INT[]","INT[]","INT[]","DOUBLE[]","INT[]","INT[]","INT[]","INT","INT","INT","INT","DOUBLE","DOUBLE","INT","INT","INT","INT","INT","INT","INT","INT","DOUBLE","INT","INT","DOUBLE","INT","INT","INT","INT","INT","INT"]
schemaTable = table(1:0, colName, colType)
db.createPartitionedTable(table=schemaTable, tableName=tbName, partitionColumns=`DateTime`SecurityID, compressMethods={DateTime:"delta"}, sortColumns=`SecurityID`DateTime, keepDuplicates=ALL)
}Create 1-minute OHLC data table
module Factor::createFactorOneMinute
// Create the table for 1-minute OHLC
def createFactorOneMinute(dbName, tbName){
if(existsDatabase(dbName)){
dropDatabase(dbName)
}
// Partitioned by day
db = database(dbName, VALUE, 2021.01.01..2021.01.03,engine = `TSDB)
colName = `TradeDate`TradeTime`SecurityID`Open`High`Low`Close`Volume`Amount`Vwap
colType =[DATE, MINUTE, SYMBOL, DOUBLE, DOUBLE, DOUBLE, DOUBLE, LONG, DOUBLE, DOUBLE]
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema,tableName=tbName,partitionColumns=`TradeDate,sortColumns=`SecurityID`TradeTime,keepDuplicates=ALL)
}Create daily OHLC data table
module Factor::createFactorDaily
// Create the table for daily OHLC
def createFactorDaily(dbName, tbName){
if(existsDatabase(dbName)){
dropDatabase(dbName)
}
// Partitioned by year
db = database(dbName, RANGE, datetimeAdd(2000.01M,(0..50)*12, "M"),engine = `TSDB)
colName = `TradeDate`SecurityID`Open`High`Low`Close`Volume`Amount`Vwap
colType =[DATE, SYMBOL, DOUBLE, DOUBLE, DOUBLE, DOUBLE, LONG, DOUBLE, DOUBLE]
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema,tableName=tbName,partitionColumns=`TradeDate,sortColumns=`SecurityID`TradeDate,keepDuplicates=ALL)
}2.3.2 Cleaning Data
Data cleaning scripts primarily involves two steps:
- Convert multi-level price and quantity columns into array vectors.
- Remove duplicate records by SecurityID and DateTime.
The detailed processing logic and core code are as follows:
module processSnapshot::processSnapshotData
// Combine data into array vectors and deduplicate
def mapProcess(mutable t, dbName, tbName){
n1 = t.size()
t = select SecurityID, DateTime, PreClosePx, OpenPx, HighPx, LowPx, LastPx, TotalVolumeTrade, TotalValueTrade, InstrumentStatus, fixedLengthArrayVector(BidPrice0, BidPrice1, BidPrice2, BidPrice3, BidPrice4, BidPrice5, BidPrice6, BidPrice7, BidPrice8, BidPrice9) as BidPrice, fixedLengthArrayVector(BidOrderQty0, BidOrderQty1, BidOrderQty2, BidOrderQty3, BidOrderQty4, BidOrderQty5, BidOrderQty6, BidOrderQty7, BidOrderQty8, BidOrderQty9) as BidOrderQty, fixedLengthArrayVector(BidNumOrders0, BidNumOrders1, BidNumOrders2, BidNumOrders3, BidNumOrders4, BidNumOrders5, BidNumOrders6, BidNumOrders7, BidNumOrders8, BidNumOrders9) as BidNumOrders, fixedLengthArrayVector(BidOrders0, BidOrders1, BidOrders2, BidOrders3, BidOrders4, BidOrders5, BidOrders6, BidOrders7, BidOrders8, BidOrders9, BidOrders10, BidOrders11, BidOrders12, BidOrders13, BidOrders14, BidOrders15, BidOrders16, BidOrders17, BidOrders18, BidOrders19, BidOrders20, BidOrders21, BidOrders22, BidOrders23, BidOrders24, BidOrders25, BidOrders26, BidOrders27, BidOrders28, BidOrders29, BidOrders30, BidOrders31, BidOrders32, BidOrders33, BidOrders34, BidOrders35, BidOrders36, BidOrders37, BidOrders38, BidOrders39, BidOrders40, BidOrders41, BidOrders42, BidOrders43, BidOrders44, BidOrders45, BidOrders46, BidOrders47, BidOrders48, BidOrders49) as BidOrders, fixedLengthArrayVector(OfferPrice0, OfferPrice1, OfferPrice2, OfferPrice3, OfferPrice4, OfferPrice5, OfferPrice6, OfferPrice7, OfferPrice8, OfferPrice9) as OfferPrice, fixedLengthArrayVector(OfferOrderQty0, OfferOrderQty1, OfferOrderQty2, OfferOrderQty3, OfferOrderQty4, OfferOrderQty5, OfferOrderQty6, OfferOrderQty7, OfferOrderQty8, OfferOrderQty9) as OfferQty, fixedLengthArrayVector(OfferNumOrders0, OfferNumOrders1, OfferNumOrders2, OfferNumOrders3, OfferNumOrders4, OfferNumOrders5, OfferNumOrders6, OfferNumOrders7, OfferNumOrders8, OfferNumOrders9) as OfferNumOrders, fixedLengthArrayVector(OfferOrders0, OfferOrders1, OfferOrders2, OfferOrders3, OfferOrders4, OfferOrders5, OfferOrders6, OfferOrders7, OfferOrders8, OfferOrders9, OfferOrders10, OfferOrders11, OfferOrders12, OfferOrders13, OfferOrders14, OfferOrders15, OfferOrders16, OfferOrders17, OfferOrders18, OfferOrders19, OfferOrders20, OfferOrders21, OfferOrders22, OfferOrders23, OfferOrders24, OfferOrders25, OfferOrders26, OfferOrders27, OfferOrders28, OfferOrders29, OfferOrders30, OfferOrders31, OfferOrders32, OfferOrders33, OfferOrders34, OfferOrders35, OfferOrders36, OfferOrders37, OfferOrders38, OfferOrders39, OfferOrders40, OfferOrders41, OfferOrders42, OfferOrders43, OfferOrders44, OfferOrders45, OfferOrders46, OfferOrders47, OfferOrders48, OfferOrders49) as OfferOrders, NumTrades, IOPV, TotalBidQty, TotalOfferQty, WeightedAvgBidPx, WeightedAvgOfferPx, TotalBidNumber, TotalOfferNumber, BidTradeMaxDuration, OfferTradeMaxDuration, NumBidOrders, NumOfferOrders, WithdrawBuyNumber, WithdrawBuyAmount, WithdrawBuyMoney, WithdrawSellNumber, WithdrawSellAmount, WithdrawSellMoney, ETFBuyNumber, ETFBuyAmount, ETFBuyMoney, ETFSellNumber, ETFSellAmount, ETFSellMoney from t where isDuplicated([SecurityID, DateTime], FIRST) = false
n2 = t.size()
loadTable(dbName, tbName).append!(t)
return n1,n2
}
def process(processDate, dbName_orig, tbName_orig, dbName_process, tbName_process){
dataString = temporalFormat(processDate, "yyyyMMdd")
// Check if data for the processing date already exists
todayCount = exec count(*) from loadTable(dbName_process, tbName_process) where date(DateTime)=processDate
// If data exists, delete it first
if(todayCount != 0){
writeLog("Start to delete the process snapshot data, the delete date is: " + dataString)
dropPartition(database(dbName_process), processDate, tbName_process)
writeLog("Successfully deleted the process snapshot data, the delete date is: " + dataString)
}
// Start processing snapshot data
writeLog("Start process Snapshot Data, the datetime is "+ dataString)
ds = sqlDS(sql(select=sqlCol("*"), from=loadTable(dbName_orig,tbName_orig),where=<date(DateTime)=processDate>))
n1,n2=mr(ds, mapProcess{, dbName_process, tbName_process}, +, , false)
if(n1 != n2){
writeLog("ERROR: Duplicated datas exists in " + dataString + ", Successfully drop " + string(n1-n2) + " pieces of data" )
}
writeLog("Successfully process the snapshot data, the processDate is: " + dataString)
}2.3.3 Generating OHLC Data
Generate 1-minute OHLC data
module Factor::calFactorOneMinute
// Generate 1-minute OHLC
def calFactorOneMinute(dbName, tbName, mutable factorTable){
pt = loadTable(dbName, tbName)
// Process in groups of 10 days
dayList = schema(pt).partitionSchema[0]
if(dayList.size()>10) dayList = dayList.cut(10)
for(days in dayList){
// Calculate 1-minute OHLC
res = select first(LastPX) as Open, max(LastPx) as High, min(LastPx) as Low, last(LastPx) as Close, sum(TotalVolumeTrade) as Volume, sum(LastPx*totalVolumeTrade) as Amount, wavg(LastPx, TotalVolumeTrade) as Vwap from pt where date(DateTime) in days group by date(DateTime) as TradeDate,minute(DateTime) as TradeTime, SecurityID
writeLog("Start to append minute factor result , the days is: [" + concat(days, ",")+"]")
// Write OHLC data to database
factorTable.append!(res)
writeLog("Successfully append the minute factor result to databse, the days is: [" + concat(days, ",")+"]")
}
}Generate daily OHLC data
module Factor::calFactorDaily1
// Generate daily OHLC
def calFactorDaily(dbName, tbName, mutable factorTable){
pt = loadTable(dbName, tbName)
// Process in groups of 10 days
dayList = schema(pt).partitionSchema[0]
if(dayList.size()>10) dayList = dayList.cut(10)
for(days in dayList){
// Calculate daily OHLC
res = select first(LastPX) as Open, max(LastPx) as High, min(LastPx) as Low, last(LastPx) as Close, sum(TotalVolumeTrade) as Volume, sum(LastPx*totalVolumeTrade) as Amount, wavg(LastPx, TotalVolumeTrade) as Vwap from pt where date(DateTime) in days group by date(DateTime) as TradeDate, SecurityID
writeLog("Start to append daily factor result , the days is: [" + concat(days, ",")+"]")
// Write OHLC data to database
factorTable.append!(res)
writeLog("Successfully append the daily factor result to databse, the days is: [" + concat(days, ",")+"]")
}
}2.4 Incremental Data Cleaning
The logic for incremental data import is similar to full data processing, with the following key differences:
- Full data is imported in bulk, while incremental data is processed daily on a schedule.
- Full data is imported asynchronously using
submitJob, while incremental data is imported synchronously usingappend!. - Full data generates OHLC data in bulk, while incremental data only generates data for the current day.
See appendix for full scripts.
2.5 DAG Execution
2.5.1 Creating DAG Instances
Full ETL DAG
with DAG(dag_id="ETLTest", start_date=datetime(2023, 3, 10), schedule_interval=None) as dag:dag_iddefines the DAG name and must be unique.start_datesets the start date of the task.schedule_intervalsets the interval between two task executions.Noneindicates the DAG does not execute automatically and must be triggered manually.
Incremental ETL DAG
args = {
"owner" : "Airflow",
"start_date" : days_ago(1),
"catchup" : False,
'retries' : 0
}
with DAG(dag_id="addETLTest", default_args = args, schedule_interval="0 12 * * *") as dag:catchupdetermines whether backfill should be performed.retriesspecifies the number of retries on failure.schedule_interval = "0 12 * * *"means the task runs daily at 12:00 UTC. For detailed schedule settings, see Scheduling & Triggers.
2.5.2 Accessing Variables in Airflow
Variable values set in Airflow cannot be directly accessed in DolphinDB scripts. To use them in subsequent tasks, Airflow variables are written into a shared table, enabling access by DolphinDB tasks. The specific code example is as follows:
// Retrieve variable values
variable = ['ETL_dbName_origin', "ETL_tbName_origin", "ETL_dbName_process",
"ETL_tbName_process", 'ETL_dbName_factor','ETL_tbName_factor','ETL_dbName_factor_daily',
'ETL_tbName_factor_daily',"ETL_filedir", "ETL_start_date","ETL_end_date"]
value = []
for var in variable:
value.append(str(Variable.get(var)))
variables = ",".join(variable)
values = ",".join(value)
// Create a shared table via DolphinDBOperator and write variable values into it
create_parameter_table = DolphinDBOperator(
task_id='create_parameter_table',
dolphindb_conn_id='dolphindb_test',
sql='''
undef(`paramTable,SHARED)
t = table(1:0, `param`value, [STRING, STRING])
share t as paramTable
'''
)
given_param = DolphinDBOperator(
task_id='given_param',
dolphindb_conn_id='dolphindb_test',
sql="params = split('" + variables + "',',');" + \
"values = split('" + values + "',',');" + \
"for(i in 0..(params.size()-1)){" + \
"insert into paramTable values(params[i], values[i]);}"
)After the task runs, the parameter table and its values will appear in the DolphinDB GUI under Shared Tables, as shown in the figure below.
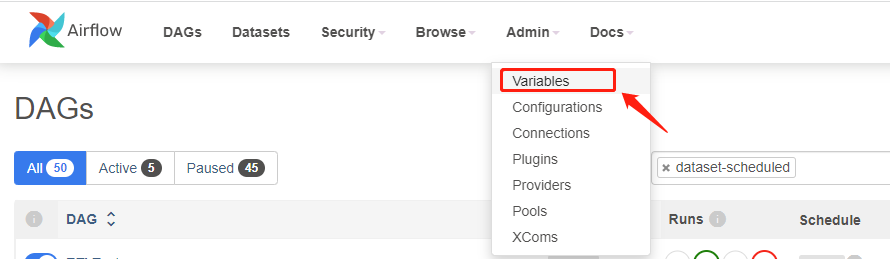
Each DAG variable can be modified in Airflow. Click Admin > Variables in the menu as shown below:
Once the DAG is generated, variables used in the DAG can be dynamically modified on the following web interface, as shown below:
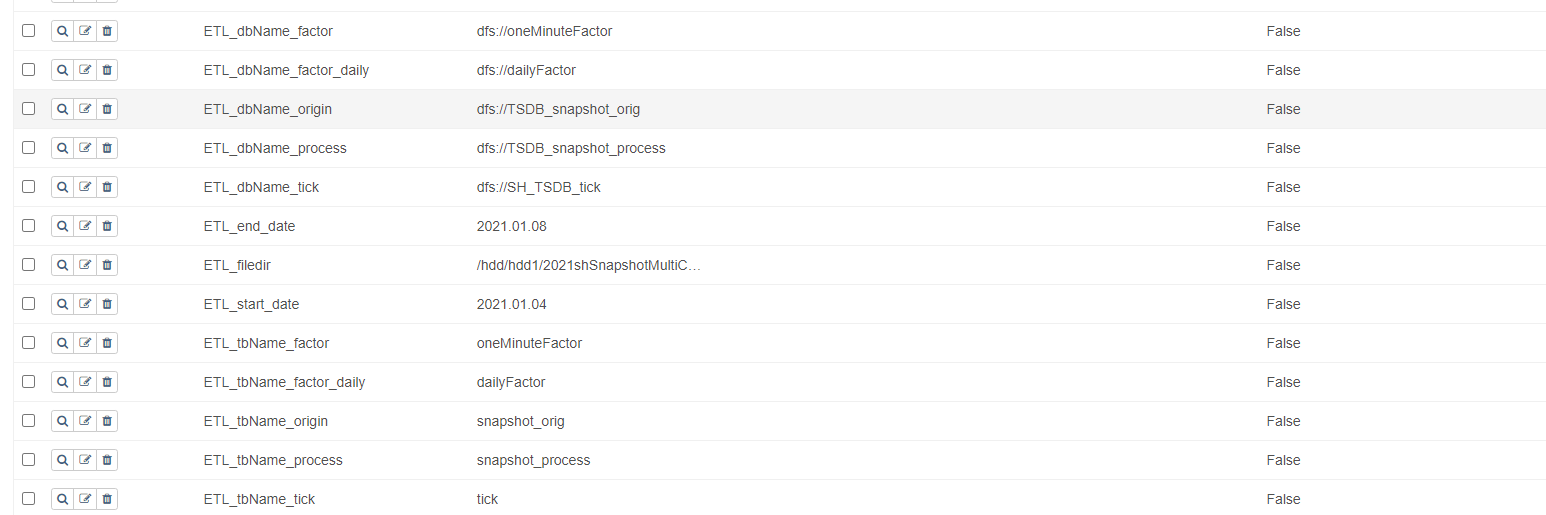
The following table lists the variables used in this project:
| Name | Description | Example |
|---|---|---|
| ETL_dbName_factor | Database name for storing minute-level OHLC | dfs://oneMinuteFactor |
| ETL_tbName_factor | Table name for storing minute-level OHLC | oneMinuteFactor |
| ETL_dbName_factor_daily | Database name for storing daily OHLC | dfs://dailyFactor |
| ETL_tbName_factor_daily | Table name for storing daily OHLC | dailyFactor |
| ETL_dbName_origin | Database name for storing raw snapshot data | dfs://TSDB_snapshot_orig |
| ETL_tbName_origin | Table name for storing raw snapshot data | snapshot_orig |
| ETL_dbName_process | Database name for cleaned snapshot data | dfs://TSDB_snapshot_process |
| ETL_tbName_process | Table name for cleaned snapshot data | snapshot_process |
| ETL_filedir | File path to raw snapshot data | /home/appadmin/ (customized) |
| ETL_start_date | Start date of raw data for full ETL tasks | 2021.01.04 |
| ETL_end_date | End date of raw data for full ETL tasks | 2021.01.04 |
2.5.3 Executing Tasks with DolphinDBOperator
Full Data Processing
Data ingestion, cleaning, and computation can be set as tasks within the DAG using DolphinDBOperator. The core code for full data processing is as follows:
loadSnapshot = DolphinDBOperator(
task_id='loadSnapshot',
dolphindb_conn_id='dolphindb_test',
sql='''
pnodeRun(clearAllCache)
undef(all)
go;
// Use module to load predefined table creation and data loading functions
use loadSnapshot::createSnapshotTable
use loadSnapshot::loadSnapshotData
// Retrieve parameters from the shared table
params = dict(paramTable[`param], paramTable[`value])
dbName = params[`ETL_dbName_origin]
tbName = params[`ETL_tbName_origin]
startDate = date(params[`ETL_start_date])
endDate = date(params[`ETL_end_date])
fileDir = params[`ETL_filedir]
// Create target table if it does not exist
if(not existsDatabase(dbName)){
loadSnapshot::createSnapshotTable::createSnapshot(dbName, tbName)
}
// Start asynchronous data ETL for each date
start = now()
for (loadDate in startDate..endDate){
submitJob("loadSnapshot"+year(loadDate)+monthOfYear(loadDate)+dayOfMonth(loadDate), "loadSnapshot", loadSnapshot::loadSnapshotData::loadSnapshot{, dbName, tbName, fileDir}, loadDate)
}
// Check whether all jobs have completed
do{
cnt = exec count(*) from getRecentJobs() where jobDesc="loadSnapshot" and endTime is null
}
while(cnt != 0)
// Check for any errors during import
cnt = exec count(*) from pnodeRun(getRecentJobs) where jobDesc="loadSnapshot" and errorMsg is not null and receivedTime > start
if (cnt != 0){
error = exec errorMsg from pnodeRun(getRecentJobs) where jobDesc="loadSnapshot" and errorMsg is not null and receivedTime > start
throw error[0]
}
'''
)
processSnapshot = DolphinDBOperator(
task_id='processSnapshot',
dolphindb_conn_id='dolphindb_test',
sql='''
pnodeRun(clearAllCache)
undef(all)
go;
// Use module to load predefined table creation and data loading functions
use processSnapshot::createSnapshot_array
use processSnapshot::processSnapshotData
// Retrieve parameters from the shared table
params = dict(paramTable[`param], paramTable[`value])
dbName_orig = params[`ETL_dbName_origin]
tbName_orig = params[`ETL_tbName_origin]
dbName_process = params[`ETL_dbName_process]
tbName_process = params[`ETL_tbName_process]
startDate = date(params[`ETL_start_date])
endDate = date(params[`ETL_end_date])
// Create target table if it does not exist
if(not existsDatabase(dbName_process)){
processSnapshot::createSnapshot_array::createProcessTable(dbName_process, tbName_process)
}
// Start asynchronous data ETL for each date
start = now()
for (processDate in startDate..endDate){
submitJob("processSnapshot"+year(processDate)+monthOfYear(processDate)+dayOfMonth(processDate), "processSnapshot", processSnapshot::processSnapshotData::process{, dbName_orig, tbName_orig, dbName_process, tbName_process}, processDate)
}
// Check whether all jobs have completed
do{
cnt = exec count(*) from getRecentJobs() where jobDesc="processSnapshot" and endTime is null
}
while(cnt != 0)
// Check for any errors during import
cnt = exec count(*) from pnodeRun(getRecentJobs) where jobDesc="processSnapshot" and errorMsg is not null and receivedTime > start
if (cnt != 0){
error = exec errorMsg from pnodeRun(getRecentJobs) where jobDesc="processSnapshot" and errorMsg is not null and receivedTime > start
throw error[0]
}
'''
)
calMinuteFactor = DolphinDBOperator(
task_id='calMinuteFactor',
dolphindb_conn_id='dolphindb_test',
sql='''
pnodeRun(clearAllCache)
undef(all)
go;
// Use module to load predefined table creation and data loading functions
use Factor::createFactorOneMinute
use Factor::calFactorOneMinute
// Retrieve parameters from the shared table
params = dict(paramTable[`param], paramTable[`value])
dbName = params[`ETL_dbName_process]
tbName = params[`ETL_tbName_process]
dbName_factor = params[`ETL_dbName_factor]
tbName_factor = params[`ETL_tbName_factor]
// Create target table if it does not exist
if(not existsDatabase(dbName_factor)){
createFactorOneMinute(dbName_factor, tbName_factor)
}
factorTable = loadTable(dbName_factor, tbName_factor)
// Invoke the calculation function
calFactorOneMinute(dbName, tbName,factorTable)
'''
)
calDailyFactor = DolphinDBOperator(
task_id='calDailyFactor',
dolphindb_conn_id='dolphindb_test',
sql='''
pnodeRun(clearAllCache)
undef(all)
go;
// Use module to load predefined table creation and data loading functions
use Factor::createFactorDaily
use Factor::calFactorDaily1
// Retrieve parameters from the shared table
params = dict(paramTable[`param], paramTable[`value])
dbName = params[`ETL_dbName_process]
tbName = params[`ETL_tbName_process]
dbName_factor = params[`ETL_dbName_factor_daily]
tbName_factor = params[`ETL_tbName_factor_daily]
// Create target table if it does not exist
if(not existsDatabase(dbName_factor)){
createFactorDaily(dbName_factor, tbName_factor)
}
// Invoke the calculation function
factorTable = loadTable(dbName_factor, tbName_factor)
Factor::calFactorDaily1::calFactorDaily(dbName, tbName,factorTable)
'''
)The DAG is constructed based on the dependencies between tasks, as shown below:
start_task >> create_parameter_table >> given_param >> loadSnapshot >> processSnapshot >> calMinuteFactor >> calDailyFactorIncremental Data Import
The code for constructing tasks for incremental jobs is as follows:
addLoadSnapshot = DolphinDBOperator(
task_id='addLoadSnapshot',
dolphindb_conn_id='dolphindb_test',
sql='''
pnodeRun(clearAllCache)
undef(all)
go;
// Use module to load predefined table creation and data loading functions
use addLoadSnapshot::loadSnapshotData
// Retrieve parameters from the shared table
params = dict(paramTable[`param], paramTable[`value])
dbName = params[`ETL_dbName_origin]
tbName = params[`ETL_tbName_origin]
fileDir = params[`ETL_filedir]
// Get market calendars
MarketDays = getMarketCalendar("CFFEX")
// Import the data for trading days
if(today() in MarketDays ){
fileDir = params[`ETL_filedir]
addLoadSnapshot::loadSnapshotData::loadSnapshot(today(), dbName, tbName, fileDir)
}
'''
)
addProcessSnapshot = DolphinDBOperator(
task_id='addProcessSnapshot',
dolphindb_conn_id='dolphindb_test',
sql='''
pnodeRun(clearAllCache)
undef(all)
go;
// Use module to load data cleaning functions
use addProcessSnapshot::processSnapshotData
// Retrieve parameters from the shared table
params = dict(paramTable[`param], paramTable[`value])
dbName_orig = params[`ETL_dbName_origin]
tbName_orig = params[`ETL_tbName_origin]
dbName_process = params[`ETL_dbName_process]
tbName_process = params[`ETL_tbName_process]
// Get market calendars
MarketDays = getMarketCalendar("CFFEX")
// Process the data for trading days
if(today() in MarketDays ){
addProcessSnapshot::processSnapshotData::process(today(), dbName_orig, tbName_orig, dbName_process, tbName_process)
}
'''
)
addCalMinuteFactor= DolphinDBOperator(
task_id='addCalMinuteFactor',
dolphindb_conn_id='dolphindb_test',
sql='''
pnodeRun(clearAllCache)
undef(all)
go;
// Use module to load calculation functions
use addFactor::calFactorOneMinute
// Retrieve parameters from the shared table
params = dict(paramTable[`param], paramTable[`value])
dbName = params[`ETL_dbName_process]
tbName = params[`ETL_tbName_process]
dbName_factor = params[`ETL_dbName_factor]
tbName_factor = params[`ETL_tbName_factor]
factorTable = loadTable(dbName_factor, tbName_factor)
// Get market calendars
MarketDays = getMarketCalendar("CFFEX")
// Generate OHLC data for trading days
if(today() in MarketDays ){
addFactor::calFactorOneMinute::calFactorOneMinute(dbName, tbName,today(), factorTable)
}
'''
)
addCalDailyFactor= DolphinDBOperator(
task_id='addCalDailyFactor',
dolphindb_conn_id='dolphindb_test',
sql='''
pnodeRun(clearAllCache)
undef(all)
go;
// Use module to load calculation functions
use addFactor::calFactorDaily1
// Retrieve parameters from the shared table
params = dict(paramTable[`param], paramTable[`value])
dbName = params[`ETL_dbName_process]
tbName = params[`ETL_tbName_process]
dbName_factor = params[`ETL_dbName_factor_daily]
tbName_factor = params[`ETL_tbName_factor_daily]
factorTable = loadTable(dbName_factor, tbName_factor)
// Get market calendars
MarketDays = getMarketCalendar("CFFEX")
// Generate OHLC data for trading days
if(today() in MarketDays ){
addFactor::calFactorDaily1::calFactorDaily(dbName, tbName,today(), factorTable)
}
'''
)
The DAG is constructed based on the dependencies between tasks, as shown below:
start_task >> create_parameter_table >> given_param >> addLoadSnapshot >> addProcessSnapshot >> addCalMinuteFactor >> addCalDailyFactor2.5.4. Generating DAGs
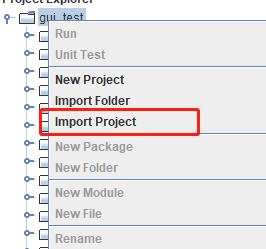
Deploy DolphinDB project
Import the addETL and fullETL projects into the DolphinDB GUI:
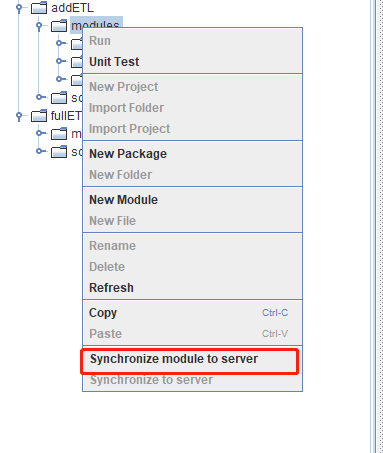
Upload the modules within addETL and fullETL projects to the DolphinDB server already connected in Airflow:
Deploy Python project
Place the Python scripts from the Python project into the
<Airflow_install_Dir/airflow/dags> directory. Note that newly
created DAG tasks will not appear on the interface immediately; by default,
they are refreshed after 5 minutes. You can also adjust the refresh interval
by modifying the dag_dir_list_interval parameter in the
airflow.cfg file.
Import Airflow variables
Go to Admin > Variables in the Airflow web interface, upload the Variables.json file, import the variables into Airflow, and modify their values as appropriate.
Upload raw data files
Upload the data files to the server, and modify the
ETL_filedir variable in Airflow based on the actual
storage path of the data files. When running incremental ETL tasks, the date
in the data file name must be updated to the current date (e.g.,
20230330snapshot.csv) to avoid task failure due to missing data.
The final implemented DAGs are as shown below:


After running the tasks, a green task instance indicates successful execution; red indicates task failure; orange indicates that an upstream task failed, and this task was not executed.
3. FAQs
3.1 How to capture output printed by the print function in DolphinDB scripts
The output of the print function in DolphinDB scripts is
standard output and can be found in airflow-scheduler.out file, as shown
in the figure below:
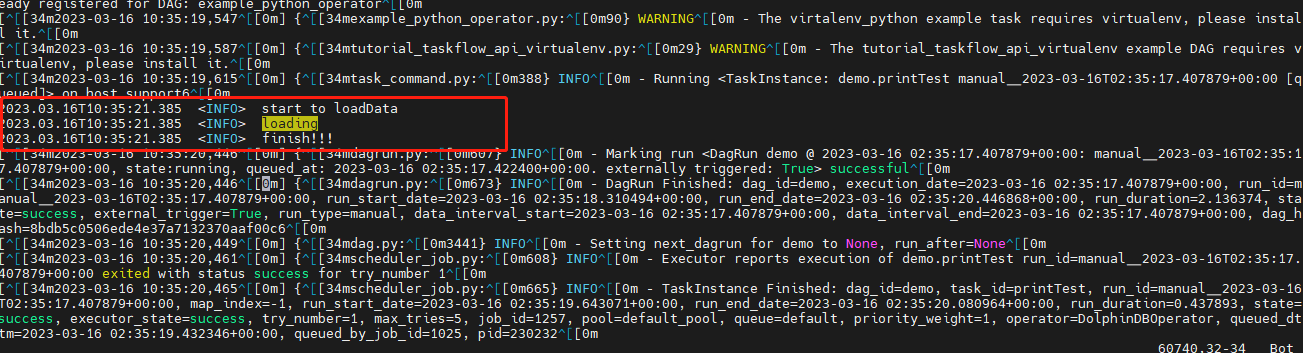
3.2 How to monitor the completion status of asynchronous jobs submitted using submitJob in DolphinDB scripts
You can use the DolphinDB getRecentJobs function to retrieve
background job information, and add conditional logic in the DolphinDB DAG. An
example code snippet is as follows:
DolphinDBOperator(
task_id='processSnapshot',
dolphindb_conn_id='dolphindb_test',
sql='''
// Check whether all tasks are completed
do{
cnt = exec count(*) from getRecentJobs() where jobDesc="processSnapshot" and endTime is null
}
while(cnt != 0)
// Check whether background tasks succeeded; throw exception if failed
cnt = exec count(*) from pnodeRun(getRecentJobs) where jobDesc="processSnapshot" and errorMsg is not null and receivedTime > start
if (cnt != 0){
error = exec errorMsg from pnodeRun(getRecentJobs) where jobDesc="processSnapshot" and errorMsg is not null and receivedTime > start
throw error[0]
}
'''
)3.3 How to handle frequent connection timeouts when running tasks in Airflow
Connection timeouts may result from network instability or high latency. You can set connection parameters during setup. Configure the keepAliveTime and reconnect parameters in the DolphinDB connection settings.
3.4 Why does the task not run on the current day if start_date
is set to today with a daily schedule
In Airflow, scheduled tasks begin execution after the specified
start_date by one full schedule_interval.
For example, if start_date = 2023.03.16 and the task is
scheduled daily, the earliest execution will be on 2023.03.17.
Therefore, the task will not run on the day it is set to start.
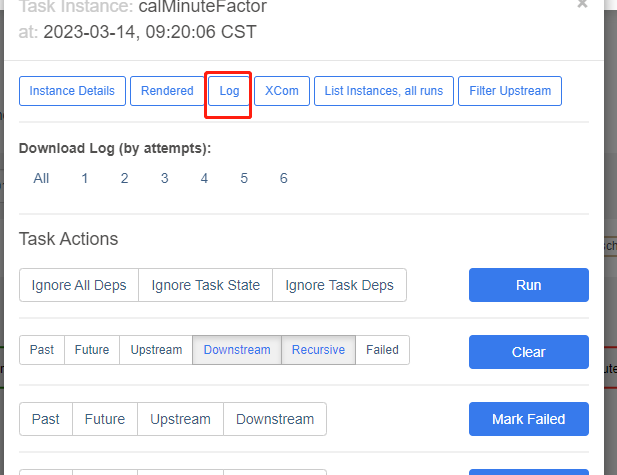
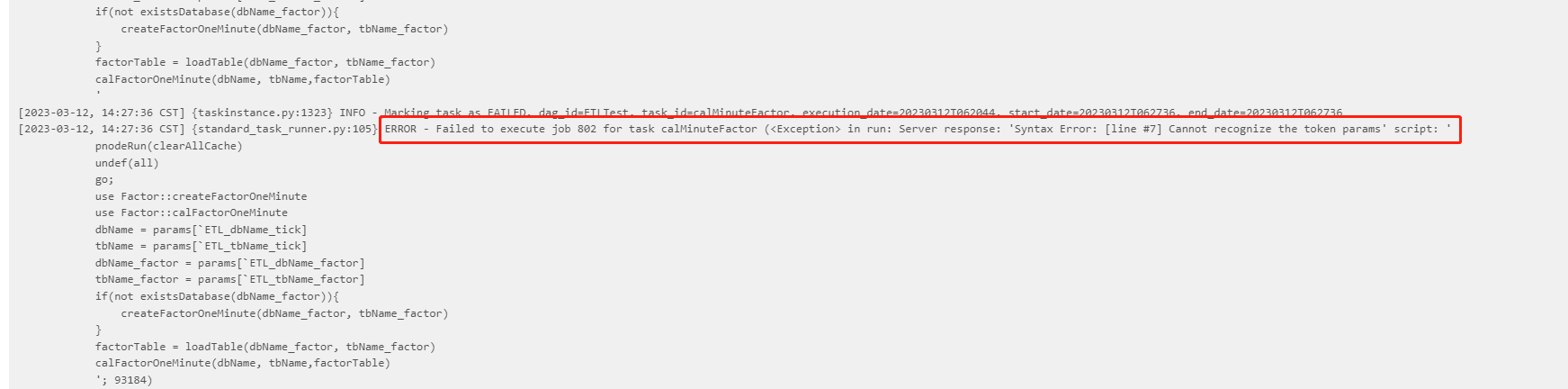
3.5 How to troubleshoot DolphinDBOperator task failures
When a task fails, DolphinDBOperator will print detailed error messages in the logs. You can locate the exception code and modify it by checking the log information. The steps to view the logs are as follows:
Disclaimer
Under the Apache License 2.0, the Airflow-related installation packages and source code involved in this document exist as part of the DolphinDB Airflow plugin.However, the copyright of the Airflow installation packages or source code belongs to the Apache Software Foundation.
Appendix
- DolphinDB projects: DolphinDB_projects.zip
- Python projects: Python_projects.zip
- Data: 20210104snapshot.csv
- Airflow variables: variables.json
- Dependencies: Dependencies.zip