OLAP Storage Engine
The OLAP engine is well-suited for large-scale data analysis. It utilizes data partitioning to horizontally divide large datasets into multiple partitions based on specified rules. Within each partition, the engine employs columnar storage for data management. Data partitioning allows for selective column access, reducing unnecessary I/O operations and significantly enhancing query performance.
Storage Structure
The following figure illustrates the storage structure of the OLAP engine.
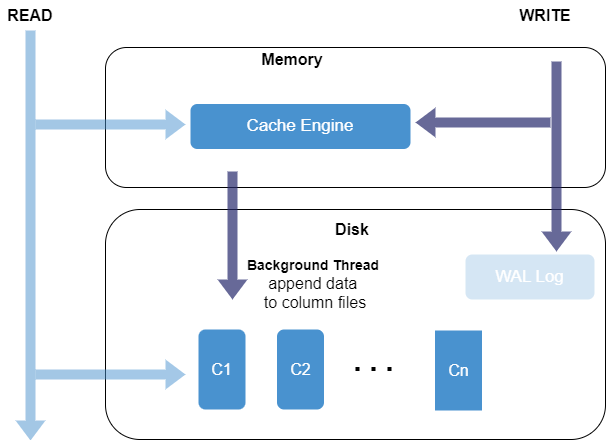
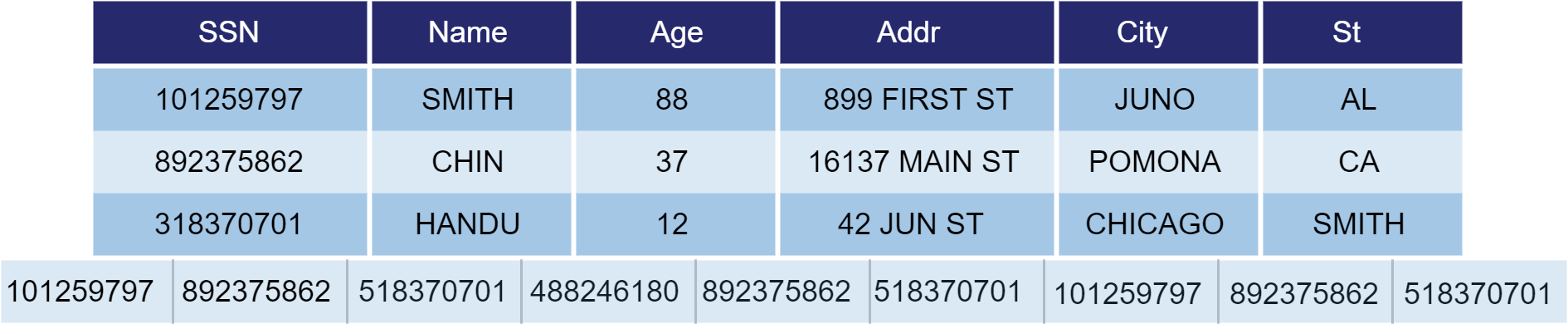
As shown in the figure below, data from the same column is stored in a separate file, contiguously in the same order as in the table. And each column forms a long array.
Data is appended to the corresponding columnar files, preserving the order of writing. This storage method offers the following advantages:
- Efficient Compression: Since data of the same type often has similar values, columnar storage can better leverage compression algorithms, reducing storage costs.
- Large-Scale Data Analysis: Columnar storage excels in large-scale data analysis. Queries typically access only specific columns rather than entire rows, which significantly improves query efficiency.
Data Compression
The OLAP engine supports lossless compression, offering compression algorithms through compressMethods:
- "lz4" (default): Suitable for almost all data types, primarily for repetitive characters, with the compression ratio tied to the frequency of repeated data. Although the "lz4" method may not achieve the highest compression ratio, it provides fast compression and decompression speeds especially when there are many duplicates in a column.
- "zstd": Suitable for almost all data types. It provides a higher compression ratio compared to "lz4", but the compression and decompression speed is about half as fast as "lz4".
- "delta" (delta-of-delta encoding): Suitable for temporal data or integer data with small variations. It is used for the time column to significantly reduce the storage space required for timestamps.
- "chimp": Suitable for DOUBLE type data with decimal parts not exceeding three digits in length. It has a high compression ratio and fast compression and decompression speeds.
- Additionally,for highly repetitive strings with few unique values, SYMBOL type storage can be used. DolphinDB uses dictionary encoding for SYMBOL type data, converting strings to integers to reduce storage space for strings.
In real-world scenarios, the compression ratio for stored financial data typically ranges from 20% to 30%. OLAP uses an incremental compression strategy, compressing only newly added data. Therefore, batch writing enhances compression efficiency. However, if only one record is written at a time with the cache engine disabled, the data stored on disk remains uncompressed.
Writing Data
In general scenarios, data is typically flushed to disk immediately after writing. Frequent small-batch writes can significantly degrade disk I/O performance and reduce compression efficiency. To address this, the OLAP engine includes a cache engine, enabling buffered batch writing. The cache engine in DolphinDB serves as the write caching. When writing to a file, the time to insert 1 record and 1000 records is basically the same. Most of the time is spent opening and closing the file. By buffering multiple small writes and performing a single batch write operation, the system can significantly reduce the overhead associated with frequent file operations, thereby enhancing overall write performance.
To enable the cache engine, setOLAPCacheEngineSize>0 and dataSync=1 (redo log enabled).
The OLAP engine supports ACID transactions and implements MVCC (Multiversion Concurrency Control ) for snapshot isolation.
When writing to the OLAP database, the data will be written through the following phases:
- Recorded in theredo log.
- Cached in thememory (cache engine): Simultaneously with the redo log write, data is written to and sorted in the OLAP cache engine.
- Flushed to disk: When the cache engine's data volume reaches the predefined 30% of the OLAPCacheEngineSize, the OLAP engine initiates a flush operation. The cached data is appended to the column files within the partition.
Reading Data
The OLAP engine stores each column of data as a columnar file. Therefore, when reading data, only the necessary columnar files are read from the disk, decompressed, and loaded into memory. The specific process is as follows:
- The system narrows down the relevant partitions based on the filtering condition.
- The system loads the data files into memory and applies the filters.
- The system reads the corresponding data of the other columns based on the selected column data.
This approach allows the OLAP engine to maintain high performance for queries with high throughput. However, for updates or deletions, the entire partition must be loaded into memory to make the changes, which incurs significant performance overhead.
Updating Data
The OLAP engine supports ACID transactions and implements MVCC for snapshot isolation. For each update, the system reads the columnar files from the corresponding partition, performs the update in memory, and creates a new version to store the new data. Unchanged columns are managed using hard links to improve performance and reduce unnecessary data reads and writes. Until the transaction is committed, the old version of data can still be accessed. If an update involves multiple partitions and one fails, the system rolls back the changes in all partitions.
To meet different requirements, DolphinDB provides three methods for updating tables:
Deleting Data
The data deletion process in the OLAP engine follows the same steps as the update process. Data is read by partition, the deletion is performed, and a new version directory is written. Transactions ensure data consistency, and MVCC guarantees read consistency. If a deletion involves multiple partitions and one fails, the system rolls back the changes in all partitions.
To meet different requirements, DolphinDB provides the following methods for deleting data:
- dropPartition: Removes data from the partition. Optionally removes partition schema.
- delete: Deletes datafrom the table.
- sqlDelete: Dynamically generates the metacode of the SQL update statement.
- dropTable: Drops tables.
- truncate: Deletes all data in a table but keep its schema.
Features of the OLAP Engine
- Data is stored in the table in the same order as it is written, ensuring highly efficient data writing.
- It is suitable for scenarios where entire partition or specific columns within a partition need to be read.
- It is suitable for large-scale data scanning and full table scans.
- Deduplication is not supported.
- It is not suitable for tables with more than a few hundred columns.