Multi-Model Database
DolphinDB is a multi-model database where multiple storage engines are integrated within a unified database architecture. This design enables storage and querying of data using various data models, providing an efficient and integrated solution to complex data governance scenarios in fields like finance and IoT.
Multi-Model Architecture
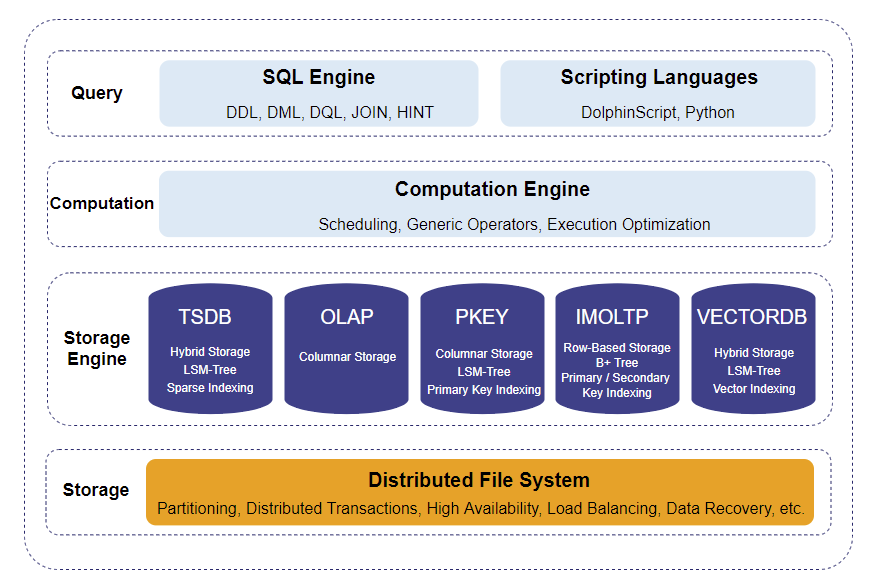
DolphinDB employs an architecture (see image below) consisting of four layers, from top to bottom:
- Query layer: Compiles and parses programming languages, supporting DolphinScript (including SQL-92 compliant statements) and Python.
- Computation layer: Abstracts common functionalities in distributed computation like generic operators, query optimization and vectorization, ensuring efficient resource utilization across all computational tasks.
- Storage engine layer: Consists of multiple storage engines that manage in-partition data storage. While the storage engines are optimized for different scenarios with custom storage and indexing designs, they all implement standardized read and write interfaces. The other layers interact with these interfaces without knowing the exact storage engine in use.
- Storage layer: Manages distributed storage, handling data persistence, partitioning, replication, transactions, load balancing, recovery, and metadata management.
Storage Engines
The database's layered, unified architecture allows new storage engines to be integrated with minimal changes. A new storage engine only needs to provide a specific data model (including indexing implementation and data file structure), along with interfaces for other layers to read and write data. These interfaces work with abstract representations of tables and vectors with storage details hidden, thus reducing inter-layer coupling. For example, the SQL engine can process queries using abstract representations of tables and columns (treated as vectors in the underlying computation layer) without concern for storage details.
The storage of data in each partition is entirely managed by the storage engines and can vary in implementation. For example, in the TSDB engine, a column in a partition consists of multiple blocks, forming a logically contiguous but physically scattered vector. Conversely, the OLAP engine stores a column within a partition as a physically contiguous vector.
While the distributed file system (DFS) in the underlying storage layer manages entire database data storage across nodes, the storage engines handle in-partition operations, including reads, writes, indexing, and decompression. During writes, data is initially written to in-memory tables per partition via the storage engine's interface, then persisted to disk based on DFS-specified locations. For reads, the storage engine retrieves data from disk by partition and passes it to the computation layer for processing.
Storage engine is specified during database creation through the engine parameter of the database function. While you can create databases under different storage engines, each database is tied to a single storage engine.
DolphinDB provides the following storage engines:
| Storage Engine | Use Cases |
|---|---|
| OLAP | Large-scale data analysis (e.g., querying trading volumes for all stocks in a specific time period) |
| TSDB | Most time-series processing scenarios; balances analytical capabilities and query performance |
| VectorDB | Fast retrieval with massive datasets (e.g., search engines, AI generative models) |
| PKEY | Real-time updates and efficient queries (e.g., real-time data analysis through CDC integration with OLTP systems) |
| IMOLTP | High-concurrency, low-latency OLTP (e.g., financial trading systems); dataset size must be within memory capacity |
| TextDB | Market sentiment analysis, information filtering and processing in finance; large-scale log data management, real-time search and analysis in IoT |
| IOTDB | Fine-grained and low-latency management of massive measurement points in IoT scenarios such as power grids, automotive telematics, and industrial manufacturing |
Except for the in-memory IMOLTP, all other storage engines support horizontal partitioning of large data sets based on a distributed file system, ensuring data is evenly dispersed across data nodes.
All storage engines support horizontal partitioning of large data sets based on a distributed file system, ensuring data is evenly dispersed across data nodes.