Redo Log and Cache Engine
This tutorial introduces how redo log and cache engine work in DolphinDB.
Note:
- They only work with DFS databases, not stream tables.
- Redo log and cache engine must be enabled in TSDB engine.
- Redo log is optional for OLAP engine. The cache engine, however, must be enabled once the redo log is enabled.
1. Understanding Redo Log/Cache Engine
1.1. What is Redo Log?
The concept of redo log in DolphinDB is similar to write-ahead logging (WAL) which is a family of techniques for providing atomicity and durability in relational database systems.
In a nutshell, the core of the redo log is that changes to database files must be written only after persisting all log records describing the changes.
As a result, you can recover the database from a crash by using the log records. Any changes that have not been made to the data pages can be reapplied using the log records.
1.2. What is Cache Engine?
Cache engine in DolphinDB serves as the write caching, which is designed to improve write throughput.
When writing to a file, the time to insert 1 record and 1000 records is basically the same. Most of the time is spent opening and closing the file. With cache engine enabled, data is written to the cache first, and then asynchronously written to the disk in batches.
1.3. How Does Redo Log/Cache Engine Work?
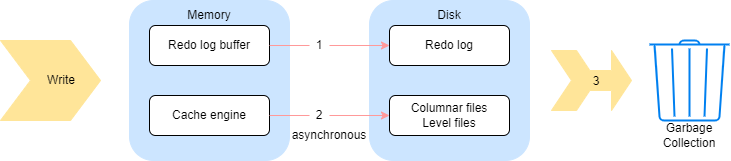
The above three steps in the figure briefly show the process of writing data:
(1) Changes made to the database are logged and persisted into the redo log. Each transaction is stored in one file.
(2) Data is written to the cache engine, and then asynchronously written to columnar files (OLAP) and level files (TSDB).
(3) Reclaim the cache engine and the redo log after transaction completed.
To recover data from redo logs in the event of a crash or outage, redo logs can only be reclaimed after the associated entries are removed from the cache engine and written to disk. Therefore, in step 3, cache engine is reclaimed first.
Garbage collection (GC) of the cache engine completes once the data is flushed to disk successfully. The cache engine is reclaimed:
- at a fixed interval
- For OLAP engine, the system checks whether to reclaim every 60s.
- For TSDB engine, the system checks whether to reclaim every 30s.
- when files reach a fixed size
- For OLAP engine, when the data in the cache reaches 30% of the
OLAPCacheEngineSize, it is written to the column file on the disk. - For TSDB engine, when the data in the cache reaches 50% of
TSDBCacheEngineSize, it is written to the level file (similar to leveldb's flush memtable).
- For OLAP engine, when the data in the cache reaches 30% of the
- manually using
flushOLAPCache,flushTSDBCache
Then redo log is reclaimed:
- at a fixed interval (configured with
redoLogPurgeInterval) - when files reach a fixed size (configured with
redoLogPurgeLimit)
Therefore, it is not suggested setting cache engine size too large, otherwise completed transactions are cached in the cache engine for a long time without triggering GC, and the redo log cannot be reclaimed, resulting in the continuous increasing space of the redo log.
1.4. Why Enable the Redo Log/Cache Engine?
The redo log cannot only maintain data consistency in the event of a power outage, but also optimize the performance of writes.
Consider, write data to 100 partitions (of the OLAP database) at a time, and each partition has 200 columns, then you have 20,000 columnar files to be written together. If these columnar files are all on one HDD, the synchronous writes will lead to long disk access time. Flushing data with redo log enabled greatly reduces the access time and optimizes the write performance.
In addition, using redo log leads to a better performance on sequential writes. Only log records need to be flushed to disk when the transaction commits. It is much optimized for the OLAP engine.
The cache engine is designed to improve write throughput with less frequent disk writes, especially when there are too many columns. The reason why cache engine optimizes the performance lies in batch writes.
DolphinDB adopts column-based storage where each column in a partition is stored in a separate file. If there are too many columns (eg. thousands of metrics in IoT scenarios), you need to operate (open, write-in, close, etc.) on thousands of physical files each time. Therefore, the data is cached in small amounts several times, and then written in batches. This could spare the overheads of opening and closing files, improving the overall performance of writes.
2. Configuration Options
2.1. Planning the Redo Log
Configuration parameters:
- dataSync: Decide whether to enable redo log. Redo log is not enabled by default. The default value is 0. To enable it, set dataSync=1.
- redoLogDir: The directory of the redo log. It is recommended to set it to an SSD for optimal performance. The default value is <homeDir>/log/redoLog (determined by the home parameter). For cluster mode, set directories for each data node separately to avoid writing errors.
- redoLogPurgeLimit: The maximum disk space (in GB) for the redo log. The default value is 4. If the size of the redo log exceeds redoLogPurgeLimit, the system will automatically purge the redo log.
- redoLogPurgeInterval: Remove the redo log of transactions whose data have been persisted at intervals (in seconds) specified by redoLogPurgeInterval. The default value is 30.
- TSDBRedoLogDir: The directory of the redo log of TSDB engine. The default value is <HomeDir>/log/TSDBRedo.
It should be noted whether parameters are configured in files on the controller or data nodes.
Functions/Commands:
- getRedoLogGCStat: Get the status of garbage collection of the redo log.
- imtForceGCRedolog: Cancel the garbage collection of the specified transaction so that redo logs of the subsequent transactions can be removed.
2.2. Planning the Cache Engine
OLAP engine
Configuration parameters:
- OLAPCacheEngineSize: The capacity of the cache engine in units of GB. The default value is 0, indicating the cache engine is not enabled. After cache engine is enabled, i.e., OLAPCacheEngineSize>0, data is asynchronously written to disk when data in cache exceeds 30% of OLAPCacheEngineSize.
Functions/Commands:
- flushOLAPCacheEngine: Forcibly flush the data of completed transactions cached in the OLAP cache engine to the database.
- getOLAPCacheEngineSize: Obtain the memory status (in bytes) of the cache engine.
- setOLAPCacheEngineSize: Modify the capacity of the OLAP cache engine online.
- getOLAPCacheEngineStat: Get the status of the OLAP cache engine.
TSDB engine
Configuration parameters:
- TSDBCacheEngineSize: The capacity of the TSDB cache engine in units of GB. The default value is 1G. The memory used by the cache engine may be twice as big as the set value. An extra memory block will be allocated to cache the incoming data while the original data is being written to disk. If the flush process is not fast enough, the newly allocated memory may also reach TSDBCacheEngineSize.
Functions/Commands:
- flushTSDBCache: Forcibly flush the completed transactions cached in the TSDB cache engine to the database.
- getTSDBCacheEngineSize: Get the maximum memory (in bytes) allocated to the TSDB cache engine.
- setTSDBCacheEngineSize: Modify the capacity of the TSDB cache engine online.
3. Possible Impacts on Performance
3.1. Disk Writes and Memory Size
- Enabling the redo log leads to higher disk usage. Additional disk resources are allocated for the redo log.
- Enabling cache engine can optimize the disk I/O performance. Writing to disk in batches reduces disk writes.
- Enabling cache engine results in higher memory usage. Data that has not been written to disk is cached in cache engine, occupying more memory.
3.2. Startup of Nodes
Excessive redo logs stored in the disk may result in a slow startup. It can be explained from the following aspects:
- The specified disk space for redo logs is too large, so that the redo log cannot be reclaimed.
- The specified interval to remove redo logs is too long to trigger garbage collection.
- The specified cache engine memory size is too large, so that the cache engine cannot be reclaimed, thereby blocking garbage collection of the redo log.
- Redo log files are stored on HDD, and it costs too much time to read these files when the cluster starts.
Note: Replaying redo logs may take a long time when starting up. You can check the progress by searching "transactions to be replayed have been completed" in the log.
3.3. Suggestions for Performance Tuning
To improve the overall performance of writing to the database, it is recommended that:
- Set all directories storing metadata and redo logs on SSDs, and use industrial SSDs if possible. Specific suggestions are as follows:
dfsMetaDir: The directory for the metadata on the controller node. Set it to SSD in controller.cfg.
chunkMetaDir: The directory for the metadata on each data node. Set it to SSD in cluster.cfg.
redoLogDir: The directory of the redo log. Set it to SSD in cluster.cfg.
persistenceDir: The directory where shared streaming tables are persisted to. Set it to SSD in cluster.cfg. In the cluster mode, persistenceDir should be specified for each data node separately.
logFile: The log file of each node. It displays the running status, error messages, etc. It can be specified on HDD in controller.cfg, agent.cfg, cluster.cfg.
batchJobDir: The folder for batch job logs and results, such as job logs submitted by submiJob. It can be specified on HDD in cluster.cfg.
jobLogFile: The query log of each node, logging the execution status of queries. It can be specified on HDD in cluster.cfg.
- Set a reasonable disk space and garbage collection interval of redo logs. It is recommended to specify the space to be 1-4 GB, and set the GC interval to be 60 seconds.
- Set a reasonable memory size of the cache engine. The maximum memory size should not exceed 1/4 of the memory configured on data nodes. 1-4 GB is recommended. Please take the specific SSD and its write speed into consideration.