Updating Data in a DFS Table
1. Overview
Starting from version 1.30.6, DolphinDB supports updating data in distributed (also known as “DFS”) tables. These update operations are transactional, adhering to the ACID properties and achieving snapshot isolation through MVCC (Multi-Version Concurrency Control). As a multi-modal database, DolphinDB offers different storage engines. This article will explain the principles behind update operations for both the OLAP and TSDB storage engines, and will also provide experimental validation and performance analysis.
2. Usage
We can use the following 3 methods to modify DFS table data:
- Using standard SQL UPDATE syntax;
- Using
sqlUpdate, which dynamically generates meta code for SQL update statements. The generated meta code is then executed using theevalfunction. For details, refer to the SQL metaprogramming documentation; - Using
upsert!, which updates existing records if the primary key already exists; otherwise, it inserts new records.
The following is a simple example demonstrating all three methods:
- Use the UPDATE SQL statement and the
sqlUpdatefunction to update the “vol” column for all rows whereID = 1; - Use
upsert!to update the “dat”e and “vol” columns of the first row whereID = 1.
Step 1: Use the attached script to create the database and table.
Step 2: Update the data using the following methods:
Method 1: The following SQL statement updates the vol value to 1 for all records
where ID = 1:
update pt set vol = 1 where ID = 1Method 2: sqlUpdate updates the vol value to 2 for all records where
ID = 1:
sqlUpdate(pt, <2 as vol>, where=<ID = 1>).eval()Method 3: upsert! updates the date to 2022.08.07 and the vol to 3
for the first record where ID = 1:
newData = table(1 as ID, 2022.08.07 as date, 3 as vol)
upsert!(pt, newData, keyColNames=`ID)3. Overview of the Storage Mechanism
Before diving into the principles of update operations, it's important to understand the basics of DolphinDB's storage mechanism.
DolphinDB comes with a built-in Distributed File System (DFS), which centrally manages storage space across all nodes. When datasets are partitioned, DFS enables global optimization to avoid issues such as uneven data distribution. By leveraging DFS, the storage directories on different data nodes within a cluster are organized into a unified, logical, hierarchical shared file system. For more details on partitioned databases, refer to Data Partitioning.
DolphinDB provides a configuration parameter called volumes, which allows
users to specify storage paths for data files on each node. You can use the command
pnodeRun(getAllStorages) to query the configured paths.
3.1. OLAP Engine Storage
In the OLAP storage engine, each table partition stores each column’s data
in a separate file. For example, in the pt table created with the OLAP engine in
Section 2, the data files for the partition [0, 50) are stored
at the path:
<volumes>/CHUNKS/db1/0_50/gA/pt_2where:
db1is the database name;0_50represents the range partition[0, 50);gAis the physical table name index, introduced in versions 1.30.16/2.00.4 to support table-level partitioning;pt_2is the version folder for table pt, where_2indicates the table’s internal index within the database.
You can navigate to the database directory and use the tree
command to view the structure of the table’s data files. For example:
$ tree
.
├── 0_50
│ └── gA
│ └── pt_2
│ ├── date.col
│ ├── ID.col
│ └── vol.col
├── 50_100
│ └── gA
│ └── pt_2
│ ├── date.col
│ ├── ID.col
│ └── vol.col
├── dolphindb.lock
├── domain
└── pt.tbl
6 directories, 9 files3.2 TSDB Engine
The TSDB engine uses a Log-Structured Merge Tree (LSM Tree) architecture to store
table data. For example, in the pt1 table created with the TSDB engine in
Section 2, the data files for the partition [0, 50) are stored
at the path:
<volumes>/CHUNKS/TSDB_db1/0_50/gE/pt1_2The directory structure is similar to that of the OLAP engine.
By navigating to the database directory and running the tree
command, you can view the level files for the pt1 table, which are the tiered
data files used in the LSM tree. In the example below, the number before the
underscore in the file name indicates the level. Currently, up to four levels
are supported:
$ tree
.
├── 0_50
│ └── gE
│ ├── chunk.dict
│ └── pt1_2
│ └── 0_00000623
├── 50_100
│ └── gE
│ ├── chunk.dict
│ └── pt1_2
│ └── 0_00000624
├── dolphindb.lock
├── domainIf the level files are not generated promptly, we can run
flushTSDBCache() to force the TSDB engine to flush
completed transactions from the buffer to disk.
4 Principles of Data Updates
This section explains the fundamental principles behind updating data in DFS tables using the OLAP and TSDB storage engines.
4.1 OLAP Storage Engine
Update Process
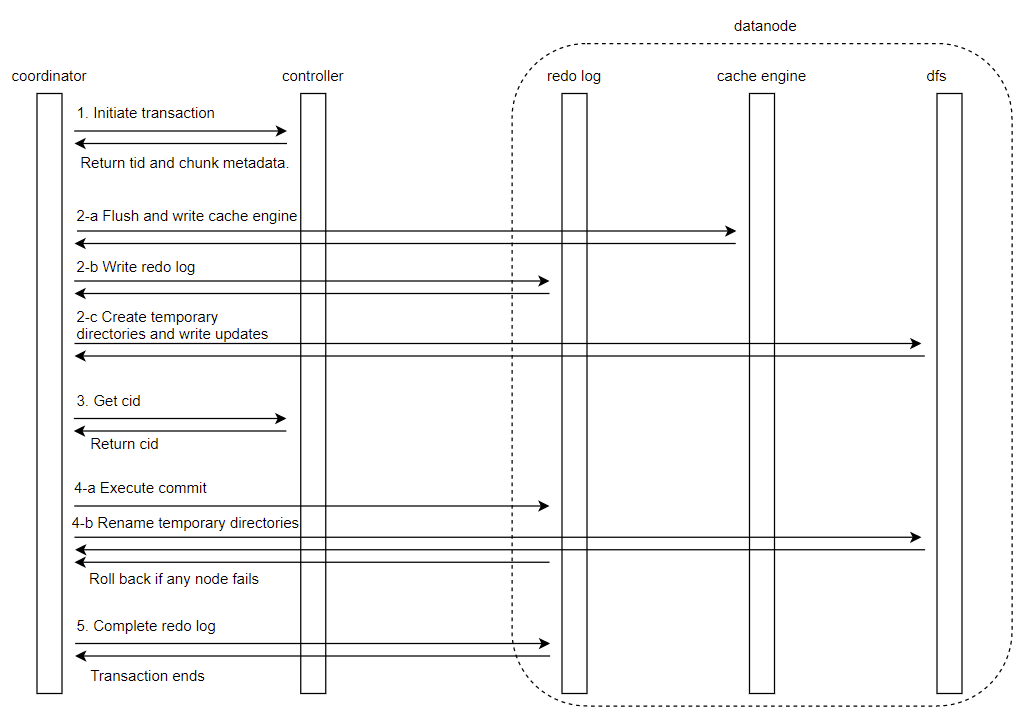
The update process for DFS tables is transactional and follows a two-phase commit (2PC) protocol combined with MVCC. The steps for updating data in the OLAP engine are as follows:
- Start Transaction: The coordinator node requests a transaction ID from the controller, which locks the relevant partitions and chunk metadata.
- Prepare Updates: The preparation process depends on cache engine
status.
With cache engine enabled:
- Flush all completed transaction data from cache to disk
- Write the update to the redo log
- Create temporary directories (using the format
physicalDir_tid_<tidValue>) on relevant data nodes and write updated data. For unchanged columns, the system creates hard links to original files (or copies files if hard links or related mechanisms aren't supported by the file system).
Without cache engine
Skip cache operations and proceed directly to creating temporary directories
- Get Commit ID: The controller assigns a unique, incrementally
increasing Commit ID (cid) to identify this transaction. Each table uses a
createCidsarray to record the cids. - Execute Commit: All participating nodes commit simultaneously:
- Write and flush commit redo logs to disk
- Rename temporary directories to
physicalDir_<cid>
-
Complete Transaction and Clean Up: Participants receive completion notification and write completion logs. The coordinator marks the transaction as finished regardless of individual node success—any failures are handled by the recovery mechanism.
After transaction completion, only the latest partition chunk version remains active. Previous versions become historical data that gets cleaned up on system restart.
For more information on the 2PC process, see Distributed Transaction.
Periodic Garbage Collection Mechanism
In practical use, users frequently perform data updates, leading to a continuous increase in the number of directory versions. To manage this growth, the system implements a periodic garbage collection mechanism. By default, it reclaims directories created by updates older than a specified time interval, executing this process every 60 seconds. Before starting garbage collection, the system retains up to five recent versions of updates.
Snapshot Isolation Level
Each data update is processed as a transaction, adhering to ACID principles. The
system employs Multi-Version Concurrency Control (MVCC) to isolate read and
write operations, ensuring updates do not interfere with active reads. For
instance, when multiple users update and query the same table concurrently, the
system assigns a cid to each operation based on execution order. It then
compares the cid with the version numbers in the createCids
array to identify the highest version that is less than the given cid. The
corresponding file path is used for that operation. To retrieve the latest cid,
you can call the getTabletsMeta().createCids command.
4.2 TSDB Storage Engine Update Mechanism
Table Creation Parameters
The TSDB engine provides two additional parameters during table creation: sortColumns and keepDuplicates.
- sortColumns: Specifies the columns used for sorting the table. By default, all columns except the last one in sortColumns serve as sorting index columns. The combination of these index columns is referred to as the sortKey. As of version 2.00.8, the TSDB engine supports updates to columns listed in sortColumns.
- keepDuplicates: Controls deduplication behavior by specifying how to handle records with identical sortColumns values within each partition. The default value is “ALL”, which retains all records. Setting it to “LAST” keeps only the most recent record, while “FIRST” retains only the first.
Update Strategy
The update strategy varies depending on the value of keepDuplicates.
Update Flow with keepDuplicates=LAST
In this case, updates are essentially append operations to the in-memory buffer of the LSM tree. These records are eventually persisted to level 0 files in the storage hierarchy, meaning no new version directories are created. MVCC is implemented by adding a cid column to the LSM tree. During queries, the TSDB engine filters the data to return only the most recent records.
When the volume of writes reaches a certain threshold or after a period of time,
the system automatically merges level files to conserve disk space. You can also
manually trigger it by calling triggerTSDBCompaction, which
forces the merge of all level-0 files within a specified chunk.
The update flow is illustrated in the following diagram:
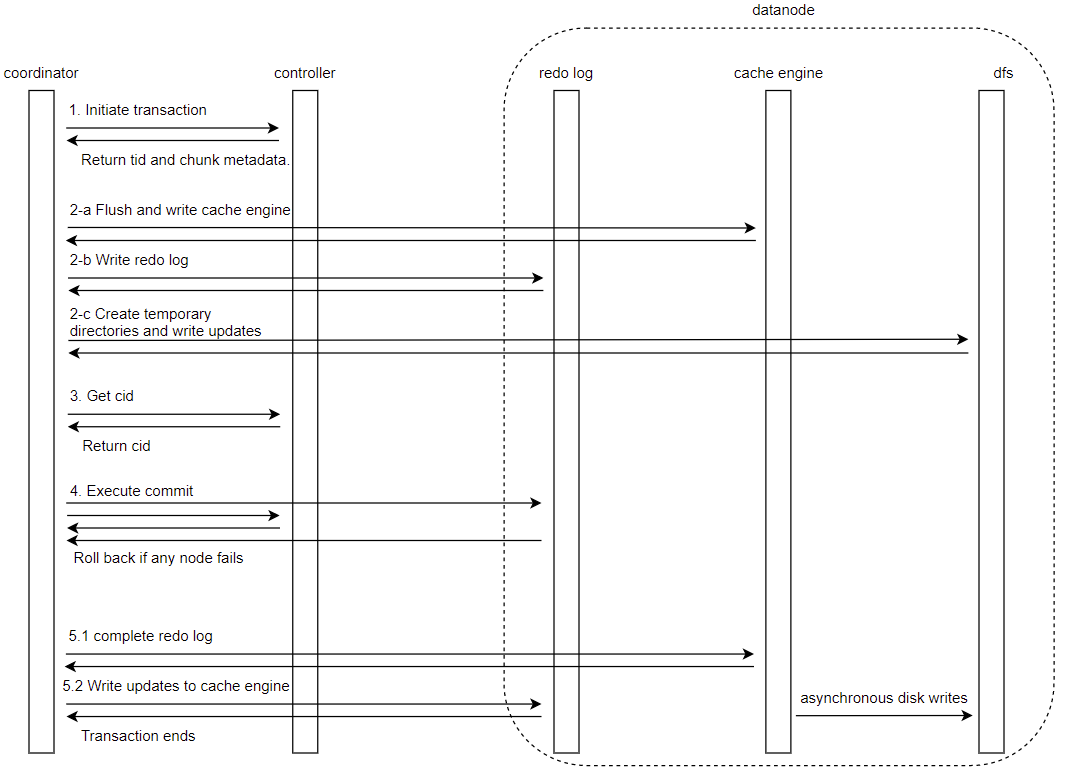
- Start Transaction: The coordinator node requests a transaction ID from the controller, which locks the relevant partitions and returns the transaction metadata.
- Cache Engine Processing: The TSDB engine requires an enabled cache
engine. The system then:
- Flush all completed transaction data from cache to disk
- Write the update to the redo log
- Loads only the necessary portions of level files into memory for modification
- Get Commit ID: The controller assigns a unique, incrementally
increasing Commit ID (cid) to identify this transaction. Each table uses a
createCidsarray to record the cids. - Transaction Commit: All participants receive commit notification and write commit redo logs to persistent storage.
- Transaction Completion:
The system writes completion logs and transfers updated data to the cache engine, where background threads asynchronously persist the changes to disk.
Update Flow with keepDuplicates = FIRST or
keepDuplicates = ALL
When using these settings, the update process mirrors OLAP systems with two-phase commit protocol. Each partition update creates an independent directory, maintaining full ACID compliance and snapshot isolation through MVCC. The mechanism for cleaning up obsolete versions is also the same as in OLAP.
However, there is a key difference in Step 2-c. Unlike the
keepDuplicates = LAST strategy, these modes require reading
and updating all files within the partition—including unchanged columns.
The updated level file metadata is then written back to the table's
metadata.
Therefore, since the entire partition must fit in memory during updates, ensure partition sizes are appropriately sized for available memory to avoid out-of-memory errors.
5 Data Update Experiments in OLAP and TSDB
In this section, we conduct experiments to verify the basic principles of data updates and compare the performance characteristics of OLAP and TSDB engines in common scenarios.
5.1 Experiment Setup
- Operating System: Linux
- DolphinDB Version: v2.00.7
- Single-machine cluster with 1 controller and 1 data node
- Single SSD drive with a speed of 6 Gbps, using the XFS file system
- Cache engine and redo log enabled
Data Simulation
This experiment simulates 5 days of data from 100 machines. Each machine generates 86,400 records per day, resulting in a total of 43,200,000 records over 5 days. The basic information and database names for both the OLAP and TSDB engines are shown below:
| Metric | OLAP | TSDB |
|---|---|---|
| Disk Usage | 8.3 GB | 8.3 GB |
| Partition Size | 169 MB | 170 MB |
| Database Name | olapDemo | tsdbDemo |
Database Creation
The goal of this experiment is to observe changes in the data directory and files before and after executing an UPDATE statement and verify whether these changes align with the theoretical principles described earlier.
For each storage engine, we create a multi-value model database table and populate with simulated IoT data. The appendix contains a comprehensive script demonstrating the creation of the required database and table using the OLAP engine, along with code for test data simulation, insertion procedures, and asynchronous job submission.
Since the script implements asynchronous write operations, you can use the
getRecentJobs function to check whether the writing process
has completed.
The following excerpt shows the createDatabase function from the
provided script:
def createDatabase(dbName,tableName, ps1, ps2, numMetrics){
m = "tag" + string(1..numMetrics)
schema = table(1:0,`id`datetime join m, [INT,DATETIME] join take(FLOAT,50) )
db1 = database("",VALUE,ps1)
db2 = database("",RANGE,ps2)
db = database(dbName,COMPO,[db1,db2])
db.createPartitionedTable(schema,tableName,`datetime`id)
}5.2 OLAP Engine Update Experiment
- Before the Update
First, navigate to the directory containing the data to be updated. By default, this is located at:
<HomeDir>/<nodeAlias>/storage/CHUNKS/olapDemo/20200901/1_11/2Here, the final
2represents the table’s physical name index. Use thetreecommand to inspect the column files of themachinestable:$ tree . └── 2 └── machines_2 ├── datetime.col ├── id.col ├── tag10.col ├── tag11.col ... └── tag9.col - Performing the Update
In the DolphinDB GUI, run the following script to perform 20 update operations on the partition
1_11under date20200901:machines = loadTable("dfs://olapDemo", "machines") for(i in 0..20) update machines set tag1=i,tag5=i where id in 1..5,date(datetime)=2020.09.01During the update, using the
llcommand reveals that temporary directories with the prefixtidhave been generated:$ ll total 20 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_115 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_116 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_117 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_118 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_119 drwxrwxr-x 2 dolphindb dolphindb 120 Sep 7 05:26 machines_2_tid_120 - After the Update
After the update, if the system has not yet triggered periodic cleanup of old versions, you’ll notice that only five versions are retained:
$ ll total 20 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_121 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_122 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_123 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_124 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_125Before the cleanup kicks in, you can examine the contents of the updated version using
ll. You'll observe that only the updated columns tag1 and tag5 have a link count of 1, while the others have a link count of 5, indicating they are hard links. This is because only tag1 and tag5 were modified—DolphinDB reused the unchanged columns by creating hard links to the existing files:$ ll machines_2_125/ total 169632 -rw-rw-r-- 5 dolphindb dolphindb 3469846 Sep 7 05:15 datetime.col -rw-rw-r-- 5 dolphindb dolphindb 14526 Sep 7 05:15 id.col -rw-rw-r-- 5 dolphindb dolphindb 3469845 Sep 7 05:15 tag10.col -rw-rw-r-- 5 dolphindb dolphindb 3469846 Sep 7 05:15 tag11.col ... -rw-rw-r-- 1 dolphindb dolphindb 1742158 Sep 7 05:26 tag1.col ... -rw-rw-r-- 1 dolphindb dolphindb 1742158 Sep 7 05:26 tag5.col ...After some time, only the most recent version remains. This is because the system performs periodic cleanup and retains only the latest snapshot:
$ ll total 4 drwxrwxr-x 2 dolphindb dolphindb 4096 Sep 7 05:26 machines_2_125
5.3 TSDB Engine Update Experiment
Case 1. keepDuplicates = LAST
When implementing the TSDB engine experiment, several modifications to the
provided script's createDatabase function are required.
Specifically, the storage engine parameter must be set to TSDB, and the
keepDuplicates parameter within the
createPartitionedTable function should be configured to
LAST.
def createDatabase(dbName,tableName, ps1, ps2, numMetrics){
m = "tag" + string(1..numMetrics)
schema = table(1:0,`id`datetime join m, [INT,DATETIME] join take(FLOAT,numMetrics) )
db1 = database("",VALUE,ps1)
db2 = database("",RANGE,ps2)
db = database(dbName,COMPO,[db1,db2],,'TSDB')
db.createPartitionedTable(schema,tableName,`datetime`id ,,`id`datetime, keepDuplicates=LAST)
}Before the Update
Start by setting the keepDuplicates parameter of
createPartitionedTable to LAST, then create the database
and import the data.
Navigate to the directory containing the data to be updated. By default, it's located at:
<HomeDir>/<nodeAlias>/storage/CHUNKS/tsdbDemo/20200901/1_11/SHere, S refers to the physical name index of the table. Use the
tree command to check the level files in the machines
table:
$ tree
.
├── chunk.dict
└── machines_2
├── 0_00000010
├── 0_00000011
├── 0_00000012
├── 0_00000013
├── 0_00000014
└── 1_00000002
1 directory, 7 filesDuring the Update
Execute the following script in the GUI to perform 20 updates on the partition
1_11 under date 20200901:
machines = loadTable("dfs://tsdbDemo", "machines")
for(i in 0..20)
update machines set tag1=i,tag5=i where id in 1..5,date(datetime)=2020.09.01During or after the update, use the tree command to inspect the
directory. You’ll notice that no temporary directories are created, but the
number of level files under machines_2 increases. This indicates that with
keepDuplicates = LAST, updates behave like data
appends:
$ tree
.
├── chunk.dict
└── machines_2
├── 0_00000010
├── 0_00000011
├── 0_00000012
├── 0_00000013
├── 0_00000014
├── 0_00000241
├── 0_00000243
...
├── 1_00000002
├── 1_00000050
└── 1_00000051
1 directory, 21 filesAfter the Update
After some time, the system automatically compacts the level files, removing redundant data from the update process. The number of files drops from 20 to 6:
Case 2: keepDuplicates = ALL
Before the Update
Set keepDuplicates to ALL in createPartitionedTable, then
create the database and import the data.
Check the level files of the machines table:
$ tree
.
├── chunk.dict
└── machines_2
├── 0_00000273
├── 0_00000275
├── 0_00000277
├── 0_00000278
├── 0_00000279
└── 1_00000054
1 directory, 7 files
During the Update
During the update, you can see that a temporary directory (with a name containing
tid) is created:
$ tree
.
├── chunk.dict
├── machines_2
│ ├── 0_00000273
│ ├── 0_00000275
│ ├── 0_00000277
│ ├── 0_00000278
│ ├── 0_00000279
│ └── 1_00000054
└── machines_2_tid_199
├── 0_00000515
├── 0_00000516
├── 0_00000517
├── 0_00000518
└── 0_00000519
After the Update
If the system has not yet performed periodic cleanup, you'll find five versions of updated data retained:
$ tree
.
├── chunk.dict
├── machines_2_215
│ ├── 0_00000595
│ ├── 0_00000596
│ ├── 0_00000597
│ ├── 0_00000598
│ └── 0_00000599
├── machines_2_216
│ ├── 0_00000600
│ ├── 0_00000601
│ ├── 0_00000602
│ ├── 0_00000603
│ └── 0_00000604
├── machines_2_217
│ ├── 0_00000605
│ ├── 0_00000606
│ ├── 0_00000607
│ ├── 0_00000608
│ └── 0_00000609
├── machines_2_218
│ ├── 0_00000610
│ ├── 0_00000611
│ ├── 0_00000612
│ ├── 0_00000613
│ └── 0_00000614
└── machines_2_219
├── 0_00000615
├── 0_00000616
├── 0_00000617
├── 0_00000618
└── 0_00000619
Before cleanup, use ll to inspect the updated level files. All
of them have a link count of 1, meaning no hard links were created:
$ ll machines_2_219
total 284764
-rw-rw-r-- 1 dolphindb dolphindb 57151251 Sep 7 05:48 0_00000615
-rw-rw-r-- 1 dolphindb dolphindb 57151818 Sep 7 05:48 0_00000616
-rw-rw-r-- 1 dolphindb dolphindb 58317419 Sep 7 05:48 0_00000617
-rw-rw-r-- 1 dolphindb dolphindb 59486006 Sep 7 05:48 0_00000618
-rw-rw-r-- 1 dolphindb dolphindb 59482644 Sep 7 05:48 0_00000619
Eventually, the system retains only the latest version after cleanup:
$ tree
.
├── chunk.dict
└── machines_2_219
├── 0_00000615
├── 0_00000616
├── 0_00000617
├── 0_00000618
└── 0_00000619
1 directory, 6 files
Case 3: keepDuplicates = FIRST
When keepDuplicates is set to FIRST, the behavior during updates is the same as when it is set to ALL.
6 Performaush all completed transaction data from cachnce Analysis
Based on the previous experiments, we evaluated the update performance by repeatedly executing the update scripts and measuring their execution times.
To update 2 columns of a single record, we used the following script:
machines = loadTable("dfs://olapDemo", "machines")
timer update machines set tag1=1, tag5=5 where id=1 and datetime=2020.09.01T00:00:00To update 2 columns of 8,640,000 records (432,000 records * 20 iterations) from
subpartition 1_11 under partition 20200901, we
used:
machines = loadTable("dfs://olapDemo", "machines")
timer{
for(i in 0..20)
update machines set tag1=i,tag5=i where id in 1..5,date(datetime)=2020.09.01
}To update 20 columns of the same 8,640,000 records, we used:
machines = loadTable("dfs://olapDemo", "machines")
timer{
for(i in 0..20)
update machines set tag1=i,tag2=i,tag3=i,tag4=i,tag5=i,tag6=i,tag7=i,tag8=i,tag9=i,tag10=i,tag11=i,tag12=i,tag13=i,tag14=i,tag15=i,tag16=i,tag17=i,tag18=i,tag19=i,tag20=i where id in 1..5,date(datetime)=2020.09.01
}The measured execution times for each update scenario are summarized below:
| Configuration | 1st Run (ms) | 2nd Run (ms) | 3rd Run (ms) |
|---|---|---|---|
| OLAP | |||
| Update 2 columns of 1 record | 131.263 | 135.649 | 150.013 |
| Update 2 columns of 8.64M rows | 1,389.31 | 1,414.918 | 1,331.718 |
| Update 20 columns of 8.64M rows | 6,309.484 | 5,800.256 | 5,511.421 |
| TSDB (keepDuplicates=LAST) | |||
| Update 2 columns of 1 record | 29.745 | 31.686 | 29.333 |
| Insert 1 record | 10.002 | 12.259 | 10.14 |
| Update 2 columns of 8.64M rows | 19,358.699 | 21,832.69 | 19,686.798 |
| Update 20 columns of 8.64M rows | 20,782.819 | 22,750.596 | 20,643.41 |
| Insert 8.64M rows | 10,813.92 | 9,506.557 | 12,695.168 |
| TSDB (keepDuplicates=ALL) | |||
| Update 20 columns of 8.64M rows | 69,385.771 | 70,563.928 | 62,621.552 |
| TSDB (keepDuplicates=FIRST) | |||
| Update 20 columns of 8.64M rows | 57,614.807 | 65,081.804 | 58,425.8 |
Observations
- OLAP Engine:
Update performance is closely related to the number of columns being updated. Internally, DolphinDB regenerates only the updated columns while using hard links for the untouched ones. As a result, updating 20 columns takes significantly longer than updating just 2.
- TSDB Engine with
keepDuplicates=LAST:This configuration yields better performance compared to ALL or FIRST modes because updates are appended to the LSM tree, which excels at high-throughput writes. Updates are still 2–3 times slower than inserts due to the additional step of reading existing data into memory before updating, whereas inserts do not require this.
- TSDB Engine with
keepDuplicates=ALLorFIRST:These configurations perform poorly in updates because every update creates a new version in a new directory, even for unchanged columns. This results in high disk I/O and consequently lower performance.
In conclusion, DolphinDB TSDB engine is more suitable for scenarios with
low-frequency updates. If using the TSDB engine and update performance is critical,
it is recommended to configure keepDuplicates=LAST.
7 Conclusion
This article compares the usage and underlying principles of updating distributed tables with the OLAP and TSDB storage engines. It validates these principles through experiments and analyzes performance issues in common scenarios.
The update performance of the OLAP engine is affected by the number of columns being
updated and whether the operating system supports hard links. For the TSDB engine,
update performance is closely related to the keepDuplicates parameter—setting
keepDuplicates=LAST provides significantly better performance
than using ALL or FIRST.
In practice, choosing between OLAP and TSDB should be based on the specific application scenario and performance requirements. For more detailed information, see:
For details on the functions mentioned throughout the sections above, refer to the Functions section.