TSDB Storage Engine
TSDB is a storage engine based on the LSM-Tree (Log Structured Merge Tree) model. TSDB is optimized for handling time-series data, providing improved performance and efficiency in data storage, retrieval, and analysis.
Design
LSM-Tree
The LSM-tree is an ordered data storage structure primarily used in write-intensive applications. It optimizes both read and write operations using a combination of in-memory and disk-based structures. LSM-tree provides high write throughput and efficient space utilization through compaction.
Sort Columns
Sort columns (specified by the sortColumns parameter of function
createPartitionedTable) are a unique structure specific to
the TSDB engine, playing a crucial role in the storage and retrieval processes.
Sort columns are used to sort data. Data for each write is sorted based onsort
columns before being written to the disk, ensuring data within transactions and
level files is ordered. Note that there is no guaranteed order between different
level files or within a single partition.
This storage structure facilitates efficient query indexing and data deduplication.
Query Indexing - Sort Key
In DolphinDB, a sort key functions as an index to facilitate querying. When multiple sort columns are specified, the last must be either a temporal column or an integer column and all other columns form the sort key. If there is only one sort column, that column becomes the sort key.
Records sharing the same sort key are sorted by timestamp and stored together in blocks. These blocks are the basic units for querying and compression. Maintaining sort key metadata (e.g., block offset) allows queries to quickly locate relevant blocks, enabling efficient access. This enhances retrieval speed, especially for range queries on sort key or exact matches on the first sort column.
Data Deduplication
TSDB implements data deduplication primarily to handle cases where records with identical sortColumns values are encountered. Deduplication takes place during data writing or level file compaction.
The deduplication policy is controlled by the keepDuplicates parameter (set during table creation) with three options: ALL, LAST, and FIRST.
The TSDB deduplication policy prevents duplicate results, but doesn't eliminate redundant data on disk. When a query is executed, the system reads the relevant data blocks from level files based on the sort key. It then deduplicates this data in memory before returning the final result.
Storage Structure
The following figure illustrates the storage structure of the TSDB engine. It adopts an LSM-Tree structure, comprising two parts: memory and disk.
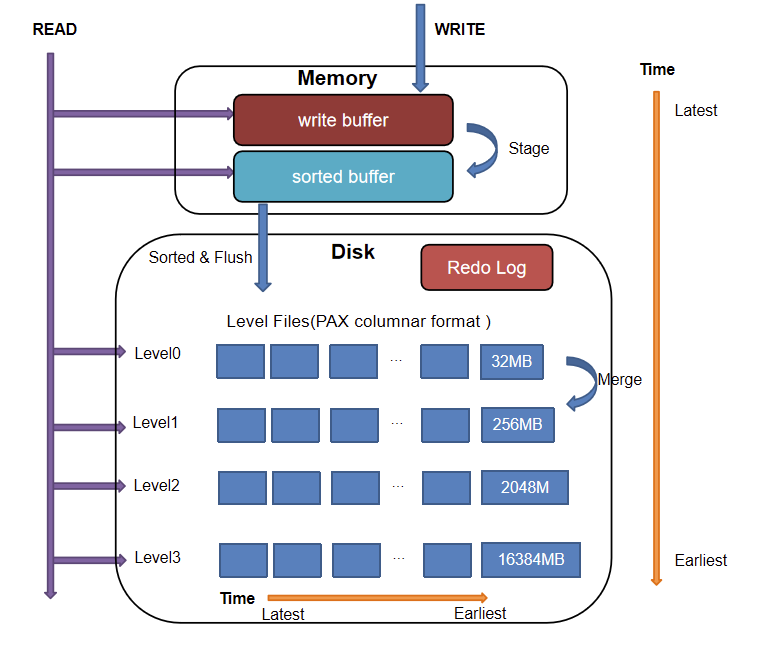
Cache Engine
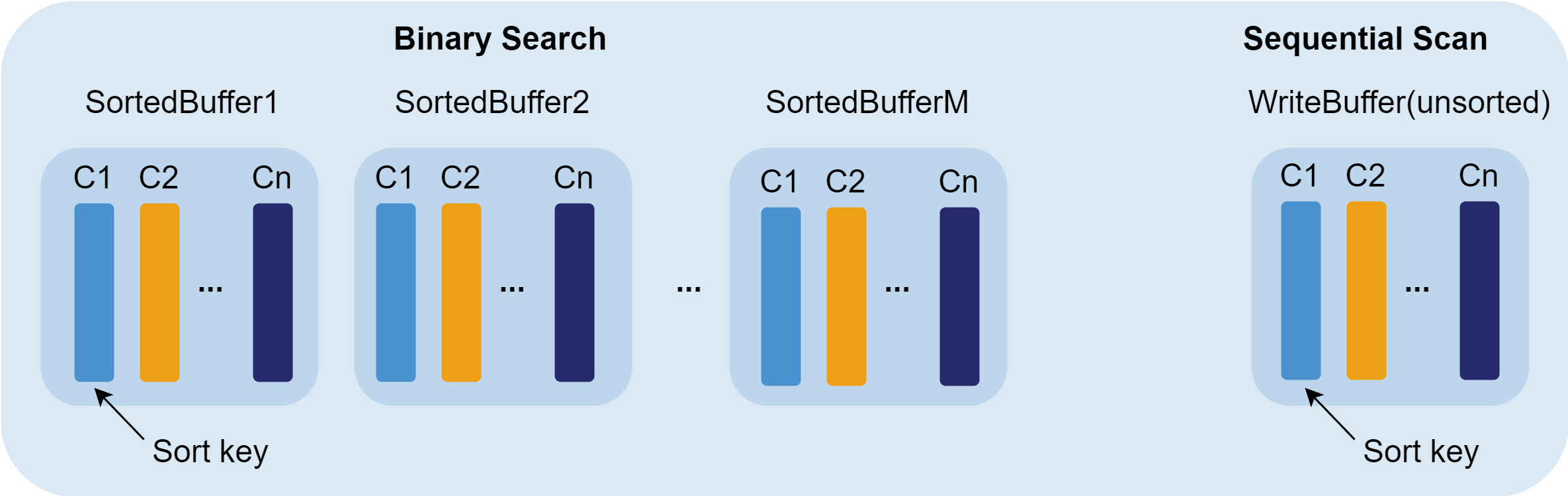
- Write Buffer (unsorted): Receives newly written data.
- Sorted Buffer: After the unsorted write buffer reaches a threshold, it is converted into a read-only sorted buffer with its data sorted according to the specified sortColumns.
Redo Log
The redo log is a type of log file used to record database transactions, capturing all changes made to the database. It primarily serves to ensure the atomicity and durability of transactions. In the TSDB engine, data is first written to the redo log as separate redo log files.
Metadata is data that provides information about other data, including information such as database structure, table definitions, constraints on data, indexes, and other database objects. Although metadata does not directly log transactions, it is typically stored in meta.log to ensure that the database can be restructured during recovery.
Level File
Level File Structure
After multiple sorted write buffers are created and their total size reaches a threshold, data in all the sorted write buffers is written to level files on disk. The Partition Attributes Across (PAX) layout is used: records are first sorted by the sort key entry and records with the same sort key are stored with column files. Each column's data is divided into multiple blocks, and the addresses of these blocks along with their corresponding sort key information are recorded at the end of the level file. A block is the smallest unit for query and compression, with its internal data sorted in the order of the last column. The structure of a level file is as follows:

- Header: Contains reserved fields, table structure details, and transaction-related information.
- Sorted Col Data: Data is sorted by the sort key entry, where each sort key column sequentially stores the block data.
- Zonemap: Stores pre-aggregated information for the data, including the minimum, maximum, sum, and not-null count for each column.
- Indexes: Contains index information for the sorted col data, such as the number of sort key entries, the record count for each sort key entry, the file offset for data in blocks, checksums, etc.
- Footer: Stores the starting position of the zonemap, enabling the system to locate the pre-aggregation and indexing regions.
Zonemap and indexes are loaded into the memory during query operations for indexing purposes.
Level File Levels
The organization of level files is as follows:
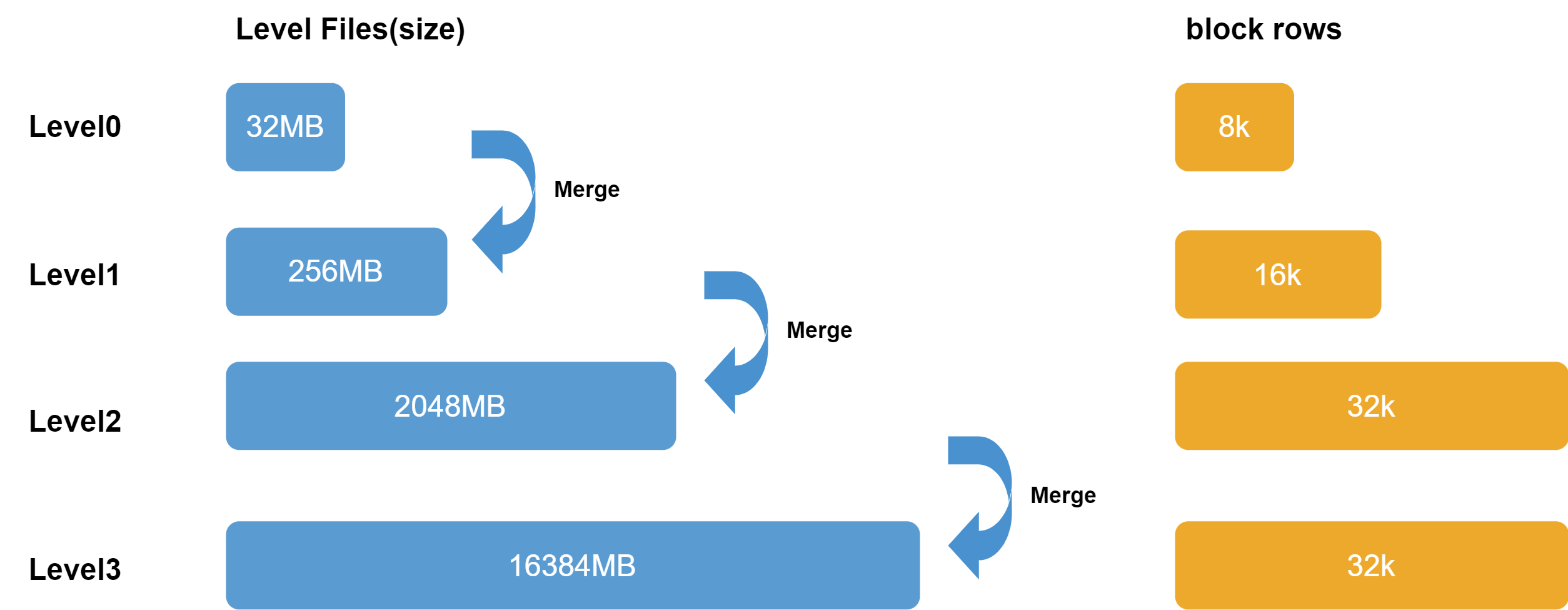
Level files are divided into 4 levels, from Level 0 to Level 3. The higher the level, the bigger the size of each level file. Data from the cache engine is divided into 32 MB chunks, compressed, and stored by partition in the level file at Level 0. Lower level files are merged to generate higher-level files. Consequently, files at lower levels are relatively newer, while files at higher levels are relatively older.
Read and Write Operations
Writing Data
When writing to a TSDB database, the data will be written through the following process:
- Recorded in theredo log.
- Cached in thememory (cache engine): Simultaneously with the redo log write, data is written to and sorted in the TSDB cache engine. When data is initially written, it is appended to the end of the write buffer. After the unsorted write buffer reaches a threshold, it is sorted according to the specified sortColumns and converted into a read-only sorted buffer.
- Flushed to disk: When the cache engine's data volume reaches 50% of the predefined TSDBCacheEngineSize, the TSDB engine initiates a flush operation. The system writes the data by partition to level 0 files (each approximately 32MB in size). During the flush operation, data is sorted globally. Data undergoes two sorting operations: being sorted by sort columns first and then being sorted globally. This approach leverages the divide-and-conquer algorithm to enhance sorting efficiency.
- Background compaction: The system automatically triggers a compaction
when
(1) the number of level files at a lower level exceeds 10, or the total file size at a specific level surpasses the size of a single-level file at the next higher level. The system merges these level files into a level file at the higher level;
(2) TSDB level files meet the compaction criteria. In cases where there may be too many files without compaction, users can use
triggerTSDBCompactionto manually trigger compaction.
Reading Data
The TSDB engine introduces an indexing mechanism based on the sort key, which is more suitable for point queries. Additionally, the TSDB engine does not use user-space caching but relies solely on the operating system's cache. The specific query process is as follows:
- Partition Pruning: The system narrows down the relevant partitions based on the filtering condition.
- Loading Indexes: The system traverses all level files in the involved
partitions and loads the index information into memory. A lazy caching
strategy is used here, which means that the index information will not be
immediately loaded into memory until the first query hits the partition.
Once loaded, the index information for that partition remains cached in
memory unless evicted due to memory constraints. Subsequent queries
involving this partition can skip this step and directly read index
information from memory.Note:
The size of the memory area for storing index data is determined by TSDBLevelFileIndexCacheSize. Users can monitor the memory usage of these indexes in real time using the getLevelFileIndexCacheStatus function. If the loaded index data exceeds the configured size, the system will employ LRU (Least Recently Used) to manage it. The threshold for this process can be adjusted by TSDBLevelFileIndexCacheInvalidPercent.
- Searching Data in Cache: The system searches the data in the cache engine: performing sequential scan in the write buffer or performing a binary search in the sorted buffer.
- Searching Data on Disk: Based on the index, the system locates the data blocks of the queried fields in the level files and decompresses them into memory. If the query's filtering conditions include sort columns, the index can be used to accelerate the query.
- Returning Query Results: Merge the results from steps 3 and 4 and return them.
Indexing Mechanism
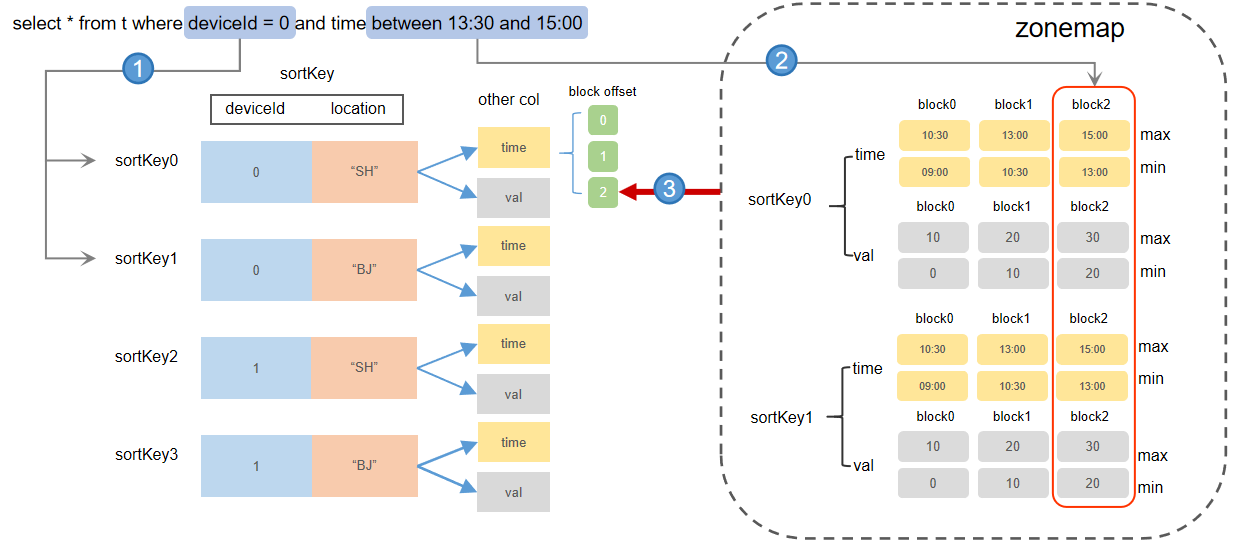
The in-memory index consists of two parts:
- Block offset: indexes of the level file.
- Zonemap: zonemap of the level file.
The specific indexing process is as follows:
- Locating the sort key entry by indexes: The indexes record the block
address offsets for each field under every sort key entry in the level file.
If the query condition includes the sort key field, the system can narrow
down search range by partition pruning. Once a sort key index is hit, the
system retrieves the address offsets for all blocks corresponding to the
sort key entry.
For example, if the sort columns are deviceId, location, and time, and the query condition is “deviceId = 0”, the system quickly locates all sort key entries where “deviceId = 0” and retrieves all block data.
- Locating blocks by zonemap: After locating the sort key entry in step 1, the system checks the corresponding minimum and maximum values in the zonemap. If the query condition specifies additional fields, the system can further filter out blocks unrequired. For example, if the sort columns are deviceId, location, and time, and the query condition is the “time between 13:30 and 15:00”, the system uses the zonemap information of the time column to quickly identify that the relevant block is “block2”. The system then uses the indexes to locate the address offset of block2 across all level files, reads the block data from disk, and applies any necessary deduplication before returning the results to the user.
Updating Data
The data update process in the TSDB engine varies depending on the deduplication policy settings.
- Partition Pruning: The system narrows down the relevant partitions based on the filtering condition.
- Updating Data in Memory: The system loads all data from the corresponding partition into the memory and updates it.
- Writing Updated Data to a New Version Directory (When
keepDuplicates=ALL/FIRST): The system writes the updated data
back to the database and uses a new version directory (default is
<physicalIndex>_<cid>) to store it. Old files are removed
periodically (default is 30min).
Appending Updated Data (When keepDuplicates=LAST): The system directly appends the updated data to the level 0 files. Updates and changes are appended to new files rather than modifying existing level files.
DolphinDB offers three methods for updating tables:
- update: Standard SQL syntax.
- sqlUpdate: Dynamically generates the metacode of the SQL update statement.
- upsert!: Inserts rows into a keyed table, indexed table or DFS table if the values of the primary key do not already exist, or update them if the primary key do.
- Update operations with keepDuplicates=LAST are advisable for scenarios requiring frequent updates.
- Update operations with keepDuplicates=ALL/FIRST modify the entire partition. It is important to ensure that the total size of partitions in each update does not exceed available system memory to avoid overflow.
Deleting Data
The data deletion process in the TSDB engine varies depending on the deduplication policy settings.
When keeping all records or only the first record, the data deletion process is similar to the update process. The specific process is:
- Partition Pruning: The system narrows down the relevant partitions based on the filtering condition.
- Deleting Data in Memory: The system loads all data from the corresponding partition into memory and deletes data based on conditions.
- Writing Back of Retained Data: The system writes the retained data back to the database and uses a new version (default is "<physicalIndex>_<cid>") to save it. Old files are removed periodically (default is 30min).
When keeping only the latest record, soft deletion can be enabled through the softDelete parameter. Soft deletion is recommended for scenarios requiring frequent data deletions, significantly improving deletion performance.
Features of the TSDB Engine
- Queries with partitioning columns and sort columns in filtering conditions have high performance.
- Data sorting and deduplication are supported.
- Suitable for storing in wide formats with hundreds or thousands of columns. It also supports complex data types and forms such as BLOB type and array vectors.
- If only the last record is kept for duplicate records (set keepDuplicates = LAST for function createPartitionedTable), to update a record, only the level file that this record belongs to needs to be rewritten instead of an entire partition.
- Relatively lower write throughput as data needs to be sorted in the cache engine and the level files might be compacted.
- Relatively lower performance when reading data from an entire partition or columns in an entire partition.
Usage Example
Creating a Database
Use the database function (with engine specified as “TSDB”) to create a COMPO-partitioned TSDB database.
create database "dfs://test_tsdb"
partitioned by VALUE(2020.01.01..2021.01.01),HASH([SYMBOL, 100]), engine='TSDB'database:dbName="dfs://test_tsdb"
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 100])
db = database(directory=dbName, partitionType=COMPO, partitionScheme=[db1, db2], engine="TSDB")Creating a Table
There are two ways to create a table within a TSDB database.
create table dbPath.tableName (
schema[columnDescription]
)
[partitioned by partitionColumns],
[sortColumns], [keepDuplicates=ALL],
[sortKeyMappingFunction]tbName="pt1"
colName = "SecurityID""TradeDate""TradeTime""TradePrice""TradeQty""TradeAmount""BuyNo""SellNo"
colType = "SYMBOL""DATE""TIME""DOUBLE""INT""DOUBLE""INT""INT"
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=tbName,
partitionColumns="TradeDate""SecurityID", compressMeth(2) create by createPartitionedTable:
createPartitionedTable(dbHandle, table, tableName, [partitionColumns],
[compressMethods], [sortColumns], [keepDuplicates=ALL], [sortKeyMappingFunction])createDimensionTable(dbHandle, table, tableName, [compressMethods],
[sortColumns], [keepDuplicates=ALL], [sortKeyMappingFunction])Since DolphinDB 3.00.1, users can design partitioning schemes by custom rules. A function call can be passed in when specifying partitioning columns and data is partitioned based on the function result. Below is an example:
// define a function to process the partitioning column data
def myPartitionFunc(str) {
return temporalParse(substr(str, 6, 8), "yyyyMMdd")
}create database "dfs://partitionFunc"
partitioned by VALUE(2024.02.01..2024.02.02)
create table "dfs://partitionFunc"."pt"(
id_date STRING,
ts TIMESTAMP,
value DOUBLE
)
partitioned by myPartitionFunc(id_date)createPartitionedTable:db = database("dfs://partitionFunc", VALUE, 2024.02.01..2024.02.02)
tb=table(100:0,["id_date", "ts", "value"],[STRING,TIMESTAMP, DOUBLE])
db.createPartitionedTable(table=tb, tableName=`pt,
partitionColumns=["myPartitionFunc(id_date)"])The example above provides a simple demonstration of how to create databases and tables in the TSDB engine. In applications, it's important to configure the database and table parameters based on the specific requirements. Below are some key parameter setting recommendations for creating databases and tables.
Considerations for Databases and Tables Design
Database
Partitioning Design
Recommended partition size for a TSDB database is 400MB - 1GB (before compression). Distributed queries load data by partition for parallel processing. Too large partitions may lead to insufficient memory, reduced query parallelism, and decreased update/delete efficiency. Conversely, too small partitions can result in excessive subtasks, increased node load, and metadata explosion on the control node. For detailed information, refer to Data Partitioning.
- ‘TRANS' (default): Concurrent writes to the same partition are not allowed.
- ‘CHUNK': Multi-threaded concurrent writes to the same partition are allowed. Note: atomic='CHUNK' may compromise transaction atomicity due to potential data loss from failed retries.
Table
compressMethods
compressMethods is a dictionary indicating which compression methods are used for specified columns.
- Use SYMBOL for highly repetitive strings. There are less than 2^21 (2,097,152) unique values in a SYMBOL column of the table (refer to S00003 for more information).
- The delta (delta-of-delta encoding) compression method can be used for time-series data and sequential data (integers).
- In other cases, use Lz4 compression method.
sortColumns
sortColumns is a STRING scalar/vector that specifies the column(s) used to sort the ingested data within each partition.
- The number of columns specified by sortColumns should not exceed 4
and the number of sort key entries within each partition should not exceed
2000 for optimal performance.
- Typical combinations: SecurityID+timestamp (finance), deviceID+timestamp (IoT).
- Avoid using primary keys or unique constraints as sortColumns.
- It is recommended to specify frequently-queried columns for sortColumns and sort them in the descending order of query frequency, which ensures that frequently-used data is readily available during query processing.
- If only one column is specified for sortColumns, the column is used as the sort key. Block data is unordered, so queries must scan every block. If multiple columns are specified for sortColumns, the last column must be either a temporal column or an integer column and the preceding columns are used as the sort keys. Data within blocks is sorted by the last column, so if the query condition includes a temporal or integer column, it can potentially skip full block scans.
- sortColumns can only be of INTEGER, TEMPORAL, STRING, or SYMBOL type. sortKey can only be of TIME, TIMESTAMP, NANOTIME, or NANOTIMESTAMP type.
DolphinDB does not support constraints. It is not recommended to set primary keys or unique constraints as sort columns. Doing so would cause each row of data to become a sort key entry, severely degrading both write and query performance, and significantly increasing memory consumption.
sortKeyMappingFunction
sortKeyMappingFunction is a vector of unary functions used for dimensionality reduction when sort key entries exceed recommended limits.
Example: For 5,000 stocks partitioned by date with SecurityID + timestamp as sortColumns, resulting in about 5,000 sort keys per partition, use sortKeyMappingFunction=[hashBucket{, 500}] to reduce this to 500 sort key entries.
keepDuplicates
keepDuplicates specifies how to deal with records with duplicate sortColumns values with three options: ALL (keep all records), LAST (only keep the last record) and FIRST (only keep the first record).
- If there are no specific requirements for deduplication, consider the
following factors to determine the optimal keepDuplicates setting:
- High-Frequency Updates: Use keepDuplicates=LAST for more efficient append updates.
- Query Performance: Use keepDuplicates=ALL to avoid extra deduplication overhead during queries.
- When atomic=CHUNK, use keepDuplicates=FIRST/ LAST. In case of concurrent write failures, data can be rewritten directly without the need for deletion and reinsertion.
Performance Tuning
Factors such as partitioning and indexing can significantly impact the performance of data writing and querying in the TSDB engine. Therefore, it is crucial to understand the relevant parameter configurations when creating databases and tables. This section will focus on how to optimize TSDB's writing and querying performance through careful parameter settings.
- TSDBCacheEngineSize: The capacity (in GB) of the TSDB cache engine. The default value is 1. If the parameter is set too small, data in the cache engine may be flushed to disk too frequently, thus affecting the write performance; If set too high, a large volume of cached data is not flushed to disk until it reaches 50% of TSDBCacheEngineSize (or after 10 minutes). If power failure or shutdown occurs in such cases, numerous redo logs are to be replayed when the system is restarting, causing a slow startup.
- TSDBLevelFileIndexCacheSize: The upper limit of the size (in GB) of index data (level file indexes and zone maps). The default value is 5% of maxMemSize. If set too small, frequent index swapping may occur. The zonemap, a memory-intensive component, can be estimated using the formula: (number of partitions) × (number of sort keys) × (4 × sum of each field's byte size). Here, 4 represents the four pre-aggregation metrics: min, max, sum, and notnullcount.
- TSDBAsyncSortingWorkerNum: A non-negative integer indicating the number of threads for asynchronous sorting in the TSDB cache engine. The default value is 1. Increasing this value when sufficient CPU resources are available to improve write performance.
- TSDBCacheFlushWorkNum: The number of worker threads for flushing the TSDB cache engine to disk. The default value is the number of disk volumes specified by volumes. If the configured value is less than the number of disk volumes, the default value is used. Typically, this configuration does not need to be modified.