TextDB
DolphinDB version 3.00.2 introduced TextDB, a document retrieval database system based on the PKEY storage engine. TextDB is designed to further enhance information retrieval with efficient full-text search using inverted indexes, making it well-suited for handling unstructured text data.
Key Features of TextDB:
- Query Acceleration: Optimizes full-text search for string matches, delivering superior performance over traditional LIKE queries.
- Versatile Search Options: Offers flexible search capabilities, including keyword search, phrase search (with prefix and suffix patterns), and proximity search.
- Efficient Indexing: Integration with DolphinDB's storage engine minimizes index storage overhead and enhances index read/write efficiency.
TextDB serves key functions in both financial and IoT applications. In finance, it works alongside NLP tools to analyze market sentiment and filter information from text data. In the IoT sector, its integration with DolphinDB storage engine enables efficient storage and real-time searching of massive log datasets.
Design
Text Data Storage
Instead of creating a new storage system, TextDB leverages DolphinDB's existing primary key storage engine (PKEY) to handle text data. For more details about how PKEY works, see Primary Key Storage Engine.
Index Construction
TextDB uses inverted indexes for text columns to enable fast text searching.
The construction of the inverted index begins with tokenization, where the original text is segmented into discrete words. The system then performs text processing as configured:
- Converting words to root forms (stemming)
- Making all text lowercase
- Removing common stop words
Based on these processed word sequences, inverted index is then built.
Tokenizer
TextDB's tokenizer is a core component that divides text into word sequences for building a text index.
- The English tokenizer splits text by spaces and punctuation marks.
- Alternatively, selecting the none option bypasses tokenization. In such case, each text entry is treated as one complete unit for indexing. Under this mode, partial matches are not possible - for instance, given the text "apple is delicious", only searching for this exact phrase will succeed, while queries for individual words like "apple" or "delicious" will fail.
Stop Words
TextDB automatically filters out stop words - common words that carry little semantic value. When you run a query, TextDB ignores any stop words it contains, which may affect the search results. For instance, since "such" is a stop word, searching for "apple or banana" is identical to searching for "apple banana".
"a", "an", "and", "are", "as", "at", "be", "but", "by",
"for", "if", "in", "into", "is", "it",
"no", "not", "of", "on", "or", "such",
"that", "the", "their", "then", "there", "these",
"they", "this", "to", "was", "will", "with", Inverted Index
Inverted index is a data structure commonly used as database index that organizes text search data like a dictionary: each word acts as a key that points to a list of document IDs containing that word.
This structure enables efficient text search as it allows the system to find relevant documents by simply looking up the terms in the index, eliminating the need to scan through all texts sequentially.
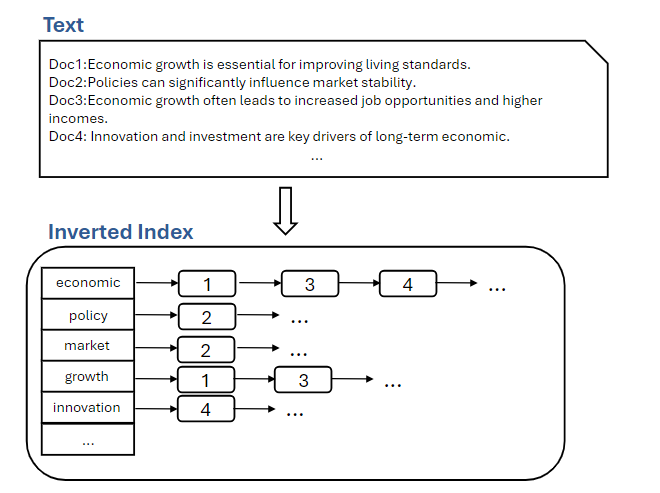
Index Organization
TextDB organizes its indexing structure by level file, with each file maintaining its own text index. The system preserves the order of text entries when building indexes, using the positions of rows as text IDs. This aligned ordering between text data and index entries streamlines query processing and optimizes storage efficiency.
Text Search
When TextDB receives a query request, it retrieves data from both the in-memory cache engine and the level files. The process unfolds as follows:
- Search in the cache engine: Since no text index is built for data in the cache engine, system uses tokenizer to split text into words first and then performs a traversal to find matches.
- Search across all level files: TextDB loads text indexes for relevant columns, performs searches on the indexed columns, and retrieves matching results based on the query conditions.
- Merge results: The results from both the cache engine and level files are merged to form the final response.
Unlike the LIKE operator, which requires a full table scan during queries, TextDB uses indexes to perform its searches. As a result, when searching through large datasets to find small amounts of matching data, TextDB achieves significantly better query performance compared to using LIKE.
Text Index Settings
TextDB allows you to customize how text is processed and searched through three main
settings: tokenization, case handling, and word stemming. Configure these options
using the indexes parameter when creating a partitioned table (with
createPartitionedTable), for example:
indexes=textindex(parser=english, lowercase=true, stem=true)Tokenization
parser specifies the tokenizer. It has no default value and must be explicitly set. Options include none (not tokenized) and english (tokenized based on spaces and punctuations).
Case Sensitivity
lowercase specifies whether the tokenizer is case-insensitive, which only takes effect when parser is set to english. The default value is true. Set it to false for case-sensitive scenarios.
Word Stemming
stem specifies whether to match English words by their stem, which only takes effect when parser=english and lowercase=true. The default value is false, indicating exact searches. Set it to true to return related derivatives (e.g., a search for "dark" may also return "darkness").
Text Search Functions
TextDB provides a list of functions for text search, outlined in the table below. For detailed usage, see the Usage Example section.
These functions are limited to querying text-indexed columns and can only be used within the WHERE clause of a query statement.
| Functions | Description |
|---|---|
| matchAny | Searches rows containing any of the specified terms |
| matchAll | Searches rows containing all of the specified terms |
| matchPhrase | Searches rows containing the specified phrase |
| matchPrefix | Searches rows containing words with the specified prefix |
| matchSuffix | Searches rows containing words with the specified suffix |
| matchPrefixSuffix | Searches rows containing words with both the specified prefix and suffix |
| matchPhrasePrefix | Searches rows containing the specified phrase followed by a word with the specified prefix |
| matchPhraseSuffix | Searches rows containing the specified phrase that is preceded by a word with the specified suffix |
| matchPhraseInfix | Searches rows containing the specified phrase that is followed by a word with the specified prefix and preceded by a word with the specified suffix |
| matchSpan | Searches rows containing the specified phrase with no more than slop extra words (excluding stop words) before, after, or within it |
| matchUnorderedSpan | Searches rows containing the specified phrase with no more than slop extra words (excluding stop words) before, after, or within it |
Exact Match Acceleration
A text index will automatically speed up queries using = or IN operators on text-indexed columns if both of the following conditions are met:
- The text index is built without tokenization - setting parser as ‘none’.
- The value on the right side of the = or IN query is a constant.
select textCol from pt where textCol = "apple";
select textCol from pt where textCol in ("apple", "banana");Considerations When Using TextDB
Database and Table Creation
- TextDB is built based on PKEY database, so you must specify engine="PKEY" when creating a database.
- Text indexes can only be created on STRING or BLOB columns.
- Multiple indexes can be created on several individual columns of a single table, but a single index that spans multiple columns is not supported.
Data Size and Character Limits
- TextDB supports text indexes on STRING columns, which have a maximum length limit of 65,535 bytes. Text exceeding this limit will be truncated.
- Only UTF-8 encoded strings are supported. If an invalid UTF-8 character (garbled text) is encountered, the string will be truncated up to that point.
Queries
- TextDB only supports query acceleration on columns with a text index.
- Queries must be applied directly to tables that have text indexing set. The text search functions cannot be applied to joined tables.
- Text search functions must be used in the where clause and must be positioned outermost, without being nested within other conditions.
- Only and operator can be used to connect text search functions with other conditions. The or operator is not supported.
Usage Example
Create a database and a table.
// create a PKEY database
dbName = "dfs://test"
if (existsDatabase(dbName)){
dropDatabase(dbName)
}
// use the database function
db = database(dbName, HASH, [INT, 3], engine=`PKEY)
// or use the SQL CREATE DATABASE statement
create database "dfs://test"
partitioned by HASH([INT, 3]),engine="PKEY"
// create a partitioned table with text indexing on textCol
// use the createPartitionedTable function
schematb = table(5:5, `col0`col1`textCol, [INT,INT,STRING])
pt = createPartitionedTable(dbHandle=db,table=schematb,tableName=`pt, partitionColumns=`col0, primaryKey=`col0`col1, indexes={"textCol":"textindex(parser=english,full=false,lowercase=true,stem=false)"})
// or use the SQL CREATE TABLE statement
CREATE TABLE "dfs://test"."pt"(
col0 INT,
col1 INT,
textCol STRING [indexes="textIndex(parser=english,full=true,lowercase=true,stem=false)"]
)
PARTITIONED BY col0,
primaryKey=`col0`col1Append data to pt.
textData = [
"The sun was shining brightly as I walked down the street, enjoying the warmth of the summer day.",
"I enjoy a refreshing smoothie made with apple every morning.",
"The sound of the waves crashing against the shore was a soothing melody that helped me relax after a long day.",
"The city skyline looked stunning from the top of the mountain, with the lights twinkling like stars in the night sky.",
"The picnic basket was filled with juicy apple slices and ripe banana for a healthy snack."
]
data = table(1..5 as col1, 1..5 as col2, textData)
pt.append!(data)Perform queries.
// Search for rows containing "apple" or "banana"
select textCol from pt where matchAny(textCol, "apple banana");
// Search for rows containing "apple" and "banana"
select textCol from pt where matchAll(textCol, "apple banana");
// Search for rows containing phrase "juicy apple"
select textCol from pt where matchPhrase(textCol, "juicy apple");
// Search for rows containing words prefixed with "ap"
select textCol from pt where matchPrefix(textCol, "ap");
// Search for rows containing words suffixed with "ana"
select textCol from pt where matchSuffix(textCol, "ana");
// Search for rows containing words prefixed with "ap" and suffixed with "le"
select textCol from pt where matchPrefixSuffix(textCol, "ap", "le");
// Search for rows containing phrase prefixed with "filled with juicy ap"
select textCol from pt where matchPhrasePrefix(textCol, "filled with juicy", "ap");
// Search for rows containing phrase suffixed with "th of the summer day"
select textCol from pt where matchPhraseSuffix(textCol, "th", "of the summer day");
// Search for rows containing phrase "twinkling like" that is preceded by a word prefixed with "hts" and followed by a word suffixed with "sta"
select textCol from pt where matchPhraseInfix(textCol, "hts", "twinkling like", "sta");
/**
Search for rows containing phrase "enjoying the summer day",
allowing up to 2 extra words (excluding stop words) before, after, or within the phrase
*/
select textCol from pt where matchSpan(textCol, "enjoying the summer day", 2)
/**
Search for rows containing phrase "day summer the enjoying" (order-insensitive),
allowing up to 2 extra words before, after, or within the phrase
*/
select textCol from pt where matchUnorderedSpan(textCol, "day summer the enjoying", 2)