TSDB Storage Engine Explained
1. Reading Guide
- Chapter 2: Engine migration and OLAP vs. TSDB comparison.
- Chapter 3: Underlying architecture and working principles.
- Chapter 4: Step-by-step TSDB database creation.
- Chapter 5: Query tuning cases.
- Appendix: Configuration parameter reference, maintenance functions, and FAQs.
Time series data consists of chronologically ordered records (e.g., financial market feeds, network logs, and sensor data). Due to the high volume of timestamps and temporal continuity, traditional relational databases often struggle with scalability and efficiency. DolphinDB introduced the TSDB engine in version 2.0 to optimize storage and query performance for such workloads. Prior to version 2.0, DolphinDB only supported the OLAP (Online Analytical Processing) storage engine. The OLAP engine adopts columnar storage, offering high compression rates and excellent performance in column-based queries and computations. This document aims to help users better understand the TSDB engine by explaining its principles, providing usage guidance, and offering case analysis, enabling them to configure more optimal storage strategies in production scenarios.
2. TSDB vs. OLAP
This section provides a structured comparison between the TSDB and OLAP engines in DolphinDB, helping users quickly understand their architectural differences, performance characteristics, and suitable use cases.
| Category | TSDB | OLAP |
|---|---|---|
| Storage Structure | PAX storage. Written data is grouped into 32MB level files (compressed to <10MB), subdivided into indexed blocks. | Columnar storage. Each column is stored as a separate file per partition. Not ideal for wide tables (>100 columns). |
| Data Types | Supports array vectors and BLOB | Does not support array vectors and BLOB |
| Compression | Block-level compression | Column-level compression, typically with higher ratios |
| Data Loading Unit | Block within a level file per partition | Column files (tablets) per partition |
| Write Method | Sequential writes. Each flush creates a new immutable level file (with minimal disk seeks). | Sequential writes. High column count increases disk seek overhead. |
| Lookup Method |
Partition pruning → Cache lookup (unsorted and sorted buffer) → Index search on disk TSDB does not support userspace cache but only relies on the OS cache. |
Partition pruning → Cache lookup → Full column file scan on disk OLAP maintains a userspace cache where the column files from the previous query are cached in memory until warningMemSize is reached. |
| Indexing | Supported (via sort key) | Not supported |
| Query Optimization | Partition pruning + indexing | Partition pruning + full-column scans (efficient for bulk reads) |
| Deduplication | Supported (via sort columns) | Not supported |
| Read/Write Order | Data is sorted within level files by sort columns | Write order is preserved within partitions; cross-partition queries merge by partition order |
| Insert/Delete/Update |
Insert: Creates new level file per write; Delete: Controlled via keepDuplicates and softDelete; Update: Controlled via keepDuplicates |
Insert: Appends to columns; Delete/Update: Full in-memory rewrite of affected columns |
| DDL/DML Support | Limited. Function
rename!/replaceColumn!/dropColumns! not
supported |
Full support |
| Resource Overhead |
Memory: sorting and index caching Disk: I/O for level file merge |
Lower memory and disk overhead |
Terminology Reference
- Block: See the Sort Columns section.
- Level file: See the Level File section.
- Unsorted buffer, sorted buffer: See the Write Process section.
- Sort columns, sort key: Refer to the explanation of the sortColumns parameter.
3. TSDB Storage Engine Architecture
This chapter outlines the architecture and operating principles of the TSDB storage engine, focusing on its structural design, read/write processes, configuration parameters, and file organization. The objective is to provide a clear architectural understanding to support effective debugging, tuning, and optimization of the TSDB database system.
3.1 LSM-Tree
The TSDB engine is built on a proprietary implementation of the Log-Structured Merge Tree (LSM-Tree), optimized for high-throughput, write-intensive workloads such as real-time analytics and logging systems. The core implementation leverages batched, sequential disk writes to achieve optimal write performance. The operational flow is as follows:
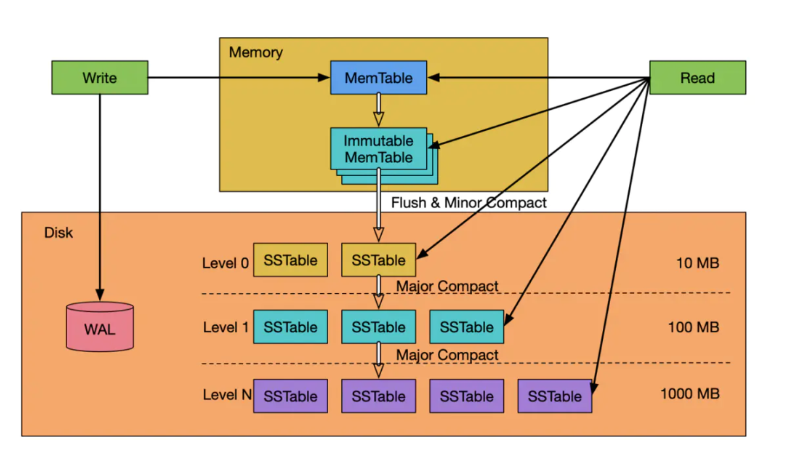
LSM-Tree Write Path
- Write-Ahead Log (WAL): Incoming data is first written to the WAL for fault recovery.
- Memtable (In-Memory Buffer): After WAL persistence, data is stored in an in-memory, sorted structure (e.g., red-black tree or skip list). When it reaches a size threshold, the memtable is frozen and enqueued for flushing to disk. A new memtable is then created.
- SSTables (Sorted String Tables): The sorted buffer is flushed to disk as immutable SSTables (which correspond to the TSDB level files in DolphinDB). These files reside at level 0 and are promoted through levels via compaction.
- Compaction: To control the number of SSTables and reduce read amplification, the engine merges files within and across levels, removing duplicate keys and maintaining order. This reduces query latency and storage usage at the cost of increased write amplification.
LSM-Tree Read Path
- Memtable Lookup: Queries first search the memtable, leveraging its sorted structure for fast lookups.
- SSTable Lookup: If not found in memory, the query proceeds through SSTables by level. Since each SSTable is sorted, efficient range scans are possible. Bloom filters may be used to minimize unnecessary reads.
- Version Resolution: If multiple versions of a key exist, the engine returns the appropriate version.
Note: In the worst case, all SSTables across all levels may be scanned, degrading query performance. Compaction helps mitigate this by reducing the number of SSTables.
Compared to traditional B+ trees, LSM-Trees offer higher write throughput and lower latency for random writes, which aligns well with DolphinDB's goal of high-performance ingestion of massive datasets. While LSM-Trees are less optimal than B+ trees for random reads and wide range queries, their sorted structure still allows efficient range lookups within individual SSTables.
DolphinDB-Specific Optimizations
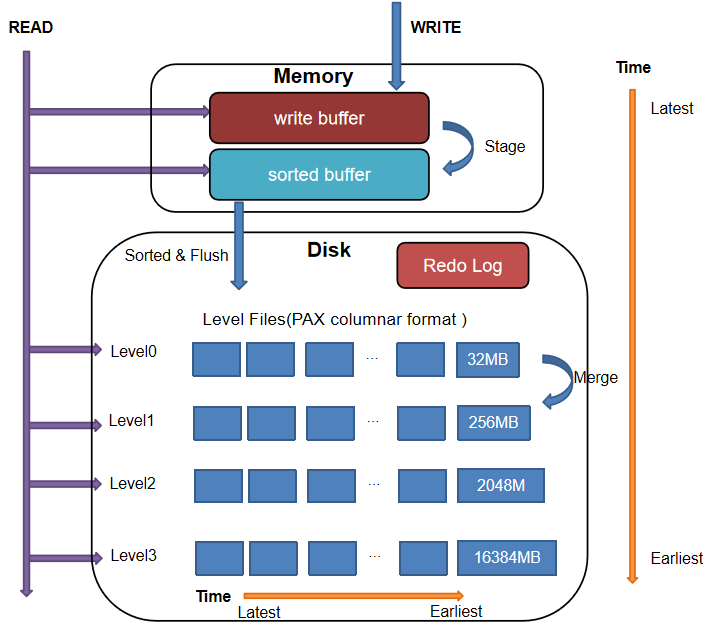
The TSDB engine introduces key enhancements to the standard LSM-Tree model:
- Modified Write Path: Unlike traditional LSM-Trees, DolphinDB does not directly write to an ordered in-memory structure. Instead, it first writes to an unsorted in-memory buffer. Once the buffer reaches a threshold, the data is sorted and converted to a structured format before being persisted.
- Query Optimization: During query initialization, DolphinDB scans all level files in the target partitions and loads their tail-end index metadata into memory. This metadata is read once and remains resident in memory for the session (unless evicted by memory pressure). Subsequent queries first check this memory-resident index, enabling direct access to relevant blocks without full disk scans.
3.2 CRUD Operations
This section details the CRUD operations in the DolphinDB TSDB engine.
3.2.1 Write Process
The TSDB write process follows a two-phase commit model similar to OLAP. Each write operation proceeds through the following stages:
-
Redo log: Each write transaction generates a redo log file. The write operation is first recorded in the TSDB redo log.
-
Cache engine: Simultaneously, data is written to the cache table in the TSDB cache engine. The cache table consists of a write buffer and a sorted buffer. Data is initially appended to the write buffer (unsorted). Once the number of rows exceeds TSDBCacheTableBufferThreshold (default: 16,384 rows), the buffer is sorted by sort columns, converted to a read-only sorted buffer, and the write buffer is cleared.
-
Flush to disk: A background thread triggers flushing when:
-
Cached data exceeds 50% of TSDBCacheEngineSize, or
-
A predefined time interval elapses.
-
Before flushing, all data in the cache table is merged and sorted by sort columns, then written by partition to the level 0 files (each up to 32 MB in size) on disk.
During flushing, if a single partition’s data volume is large, multiple level 0 files may be split (by 32 MB). If the written data per partition is less than 32 MB or if the last part after splitting is under 32 MB, it will still be written as a level file. Level files are immutable once written, subsequent data will not be appended to existing files.
Note:
-
Data with the same sort key will not be split across different level files. In practice, a level file may exceed 32 MB in size if a sort key corresponds to a large volume of data—potentially much larger.
-
Flushing efficiency can be improved by configuring the number of flush worker threads via TSDBCacheFlushWorkNum.
-
The process includes two sorting phases—once during buffering, once before disk write—enabling efficient divide-and-conquer sorting.
3.2.2 Query Process
The TSDB engine introduces an indexing mechanism that enhances performance for point queries. When configuring sort keys (see Determining Index Key Values), prioritize frequently queried columns. For optimal configuration, refer to Reasonable Sort Field Settings When Creating Databases.
Unlike OLAP, which implements user-space caching (retaining queried data in memory for faster reuse), TSDB relies solely on OS-level caching. It does not cache query results in user space, resulting in lower memory usage.
Query Process:
- Partition pruning: The system performs partition pruning based on the query to narrow the search scope.
- Load indexes: All level files in the relevant partitions are
traversed to load their tail-end index data into memory. Index data uses
a lazy caching strategy—it is not loaded during node startup but only
upon the first query hitting a partition. Once loaded, the index remains
in memory (unless evicted due to memory pressure). Subsequent queries
involving that partition can read the index directly from
memory.
Note: The memory area storing indexes is sized via TSDBLevelFileIndexCacheSize. Use
getLevelFileIndexCacheStatusto check current memory index usage. If the index exceeds this size, eviction is handled using a replacement algorithm. The eviction threshold can be tuned via TSDBLevelFileIndexCacheInvalidPercent. - Search in-memory cache: The system first searches the TSDB Cache Engine. If the data is in the write buffer, it is scanned sequentially. If it is in the sorted buffer, binary search is used for efficiency.
- Search disk data: The system uses indexes to locate the relevant
data blocks for query fields in the disk-level
level files, decompresses them into memory, and performs filtering. If the query condition includessortKey, index-based acceleration is applied. - Return results: The results from the two sources (cache and disk) are merged and returned.
Indexing Details
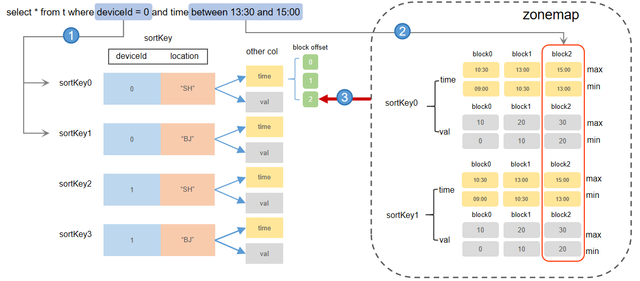
The in-memory index consists of two components:
- Block offset information maintained by sortKey (corresponding to the indexes section of a Level File),
- Zonemap information (corresponding to the zonemap section of a Level File).
The specific indexing process is as follows:
- Locating the sort key entry by indexes: The indexes record the block address offsets for each field under every sort key entry in the level file. If the query condition includes the sort key field, the system can narrow down search range by partition pruning. Once a sort key index is hit, the system retrieves the address offsets for all blocks corresponding to the sort key entry. For example, if the sort columns are deviceId, location, and time, and the query condition is “deviceId = 0”, the system quickly locates all sort key entries where “deviceId = 0” and retrieves all block data.
- Locating blocks by zonemap: After locating the sort key entry in step 1, the system checks the corresponding minimum and maximum values in the zonemap. If the query condition specifies additional fields, the system can further filter out blocks unrequired. For example, if the sort columns are deviceId, location, and time, and the query condition is the “time between 13:30 and 15:00”, the system uses the zonemap information to quickly identify that the relevant block is “block2”. The system then uses the indexes to locate the address offset of block2 across all level files, reads the block data from disk, and applies any necessary deduplication before returning the results to the user.
3.2.3 Update Process
The data update process in the TSDB engine varies depending on the deduplication policy settings.
- Partition Pruning: The system narrows down the relevant partitions based on the filtering condition.
- Updating Data in Memory: The system loads all data from the corresponding partition into the memory and updates it.
- Writing Updated Data to a New Version Directory (When
keepDuplicates=ALL/FIRST): The system writes the updated data
back to the database and uses a new version directory (default is
<physicalIndex>_<cid>) to store it. Old files are
removed periodically (default is 30min).
Appending Updated Data (When keepDuplicates=LAST): The system directly appends the updated data to the level 0 files. Updates and changes are appended to new files rather than modifying existing level files.
Note:
- Update operations with keepDuplicates=LAST are advisable for scenarios requiring frequent updates.
- Update operations with keepDuplicates=ALL/FIRST modify the entire partition. It is important to ensure that the total size of partitions in each update does not exceed available system memory to avoid overflow.
3.2.4 Delete Process
The data deletion process in the TSDB engine is similar to the update process.
- When keepDulicates=ALL/FIRST, the system performs a full partition scan, deletes records based on the conditions, and writes the result to a new version directory.
- When keepDulicates=LAST,
- If softDelete=true, the records to be deleted are retrieved, marked with a delete flag (soft delete), and appended back to the database.
- If softDelete=false, the deletion follows the same process as keepDulicates=ALL/FIRST.
The specific process is:
- Partition Pruning: The system narrows down the relevant partitions based on the filtering condition.
- Deleting Data in Memory: The system loads all data from the corresponding partition into memory and deletes data based on conditions.
- Writing Back of Retained Data: The system writes the retained data back to the database and uses a new version (default is "<physicalIndex>_<cid>") to save it. Old files are removed periodically (default is 30min).
Note:
- When configured with keepDuplicates=ALL/FIRST, update and delete operations applied to the entire partitions. It must be ensured that the total size of the affected partitions does not exceed available system memory; otherwise, it could lead to out-of-memory errors.
- When configured with keepDuplicates=LAST, update and delete operations are performed incrementally by appending data. This deduplication strategy is more efficient, recommended if the business scenario requires frequent updates and deletions.
3.3 Sort Columns
Sort columns (specified by the sortColumns parameter of function
createPartitionedTable) are a unique structure specific to
the TSDB engine, playing a crucial role in the storage and retrieval
processes.
3.3.1 Determining Sort Keys
As described in the write process, data is sorted in the cache engine based on the columns specified by the sortColumns parameter. The TSDB engine builds its index using these sort columns.
The sortColumns parameter defines two components, the sort key and the last column.
- If sortColumns contains n fields, the first n-1 columns form the sort key used for indexing.
- If sortColumns contains only 1 field, the column is used as the sort key.
Data sharing the same sort key is stored together in a columnar format. Each column is divided into fixed-size blocks, which are the smallest units used for both querying and compression. Within each block, data is sorted by the last column specified in sortColumns.
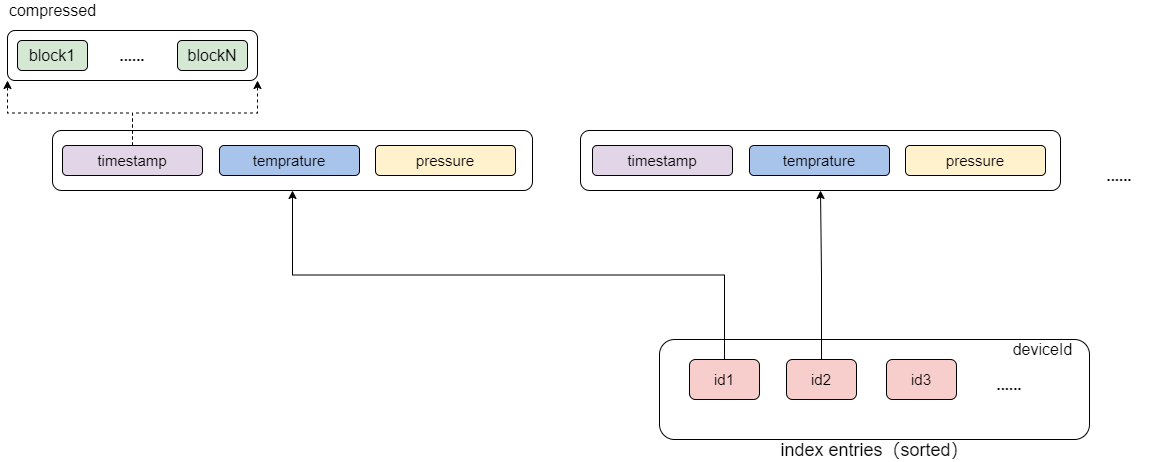
During queries, if filter conditions include fields from sortColumns, the system first uses the sort key to locate the relevant index entry. It then uses time-based metadata to quickly find and load the relevant column blocks into memory.
Note:
- Block Ordering: Within each block, data is sorted by the last column of sort columns. Additionally, metadata for each sort key stores the first record of every block, which allows the engine to skip irrelevant blocks quickly.
- Block Alignment: Since each block contains a fixed number of rows, locating the block also enables direct offset-based access to corresponding blocks in other columns.
During database design, avoid having too many unique sort keys in a single partition. Excessive key cardinality results in smaller data segments per key, which increases the cost of index lookups and metadata access, ultimately degrading query performance.
3.3.2 Data Sorting
The sortColumns parameter determines the order in which data is written to disk. Before flushing, each data batch is sorted by the specified sort columns, ensuring order within each transaction and level file. However, ordering is not guaranteed across files or across partitions.
Therefore, sort columns ensure local ordering—data within a level file is ordered by sort key, and data blocks within each sort key are ordered by time. This localized sorting supports:
- Faster index lookups when queries include range filters or exact matches on the sort key.
- Efficient block location via sort key metadata.
3.3.3 Data Deduplication
TSDB supports deduplication to handle records with identical timestamps. Deduplication is based on sort columns, and occurs both during the sorting stage of data writes and during level file compaction. The parameter keepDuplicates can be set during table creation, which supports:
- ALL (default): Retain all records.
- LAST: Retain only the latest record.
- FIRST: Retain only the earliest record.
Different deduplication strategies affect update operations. For instance:
- With keepDuplicates=ALL or FIRST, each update requires loading partition data into memory, updating it, and writing it back to disk.
- With keepDuplicates=LAST, new data is appended, and actual deduplication occurs during level file compaction.
Note:
- The deduplication strategy does not guarantee that no redundant data exists on disk—it only ensures that redundant data is not read during queries. During queries, blocks from all level files associated with the relevant sort key are loaded, and deduplication is performed in memory before the results are returned.
- DolphinDB does not enforce constraints. Users often simulate primary or unique key constraints by including those fields in sort columns. This leads to a high number of unique sort keys, reducing the amount of data per key and potentially causing storage inefficiencies and query slowdowns.
3.4 Level Files
3.4.1 Level File Structure
After multiple sorted write buffers are created and their total size reaches a threshold, data in all the sorted write buffers is written to level files on disk. The Partition Attributes Across (PAX) layout is used: records are first sorted by the sort key entry and records with the same sort key are stored with column files. The structure of a level file is as follows:

- Header: Contains reserved fields, table structure details, and transaction-related information.
- Sorted Col Data: Data is sorted by the sort key entry, where each sort key column sequentially stores the block data.
- Zonemap: Stores pre-aggregated information for the data, including the minimum, maximum, sum, and not-null count for each column.
- Indexes: Contains index information for the sorted col data, such as the number of sort key entries, the record count for each sort key entry, the file offset for data in blocks, checksums, etc.
- Footer: Stores the starting position of the zonemap, enabling the system to locate the pre-aggregation and indexing regions.
Zonemap and indexes are loaded into the memory during query operations for indexing purposes.
3.4.2 Level File Levels
The organization of level files is as follows:
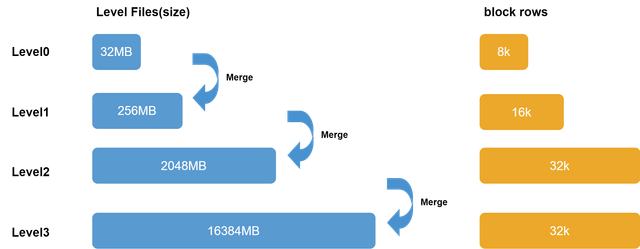
Level files are divided into 4 levels, from Level 0 to Level 3. The higher the level, the bigger the size of each level file. Data from the cache engine is divided into 32 MB chunks, compressed, and stored by partition in the level file at Level 0. Lower level files are merged to generate higher-level files. Consequently, files at lower levels are relatively newer, while files at higher levels are relatively older.
3.4.3 Level File Compaction
After multiple writes, data with the same sort key may become scattered across different level files. During queries, the system must load all relevant data blocks into memory and perform deduplication according to the configured strategy. To mitigate the performance impact of such fragmentation, the TSDB engine uses a level file compaction mechanism.
Compaction reduces the number of files through merging, eliminates outdated or duplicate data, improves compression efficiency, minimizes fragmented lookups, and ultimately enhances query performance and disk utilization.
File Compaction Mechanism
A compaction operation is triggered automatically when either of the following conditions is met:
- The number of level files at a given level exceeds 10.
- The total size of level files exceeds the threshold for a single file at the next level.
During compaction, deduplication is performed according to the
keepDuplicates parameter. If there are too many files, users can
also manually invoke the function triggerTSDBCompaction to
initiate compaction and reduce file count, thereby improving query
performance. The compaction status can be monitored using the function
getTSDBCompactionTaskStatus.
Note: Level file compaction is resource-intensive, consuming
significant CPU and disk I/O, and introduces write amplification. It runs in
single-threaded mode per volume. When multiple compaction tasks accumulate,
execution time can increase substantially. If compaction runs during peak
write periods, it may negatively impact overall system throughput. It is
recommended to schedule compaction during off-peak hours using
scheduleJob to trigger it manually at optimal
times.
4. TSDB Usage
Factors such as partitioning and indexing significantly affect the write and query performance of TSDB databases. Proper configuration during database and table creation is crucial. This chapter provides practical guidance on key configuration parameters and usage considerations to help users get started effectively.
4.1 Database Deployment
Before using the TSDB engine, configuration parameters can be adjusted as appropriate to fully leverage the system performance. This section primarily introduces several key parameters:
TSDBRedoLogDir: Specifies the directory for the TSDB redo log. To improve write efficiency, it is recommended to configure the TSDB redo log directory on an SSD.
TSDBCacheEngineSize: Sets the memory size of the TSDB cache engine. The default value is 1 (GB). In write-intensive scenarios, this parameter can be appropriately increased. If set too small, it may cause the cache engine to flush frequently, affecting system performance; If set too large, transaction redo during server startup could be time consuming in case of power outage or server shutdown.
TSDBLevelFileIndexCacheSize: Determines the upper limit of index data
(including level file indexes and zonemaps). The default is 5% of
maxMemSize. If set too low, it may cause frequent index replacement.
Among the indexes, zonemaps consume the most memory. Users can estimate the
memory usage based on number of partitions × number of sort keys × (4 ×
sum of byte sizes for all sort key fields), where 4 represents the
four types of pre-aggregated metrics: min, max, sum, and not-null-count.
TSDBAsyncSortingWorkerNum: A non-negative integer, default is 1, used to specify the number of worker threads for asynchronous sorting in the TSDB cache engine. This value can be increased appropriately to enhance write performance when CPU resources are sufficient.
TSDBCacheFlushWorkNum: The number of worker threads for flushing the TSDB cache engine. The default is the number of disk volumes specified by volumes. If the configured value is less than the number of volumes, the default will still be used. Usually left unchanged.
4.2 Creating a Database
The following script creates a COMPO-partitioned database and sets the engine parameter to TSDB.
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 100])
db = database(directory=dbName, partitionType=COMPO, partitionScheme=[db1, db2], engine="TSDB")Database-Table Mapping
For distributed databases storing partitioned tables, a one-database-one-table design is recommended. This is because sharing the same partition scheme across multiple large tables may lead to imbalanced partition sizes and degraded performance. For distributed databases storing dimension tables, a one-database-multiple-tables setup is recommended. These tables usually have only one partition and reside in memory once loaded, making centralized management more efficient.
Partition Design
TSDB uses partitions to parallelize reads, writes, queries, and maintenance operations. Appropriate partition sizing ensures optimal usage of memory, CPU, and I/O bandwidth. The recommended size for a single partition before compression in a TSDB database is 400 MB - 1 GB. If the partition granularity is too large, it may cause insufficient memory, lower query parallelism, and reduced update/delete efficiency. If too small, it may generate a large number of tasks, increasing node load; a large number of small files written individually, increasing system load; and metadata explosion on the controller.
Follow the steps to design a TSDB database:
- Using the recommended partition size as reference, first estimate the data
volume based on the number of records and field sizes, then compute the
number of partitions according to the partitioning scheme (e.g., a COMPO
partition of date + symbol HASH10 can be calculated as
number of days × 10), and finally calculate each partition's size bydata volume ÷ number of partitions. - Adjust the partition granularity as appropriate:
- Granularity too small: If VALUE partitioning is used, consider switching to RANGE partitioning (e.g., change from daily to monthly). If HASH partitioning is used, consider reducing the number of HASH partitions.
- Granularity too large: If RANGE partitioning is used, consider switching to value partitioning (e.g., change from yearly to monthly). If HASH partitioning is used, consider increasing the number of HASH partitions. If it is a single-level partition, consider using COMPO partitioning, where the newly added level is typically a HASH partition. For example, if a daily partition has overly large granularity, consider adding a second-level HASH partition based on stock code.
Concurrent Writes to the Same Partition
To support multi-threaded concurrent writes without partition conflicts causing
write failures, DolphinDB introduces the parameter atomic when creating a
database. The default is 'TRANS', which disallows concurrent writes to the same
CHUNK partition. When set to 'CHUNK', multi-threaded concurrent writes to the
same partition are allowed. The system still serializes write tasks internally.
When one thread is writing to a partition and other threads attempt to write to
the same partition, they will detect the conflict and retry. If retrying 250
times (with increasing wait intervals up to 1s, totaling around 5 minutes) still
fails, the write will ultimately fail. Setting atomic='CHUNK'
may compromise transactional atomicity. If a thread exceeds the retry limit,
that data portion will be lost, so this parameter should be set with caution.
In practice, if 'CHUNK' leads to data loss, it may be difficult for users to locate the exact partition. The following solutions are recommended for such cases:
- Use
tableInsertfor writing. This function returns the number of records written. Failed tasks can be identified based on the returned value. If the involved partitions are not overlapping, you can delete the relevant partition data and re-write. - If using the TSDB engine and the deduplication strategy is set to FIRST or LAST, you can directly resubmit failed thread tasks. The system will deduplicate the data, and queries will not return duplicates. This approach is not applicable if the deduplication strategy is ALL, and you can use the first solution instead.
4.3 Creating a Table
When creating tables in a TSDB database, the sortColumns parameter is required. The TSDB engine also supports optional parameters keepDuplicates, sortKeyMappingFunction, and softDelete.
// Function
createPartitionedTable(dbHandle, table, tableName, [partitionColumns], [compressMethods], [sortColumns], [keepDuplicates=ALL], [sortKeyMappingFunction], [softDelete=false])
// SQL
create table dbPath.tableName (
schema[columnDescription]
)
[partitioned by partitionColumns],
[sortColumns],
[keepDuplicates=ALL],
[sortKeyMappingFunction]The following example creates a distributed table in a TSDB database using the
function createPartitionedTable:
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=tbName, partitionColumns=`TradeDate`SecurityID, compressMethods={TradeTime:"delta"}, sortColumns=`SecurityID`TradeDate`TradeTime, keepDuplicates=ALL)Compression Methods
Apply appropriate compression algorithms (compressMethods) to fields:
- For highly repetitive strings, use the SYMBOL type. Note that the number of unique SYMBOL values per partition must not exceed 2^21 (2,097,152), otherwise an exception will be thrown.
- For time-series or sequential numeric data, the delta-of-delta algorithm can be used.
- The default algorithm for other fields is lz4.
Sort Columns
Ensure that the number of unique sort key values per partition is less than 1000. In financial scenarios, a common sortColumns combination is SecurityID + timestamp; in IoT scenarios, it is typically deviceID + timestamp. Since each sort key maintains index metadata, a higher number of sort keys results in more metadata overhead. In extreme cases, this can cause the database size to expand by up to 50 times. Therefore, it is not recommended to use primary keys or unique constraints as sortColumns.
Specify frequently-queried fields at the front of sortColumns. If filter conditions in queries include sort key fields, the system can quickly locate the index and corresponding data blocks to accelerate query performance. Because index keys are stored in memory in sorted order, placing frequently queried fields first enables fast binary search. Otherwise, the system must perform a full index scan in memory.
If sortColumns contains only one field, that field serves as the sort key, and data within each block is unordered. In this case, all blocks with the sort key will be scanned during queries. If sortColumns includes multiple fields, all but the last become the sort key. Data within each block is sorted by the last column. When a query includes a time filter, it can skip unnecessary blocks under each sort key.
The sort columns only supports integer, temporal, string, or symbol types. Sort keys cannot be of type TIME, TIMESTAMP, NANOTIME, or NANOTIMESTAMP.
Sort Key Dimensionality Reduction
If sortColumns settings cannot sufficiently reduce the number of sort keys per partition, you can specify the sortKeyMappingFunction parameter for dimensionality reduction.
For example, if data for 5,000 stocks is partitioned by date, setting
sortColumns to stock code and timestamp would produce approximately
5,000 unique sort key combinations per partition—far exceeding the recommended
limit of 1,000. You can use sortKeyMappingFunction=[hashBucket{,
500}] to reduce the combinations to 500.
Dimensionality reduction is applied to each sort key field, so the number of
functions specified must match the number of sort key fields. A commonly used
function is hashBucket, which maps values by hash. After
dimensionality reduction, you can use the getTSDBSortKeyEntry
function to check sort key distribution per partition.
Data Deduplication
In cases where multiple records share the same timestamp and deduplication is needed, set keepDuplicates=FIRST or LAST to retain either the first or last record per sortColumns combination.
- For high-frequency updates,
keepDuplicates=LASTis recommended due to its more efficient append-update mechanism. - For better query performance,
keepDuplicates=ALLis recommended, as other strategies introduce additional overhead during queries for in-memory deduplication. - When using
atomic=CHUNK, it is recommended to usekeepDuplicates=FIRSTorLAST. In this mode, if concurrent writes fail, you can reinsert the data directly without deleting the original entries.
5. TSDB Query Tuning Case
- CPU: 48 cores
- Memory: 128 GB
- Disk: HDD
- Deployment: Single-machine cluster with 2 data nodes
5.1 Number of Sort Keys
It is recommended that the number of sort keys in each partition not exceed 1,000.
Test Scenario
This test evaluates performance degradation in a scenario where deduplication is based on sort columns, with each sort key mapping to a minimal number of records.
Table Schema
A wide-format table containing 100 factor fields (factor1 to factor100).
| Field Name | Data Type | Description |
|---|---|---|
| tradeDate | DATE | |
| tradeTime | TIME | |
| ID | INT | Unique per date |
| factor1~factor100 | DOUBLE |
Partitioning Scheme
- Data volume: 5 days × 500,000 rows/day = 2.5 million rows (~1.9 GB)
- Partitioning: Value-partitioned by tradeDate
- Sort columns: ID, tradeDate, and tradeTime (where ID and tradeDate form sort key)
- Deduplication rule: keepDuplicates = LAST (keep only the latest record)
Performance Metrics (Before Optimization)
| Meric | Value | Query Script |
|---|---|---|
| Actual disk size | 17.05 GB | use opsgetTableDiskUsage(dbName,
tableName) |
| Number of sort keys | 2,500,000 | chunkIDs = exec chunkID from
pnodeRun(getChunksMeta{"/test_tsdb%"}) where dfsPath not
like "%tbl%" and dfsPath not like "%domain%"select count(*)
from
pnodeRun(getTSDBSortKeyEntry{chunkIDs}) |
| Query (top 10 rows) | 59.5 s | timer select top 10 * from
loadTable(dbName, tableName) |
| Point query by ID and tradeDate | 4.5 s | timer select * from loadTable(dbName,
tableName) where ID = 1 and tradeDate =
2023.03.09 |
Analysis
- High sort key cardinality increases index metadata size and memory usage.
- Fragmented data lowers read/write efficiency.
- Small blocks reduce compression efficiency.
To optimize the above scenario, dimensionality reduction can be performed on the
sort keys by setting the sortKeyMappingFunction. In this case,
dimensionality reduction is applied to the ID field using
hashBucket{,500} to reduce the number of sort keys per
partition to 500:
db.createPartitionedTable(table=tbSchema,tableName=tbName,partitionColumns=`tradeDate,sortColumns=`ID`tradeDate`TradeTime,keepDuplicates=LAST, sortKeyMappingFunction=[hashBucket{,500},])Performance Metrics (After Optimization)
| Meric | Value | Query Script |
|---|---|---|
| Actual disk size | 2.88 GB | use opsgetTableDiskUsage(dbName,
tableName) |
| Number of sort keys | 2,500 | chunkIDs = exec chunkID from
pnodeRun(getChunksMeta{"/test_tsdb%"}) where dfsPath not
like "%tbl%" and dfsPath not like "%domain%"select count(*)
from
pnodeRun(getTSDBSortKeyEntry{chunkIDs}) |
| Query (top 10 rows) | 104 ms | timer select top 10 * from
loadTable(dbName, tableName) |
| Point query by ID and tradeDate | 7.62 ms | timer select * from loadTable(dbName,
tableName) where ID = 1 and tradeDate =
2023.03.09 |
5.2 Number of Level Files
Test Scenario
This test evaluates query performance with varying keepDuplicates settings and level file compaction states.
Table Schema
| Field Name | Data Type |
|---|---|
| machineId | INT |
| datetime | TIMESTAMP |
| tag1~tag50 | DOUBLE |
Partitioning Scheme
- Data volume: 10 days × 100 million records/day = 1 billion records (~38 GB/day)
- Partitioning: COMPO-partitioned by datetime (VALUE) + machineId (HASH 100)
- Sort columns: machineId, datetime
- Deduplication ruls: ALL, FIRST, LAST
In practice, duplicate data is typically caused by device behavior or communication protocols, with a typical duplication rate of around 5%. This test simulates an IoT scenario with realistic data volume and duplication rate.
| Deduplication Rules | Data Volume | Disk (Before) | Disk (After) | Level Files (Before) | Level Files (After) |
|---|---|---|---|---|---|
| ALL | 1,000,000,000 | 357.43 GB | 347.50 GB |
|
|
| FIRST | 951,623,687 | 341.23 GB | 325.01 GB |
|
|
| LAST | 951,624,331 | 341.23 GB | 324.04 GB |
|
|
Test Metrics
Point query (by sort key):
select * from loadTable(dbName, tbName_all) where machineId=999| Deduplication Rules | Data Volume | Query Time Before (ms) | Query Time After (ms) |
|---|---|---|---|
| ALL | 9,812 | 32.2 | 28.5 |
| FIRST | 9,541 | 27.7 | 26.7 |
| LAST | 9,507 | 29.7 | 26.3 |
select * from loadTable(dbName, tbName_all) where machineId=999 and datetime=2023.07.10| Deduplication Rules | Data Volume | Query Time Before (ms) | Query Time After (ms) |
|---|---|---|---|
| ALL | 1,054 | 8.7 | 8.2 |
| FIRST | 916 | 7.6 | 6.6 |
| LAST | 968 | 8.1 | 6.8 |
select * from loadTable(dbName, tbName_all) where machineId=999 and datetime=2023.07.10 and datetime between 2023.07.10 09:00:01.000 and 2023.07.10 09:00:03.000| Deduplication Rules | Data Volume | Query Time Before Compaction (ms) | Query Time After Compaction (ms) |
|---|---|---|---|
| ALL | 202 | 6.2 | 6.1 |
| FIRST | 201 | 5.8 | 5.8 |
| LAST | 197 | 5.8 | 5.8 |
Query All Records in a Single Partition
select count(*) from loadTable(dbName, tbName)| Deduplication Rules | Data Volume | Query Time Before Compaction (ms) | Query Time After Compaction (ms) |
|---|---|---|---|
| ALL | 100,000,000 | 59,566.7 | 47,474.3 |
| FIRST | 95,161,440 | 54,275.1 | 46,069.2 |
| LAST | 95,161,940 | 57,954.2 | 44,443.1 |
Query Total Row Count (metadata match)
select count(*) from loadTable(dbName, tbName)| Deduplication Rules | Data Volume | Query Time Before Compaction (ms) | Query Time After Compaction (ms) |
|---|---|---|---|
| ALL | 1,000,000,000 | 218.9 | 216.8 |
| FIRST | 951,623,687 | 6,324.1 | 1,180.9 |
| LAST | 951,624,331 | 6,470.2 | 958.7 |
Analysis
(1) Query performance before and after level file compaction:
- In scenarios without deduplication (keepDuplicates=ALL), overall performance improvement is minor. However, for full partition scans, the reduced number of files results in roughly 20% improvement.
- In deduplication scenarios (keepDuplicates=FIRST / LAST):
- For queries hitting sort keys, the performance is almost unaffected by level file compaction.
- For partition scan queries, the performance improves slightly after compaction, by approximately 15%.
- For metadata-based queries, the performance improves significantly after compaction, by approximately 6×.
The performance improvement from level file compaction stems mainly from:
- Fewer files reduce disk seek time (although seek time is negligible in large queries).
- File compaction reduces duplicate data, which also reduces deduplication time.
- Fewer files reduce traversal overhead during queries.
Deduplication in level files is performed during the compaction phase. If duplicate records remain on disk, the engine performs in-memory deduplication during queries, which becomes increasingly expensive with higher data redundancy.
(2) Query performance with different deduplication strategies:
- For queries hitting sort keys, the performance using different deduplication strategies is similar.
- For partition scan queries, the ALL strategy performs slightly worse than FIRST and LAST, due to the deduplication overhead in FIRST and LAST.
- For metadata-based queries, ALL significantly outperforms FIRST and LAST (up to 30× faster), because ALL requires only metadata reads, whereas FIRST and LAST require loading and processing data for deduplication.
The performance impact of different deduplication strategies is mainly due to:
- ALL stores more files, which could marginally increase seek time—but this impact is minimal in large-query contexts.
- ALL avoids deduplication during query execution. FIRST and LAST must load all relevant records and perform in-memory deduplication, which is computationally expensive.
Conclusion
If the number of level files is high and deduplication is enabled, level file compaction can significantly improve performance for partition scan and metadata-based queries, while point queries experience minimal benefit. If no deduplication strategy is set or the data duplication rate is low, the impact of file compaction on performance is limited.
The TSDB engine includes automatic compaction mechanism for level files, which in
most cases prevents the file count from becoming a performance bottleneck.
However, if the number of level files remains high even after automatic
compaction, and the data is no longer being modified or appended, users can
manually trigger compaction using the triggerTSDBCompaction
function. The compaction status can be monitored via
getTSDBCompactionTaskStatus.
6. Conclusion
Compared to the OLAP engine, the TSDB engine has a more complex internal implementation and offers users a wider range of configuration options. To fully utilize TSDB’s performance advantages, it is essential to configure deduplication mechanisms and sort columns appropriately based on the characteristics of your data and query patterns.
Key Considerations When Using the TSDB Engine:
- Set the sort columns appropriately (a maximum of 4 columns is recommended). A general principle is to ensure that the number of sort key combinations within each partition does not exceed 2,000, and that the data volume associated with each sort key is not too small.
- If query performance is suboptimal, you can investigate performance issues at
the engine level from two perspectives:
- Check whether the number of sort keys is too large (you can specify sortKeyMappingFunction during distributed table creation to reduce dimensionality).
- Check whether the number of level files is too high (you can manually
call
triggerTSDBCompactionto trigger compaction and reduce the number of level files).
Appendix
TSDB Configuration Reference
TSDB
| Parameter | Description |
|---|---|
| TSDBRedoLogDir=<HomeDir>/log/TSDBRedo | The directory of the redo log of TSDB engine. The default value is <HomeDir>/log/TSDBRedo. In cluster mode, it is necessary to ensure that different TSDBRedoLogDir are configured on the data nodes of the same machine. |
TSDBMeta (including level file metadata) is stored in <HomeDir>/log, and transaction data is stored in <HomeDir>/storage/CHUNKS. To configure this parameter:
- Use the relative paths, i.e., do not start with '/';
- Include <ALIAS> in the path: /home/xxx/<ALIAS>/redolog;
- Configure for each node separately: node1.TSDBRedoLogDir=/home/xxx/node1/redolog, node2.TSDBRedoLogDir=/home/xxx/node2/redolog.
The TSDB engine caches SYMBOL base during read/write operations. An LRU (Least Recently Used) policy is employed to manage this cache, with two configuration parameters determining when to evict SYMBOL base cache based on time or capacity limits. Only SYMBOL base entries absent from both the cache engine and ongoing transactions will be evicted based on LRU.
| Parameter | Description | Node |
|---|---|---|
| TSDBSymbolBaseEvictTime=3600 | A positive integer indicating the maximum amount of time (in seconds) to keep cached SYMBOL base entries before they are evicted. The default value is 3600. When exceeded, the system evicts the cached SYMBOL base entries. | data node |
| TSDBCachedSymbolBaseCapacity | A positive number indicating the maximum capacity (in GB) for cached SYMBOL base. The default value is 5% of maxMemSize, with a 128MB minimum. When exceeded, the system evicts the entries that hasn't been accessed for the longest period first, until the cache size meets the limit. | data node |
| TSDBCacheEngineSize | A positive number indicating the capacity (in GB) of the TSDB cache engine, which must not exceed 50% of the node's maxMemSize. The default value is 1. When the cache engine's memory usage reaches half of the set value, the system begins flushing data to disk, allowing data to continue being written. Once the cache engine's memory usage reaches the set value, writes will be blocked. If the parameter is set too small, data in the cache engine may be flushed to disk too frequently, thus affecting the write performance; If set too high, a large volume of cached data is not flushed to disk until it reaches half of TSDBCacheEngineSize (or after 10 minutes). If power failure or shutdown occurs in such cases, numerous redo logs are to be replayed when the system is restarting, causing a slow startup. | data node |
In the TSDB engine, the data writing process involves three stages: sorting, compaction, and flushing. The following parameters can be specified to configure the data writing process:
| Parameter | Description |
|---|---|
| TSDBAsyncSortingWorkerNum=1 | A non-negative integer indicating the number of threads for asynchronous sorting in the TSDB cache engine. The default value is 1. Data written to the TSDB cache engine are sorted by sortColumns. The tasks of writing and sorting data can be processed either synchronously or asynchronously and the asynchronous mode optimizes writing performance. Set it to 0 to enable the synchronous mode. |
| TSDBCacheTableBufferThreshold=16384 | The threshold for batch sorting cached data in the TSDB engine. Once the number of cached records reaches TSDBCacheTableBufferThreshold, the cache engine initiates the sorting. |
| TSDBCacheFlushWorkNum | The number of threads for the flushing process of the TSDB cache engine. The default value is the number of disk volumes configured by parameter volumes. If volumes is less than the number of disk volumes, TSDBCacheFlushWorkNum is set to default. |
| TSDBLevelFileIndexCacheSize=5% * maxMemSize | The upper limit of the size (in GB) of level file metadata of the TSDB engine. It is of floating type. The default value is 5% of the maximum memory for DolphinDB (set by maxMemSize), and the minimum value is 0.1 (GB). If exceeded, the system replaces the least frequently accessed indices based on access time. |
| TSDBLevelFileIndexCacheInvalidPercent=0.95 | The threshold for caching algorithm for the level file index in the TSDB engine. The default value is 0.95. |
| allowTSDBLevel3Compaction=false | Whether to allow compaction of level 3 files of TSDB
storage engine.
|
| TSDBVectorIndexCacheSize=0 | The TSDB engine caches vector indexes to improve the query performance. The cache size can be set using the configuration parameter TSDBVectorIndexCacheSize. It is a non-negative floating-point number specifying the size of the vector index cache in GB. To enable the cache, set TSDBVectorIndexCacheSize to a positive number. The default value is 0, indicating that the cache is disabled. |
| compactWorkerNumPerVolume=1 | The size of worker pool for the level file compaction on each volume. The default value is 1. This parameter is added since version 2.00.11 to control over resource usage, compaction speeds, and load balancing across volumes. |
Maintenance Function Reference
- triggerTSDBCompaction: Triggers level file compaction.
- getTSDBCompactionTaskStatus: Gets the status of the compaction task.
- enableTSDBAsyncSorting: Enables asynchronous sorting.
- disableTSDBAsyncSorting: Disables asynchronous sorting.
- flushTSDBCache: Forces a flush of data in the TSDB cache engine to disk.
- setTSDBCacheEngineSize: Sets the memory size of the TSDB cache engine.
- getTSDBCacheEngineSize: Gets the memory size of the TSDB cache engine.
- getLevelFileIndexCacheStatus: Gets the memory usage status of all level file indexes.
- invalidateLevelIndexCache: Manually clears the index cache.
- getTSDBCachedSymbolBaseMemSize: Gets the cache size of dictionary encoding for SYMBOL fields in the TSDB engine.
- clearAllTSDBSymbolBaseCache: Clears the cache for dictionary encoding of SYMBOL fields.
- getTSDBMetaData: Gets metadata information of TSDB engine chunks.
- getTSDBSortKeyEntry: Gets the sort key information of chunks already written to disk in the TSDB engine.
For example, to trigger level file compaction across all partitions in the cluster:
// Replace dbName with your actual database name
chunkIDs = exec * from pnodeRun(getChunksMeta{"/dbName/%"}) where type=1
for(chunkID in chunkIDs){
pnodeRun(triggerTSDBCompaction{chunkID})
}
// Check if Level File compaction is completed
select * from pnodeRun(getTSDBCompactionTaskStatus) where endTime is nullQ&A
Q: Error: “TSDB engine is not enabled.”
A: First check whether the server version is ≥2.00. TSDB is unsupported in version 1.30. Ensure the configuration file includes the TSDBCacheEngineSize parameter.
Q: Updated TSDB data appears at the end of the table instead of being time-sorted.
A: TSDB maintains order within individual level files only; cross-file
order is not guaranteed. You can manually trigger level file compaction using
the triggerTSDBCompaction function.
Q: Can TSDB deduplicate on write using sort columns as the deduplication key?
A:
- If the deduplication key contains only one field, it is not recommended to set it as sortColumns, because this would make it a sort key. After deduplication, one sort key value maps to one record, which leads to index bloat and degrades query performance.
- If the deduplication key has multiple fields, assess the data volume per sort key. If the volume is too small, it’s also not recommended to use them as sortColumns.
It is recommended to use the upsert! method for write-time
deduplication.
Q: Why TSDB query performance is below expectations?
A:
- Check whether the sort keys are appropriately set. You can use the
getTSDBSortKeyEntryfunction to check details. - Check whether the level file index cache is too small. Insufficient cache leads to frequent replacement on wide-range queries. Increase the value of TSDBLevelFileIndexCacheSize and restart the cluster for changes to take effect.