Efficient Storage and Querying of News Data Using TextDB
In the era of information explosion, efficiently managing and searching news data has become a key challenge for every data analyst. DolphinDB, as a powerful data processing platform, provides rich tools to read, store, and retrieve various types of news files. This tutorial walks you through how to handle news data with special formats in DolphinDB and introduces a variety of storage schemes under its multi-model storage architecture. We will also analyze the performance and accuracy of different storage methods in text retrieval, demonstrating the unique advantages and optimal use cases of using TextDB for storing and querying news data.
DolphinDB supports the TextDB engine starting from version 3.00.2. All examples in this tutorial require DolphinDB server version 3.00.2 or later.
1. News Data Processing
News data typically refers to unstructured or semi-structured news primarily composed of text, such as market-related news, announcements, research reports, and social media content. These data may affect asset prices, market sentiment, or investment decisions. In DolphinDB, news data usually need to be processed into a specific format and stored in distributed tables for further usage.
1.1 News File Format
We use a JSONL-formatted news file as an example to demonstrate how to process, store, and utilize news data. In a JSONL file, each line is a JSON object representing an individual news record. A sample line in our tutorial:
{
"msgType": 3,
"dsCode": "116984908",
"scrapingTime": 1696089600000,
"delFlag": 0,
"rid": "c2d00b6723d54950ac06cb7b414a49b6",
"title": "Biomedicine...",
"_ext": {"index": "wechat_orginal_warrenq", "type": "wechat_orginal_warrenq"},
"sid": "897594237461088",
"newsUrl": "http://mp.weixin.qq.com/s?__biz=476E295a2edd",
"host": "mp.weixin.qq.com",
"id": "897594237461088",
"pushTime": "09:10:53",
"sector": "http://mp.weixin.qq.com",
"_hitScore": "",
"compared": 1,
"industryName": "Biomedicine",
"nature": "",
"introduce": "In-depth coverage of biomedical research and pharmaceutical innovations",
"updateUser": 1,
"updateTime": "2023-10-01 09:10:53",
"title_disp": "Biomedicine...",
"contentTxt_disp": "## Panasonic Energy...",
"repeatFlag": 0,
"msgSourceUrl": "http://mp.weixin.qq.com",
"collectType": 1,
"newsId": "1801450915567536",
"contentTxt": "## Panasonic Energy...",
"createTime": "2023-10-01 09:10:53",
"createUser": 1,
"pushDate": "2023-10-01",
"_id": "c2d00b6723d54950ac06cb7b414a49b6",
"mediaSource": "Pharma Trends",
"syncStatus": "init"
}1.2 Parsing News Files
In DolphinDB, you can use the readLines function to batch read
JSONL format files, ultimately obtaining a string vector containing the complete
file content:
// Read JSONL file into a vector, parameter is the file path
filePath = "./example.jsonl"
def readJsonl(filePath){
f = file(filePath)
jsonl = array(STRING,0,100)
do{
x = f.readLines()
jsonl.append!(x)
}
while(x.size()==1024)
f.close()
return jsonl
}This function returns a vector that stores JSON strings, as shown in the figure below:

For JSON strings, you can use the parseExpr function to convert
them to dictionaries, and use each for vectorized processing to
convert the JSON string vector into a dictionary vector:
// Parse string vector into dictionary vector, parameter is the string vector storing JSON
def parseJsonl(jsonl){
dictionary = each(eval,parseExpr(jsonl))
return dictionary
}For the dictionary vector returned from the above function, first filter the
fields that need to be stored, then use the transpose function
to convert the dictionary to a table, and use the unionAll
function to merge them. Finally, convert certain fields to the required data
types to obtain the final result:
// Extract fields to be stored, parameters are fields to store and original dictionary
def getColumns(cols, d){
newD = dict(STRING, ANY)
newD[cols] = d[cols]
return newD
}
// Convert filtered dictionary vectors into tables one by one and merge them, then convert data types of certain fields according to requirements to get the final result
// Parameters are fields to store, original dictionary vector, and data type conversion dictionary
def transDict(columns, dictionary, transCols){
table = unionAll(each(transpose, eachRight(getColumns, columns, dictionary)), false)
for (col in transCols.keys()){
a = <exec temporalParse(_$col, transCols[col]) as m from table>.eval()
replaceColumn!(table, col, a)
}
return table
}In the case of this tutorial, we need to store the fields msgType, title, newsUrl, host, industryName, contentTxt_disp, createTime, pushDate, and mediaSource. createTime and pushDate need to be converted to corresponding time types, so the input parameters columns and transCols are as follows:
columns = `msgType`title`newsUrl`host`industryName`contentTxt_disp`createTime`pushDate`mediaSource
cols = `pushDate`createTime
type = ["yyyy-MM-dd","yyyy-MM-dd HH:mm:ss"]
transCols = dict(cols, type)The final result after parsing:

Through the above steps, you can convert a JSONL file into an in-memory table for subsequent writing to distributed tables.
The complete code for this section is provided in the Appendix.
2. News Data Storage
Based on DolphinDB’s multi-model storage architecture, users can flexibly choose the appropriate storage engine according to their specific scenarios to optimize performance. The TSDB engine supports storing text data but does not support text indexing, making it suitable for scenarios where text is primarily stored but queried infrequently. In contrast, the PKEY engine supports building inverted indexes on text columns, significantly improving performance for full-text search operations. This meets the needs of modern applications for efficient retrieval and fast response over massive text data.
2.1 Storage with TSDB Engine
News data can be treated as a special type of time series data and stored using the TSDB engine, which is designed for efficient storage and analysis of time series data.
Before creating databases and tables, you can estimate the daily data volume
using SQL and the strlen function to determine the partitioning
scheme:
// Get the total bytes of all string type fields within a day
stringCols = exec name from t.schema().colDefs where typeString == "STRING"
len = select sum(rowLen)\nunique(pushDate)\1024\1024 from <select pushDate, sum(_$$stringCols) as rowLen from strlen(t)>.eval()According to the estimation results, the daily data volume used in this tutorial
is approximately 7 MB. Therefore, we use createTime as the
partitioning column and apply monthly value partitioning to ensure each
partition remains within a reasonable size range of 100 MB to 1 GB.
The TSDB engine allows frequently queried fields to be configured as index
columns in sortColumns to enhance query performance. In this
example, mediaSource and title are commonly
used query fields, so they are included as index columns, with
createTime serving as the time column in
sortColumns.
If deduplication is required based on sortColumns, you can set
the keepDuplicates parameter to FIRST or
LAST in the table creation statement. For more details,
refer to createPartitionedTable.
Based on the above design, the database and table creation statements are as follows:
//Create database and table (TSDB)
if (existsDatabase("dfs://news_TSDB"))
{
dropDatabase("dfs://news_TSDB")
}
db = database(directory="dfs://news_TSDB", partitionType=VALUE, partitionScheme=2020.01M..2020.02M,engine='TSDB')
data = createPartitionedTable(
dbHandle = database("dfs://news_TSDB"),
table = table(1:0,`pushDate`createTime`mediaSource`contentTxt_disp`industryName`host`newsUrl`title`msgType,[DATE,DATETIME,STRING,STRING,STRING,STRING,STRING,STRING,INT]),
tableName = `data,
partitionColumns = `createTime,
sortColumns = [`mediaSource,`title,`createTime],
sortKeyMappingFunction = [hashBucket{,25},hashBucket{,25}])2.2 Storage with PKEY Engine
The PKEY engine enforces primary key uniqueness, supports real-time updates and efficient querying, making it well-suited for storing news data.
Since the recommended partition size for the PKEY engine is the same as that of
the TSDB engine, we continue to use the same partitioning
strategy—createTime as the partitioning column with monthly
value partitioning.
The PKEY engine allows you to define primary key columns. When new records share
the same primary key, they overwrite existing records, thereby achieving
deduplication. In this example, the combination of createTime,
mediaSource, and newsUrl uniquely
identifies a record, so these fields are specified as the
primaryKey.
When using the PKEY engine to store news data, you can leverage TextDB, introduced in version 3.00.2. TextDB enables the creation of inverted indexes on text columns, significantly improving full-text search performance. This is especially beneficial for modern applications that require efficient querying of massive volumes of text data.
For the PKEY engine, you can configure text indexes on non-primary key columns
via the indexesparameter. This enables index-based text search on those
fields and enhances query efficiency. In this tutorial, both
contentTxt_disp and title are commonly
queried text fields that are not part of the primary keys, so text indexes can
be applied to them.
Based on the above design, the database and table creation statements are as follows:
//Create database and table (PKEY)
if (existsDatabase("dfs://news_PKEY"))
{
dropDatabase("dfs://news_PKEY")
}
db2 = database(directory="dfs://news_PKEY", partitionType=VALUE, partitionScheme=2020.01M..2020.02M,engine='PKEY')
data2 = createPartitionedTable(
dbHandle = database("dfs://news_PKEY"),
table = table(1:0,`pushDate`createTime`mediaSource`contentTxt_disp`industryName`host`newsUrl`title`msgType,[DATE,DATETIME,STRING,STRING,STRING,STRING,STRING,STRING,INT]),
tableName = `data,
partitionColumns = `createTime,
primaryKey = `createTime`mediaSource`newsUrl,
indexes = {"contentTxt_disp":"textIndex(parser=chinese,full=true,lowercase=true,stem=false)",
"title":"textIndex(parser=chinese,full=true,lowercase=true,stem=false)"})3. Storage Methods and Text Search
After writing news data to distributed tables, users often need to search for specific content. When dealing with large data volumes, query performance and accuracy become especially critical.
In engines other than TextDB, text search typically relies on the
like function. In contrast, TextDB provides a suite of
functions specifically designed for text search, significantly improving query
efficiency. These functions are applicable only to columns with text indexes and
must be used within the WHERE clause of a query statement. They cannot be used
independently.
For a detailed list of supported text search functions, refer to: TextDB.
3.1 Search Performance
Based on the code provided in the previous section, we created distributed tables
using two different storage engines and imported the same dataset into both. We
then performed a series of text search tests to compare the performance of the
like function in the TSDB engine with that of dedicated
text search functions in the TextDB engine.
The dataset used in the tests is simulated news data from October 2023, containing 100,000 records and occupying approximately 400 MB before compression.
We begin with a single-word search, querying records from October 2023 where the
contentTxt_disp field contains the word "Tesla".
// Performance Test: Search Single Given Word
timer t1 = select * from loadTable("dfs://news_TSDB", "data") where month(createTime)=2023.10M and contentTxt_disp like "%Tesla%"
>> Time elapsed: 1230.376 ms
timer t2 = select * from loadTable("dfs://news_PKEY", "data") where month(createTime)=2023.10M and matchAll(contentTxt_disp,"Tesla")
>> Time elapsed: 63.552 msNext, we conduct a multi-word search test containing all specified words. Query
data from October 2023 where the contentTxt_disp field contains
both "OpenAI" and "intelligence":
// Performance Test: Search Content Containing All Given Words
timer t1 = select * from loadTable("dfs://news_TSDB", "data") where month(createTime)=2023.10M and contentTxt_disp like "%OpenAI%" and contentTxt_disp like "%intelligence%"
>> Time elapsed: 1432.834 ms
timer t2 = select * from loadTable("dfs://news_PKEY", "data") where month(createTime)=2023.10M and matchAll(contentTxt_disp, "OpenAI intelligence")
>> Time elapsed: 37.248 msFinally, we conduct a multi-word retrieval test containing any of the given
words. Query data from October 2023 where the contentTxt_disp
field contains "Speed" or "Throughput":
// Performance Test: Search Content Containing Any Given Words
timer t1 = select * from loadTable("dfs://news_TSDB", "data") where month(createTime)=2023.10M and contentTxt_disp like "%Speed%" or contentTxt_disp like "%Throughput%"
>> Time elapsed: 2082.541 ms
timer t2 = select * from loadTable("dfs://news_PKEY", "data") where month(createTime)=2023.10M and matchAny(contentTxt_disp,"Speed Throughput")
>> Time elapsed: 499.213 msThe test results are summarized in the table below:
| TSDB | TextDB | |
|---|---|---|
| Single Keyword Search | 1230.376 ms | 63.552 ms |
| Search Matching All Keywords | 1432.834 ms | 37.248 ms |
| Search Matching Any Keyword | 2082.541 ms | 499.213ms |
The results clearly show that TextDB's specialized query functions offer significantly better search performance. As the dataset grows and matching records become sparser, the performance advantage over TSDB becomes even more pronounced.
3.2 Search Accuracy
TextDB uses tokenizers to split text into sequences of words and builds inverted indexes to enhance search efficiency. As a result, for most text data that can be accurately tokenized, TextDB delivers precise search results.
For example, we query the number of records from October 2023 where the
title field contains the word "Biomedicine", using both
TSDB and TextDB:
t1 = select count(*) from loadTable("dfs://news_TSDB", "data") where month(createTime) = 2023.10M and title like "%Biomedicine%"
// 24985 records
t2 = select count(*) from loadTable("dfs://news_PKEY", "data") where month(createTime) = 2023.10M and matchAll(title, "Biomedicine")
// 24985 recordsAs shown above, TextDB returns an accurate match count.
However, for more complex texts, tokenization may be imperfect. In such cases, search results in TextDB might not be fully accurate.
For instance, the word "art" is commonly used as an independent search term, but
it may also appear as a prefix or suffix within other words. We execute a query
on October 2023 data to search records where the
contentTxt_disp field contains the single word "art", or
words starting with "art", using both engines:
t1 = select count(*) from loadTable("dfs://news_TSDB", "data") where month(createTime) = 2023.10M and contentTxt_disp like "% art%"
// 24971 records
t2 = select count(*) from loadTable("dfs://news_PKEY", "data") where month(createTime) = 2023.10M and matchAll(contentTxt_disp,"art")
// 0 recordsIn this example, since the word does not appear as a standalone token, TextDB returns 0 results, but TSDB can search for results with "art" as a prefix.
To better handle such issues, TextDB provides multiple functions that
significantly improve text search efficiency while maintaining accuracy as much
as possible, achieving efficient text search. For example, in TextDB, you can
use the matchPrefix function to query text containing content
with "art" as a prefix:
t3 = select count(*) from loadTable("dfs://news_PKEY", "data") where month(createTime) = 2023.10M and matchPrefix(contentTxt_disp, "art")
// 24971 recordsAs we can see, the query result is perfectly accurate.
4. Application Scenarios
Based on the comparison in the previous section, TextDB is particularly well-suited for scenarios where high search performance is required, but strict accuracy is not critical—especially when working with large volumes of data.
The following two examples illustrate typical application scenarios where TextDB excels.
4.1 News Hotspot Analysis
In news hotspot analysis, TextDB is widely used for its fuzzy matching capabilities and fast query performance. Rather than requiring exact matches, hotspot analysis emphasizes efficiently counting the occurrences of trending keywords across large datasets, making TextDB an ideal fit for this purpose.
For example, using the news data from this tutorial, we calculate the proportion
of records from October 2023 in which the contentTxt_disp field
contains the keyword “Lithography”.
num = exec count(*) from loadTable("dfs://news_PKEY", "data") where month(createTime) = 2023.10M and matchAll(contentTxt_disp,"Lithography")
all = exec count(*) from loadTable("dfs://news_PKEY", "data") where month(createTime) = 2023.10M
num \ all
// 0.14In the above scenario, text querying based on TextDB can quickly obtain the proportion of hotspot keyword content from large volumes of news data without having to process individual records in detail, thereby determining the ratio of trending news for hotspot analysis.
4.2 Real-time Sentiment Monitoring
In sentiment monitoring scenarios, billions of user-generated short texts may need to be processed each day. Such applications often rely on fuzzy matching to rapidly identify relevant content and extract high-frequency keywords. TextDB is also suitable for such scenarios.
For example, using the news data from this tutorial, we calculate the hourly
frequency of the keyword "Intel" in the contentTxt_disp field
on October 23, 2023, and visualize the frequency trend over time:
num = select count(*) as number from loadTable("dfs://news_PKEY", "data") where date(createTime) = 2023.10.23 and matchAll(contentTxt_disp,"Intel") group by interval(createTime,1H,`null) as time
all = select count(*) as total from loadTable("dfs://news_PKEY", "data") where date(createTime) = 2023.10.23 group by interval(createTime,1H,`null) as time
p = select time, number\total as prob from num left join all on num.time = all.time
plot(p.prob, p.time, , LINE)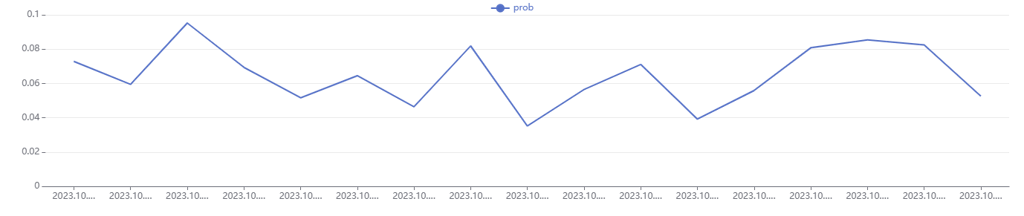
In the above scenario, text querying based on TextDB can quickly calculate the frequency of keyword occurrences across different time intervals without needing to focus on specific data quantities and content. This makes it an effective solution for real-time sentiment analysis and event tracking.
5. Summary
This article systematically explains how to parse and store news data in DolphinDB, and based on DolphinDB's multi-model storage architecture, provides guidance on selecting appropriate storage engines according to specific requirements. It then presents detailed comparative tests showcasing the high performance of the TextDB engine in text search scenarios and illustrates typical use cases where TextDB is most effective. In appropriate scenarios, TextDB can serve as a powerful tool for users to efficiently store and query news data.