Stream Monitoring
After initiating a subscription in DolphinDB, all calculations are performed in the background as streaming data is ingested and processed in real time. To monitor the status of subscription and stream processing, users can employ the DolphinDB web interface or specific built-in functions. The system will cache information of streaming engines, including groupings and their status. With specific interfaces, users can monitor the operating status of the streaming engine. Stream monitoring helps users quickly identify issues during computation. This page introduces two methods for stream monitoring and highlights key indicators to track.
Stream Monitoring Methods
DolphinDB offers two methods for stream monitoring: web interface and monitoring functions. These methods enable users to monitor the status of workers on subscribers as well as the connection status between the local publisher and its subscribers.
Web Interface (Recommended)
To access the web interface, start the DolphinDB server, and enter the URL (<IP address>:<port number>) in the browser. After successful login, click the Streaming tab on the left of the interface to view the status of various stream computing tasks, including:
- Subscriber and Publisher Status: Contains the status of workers on subscribers as well as the connection status between the local publisher and its subscribers. For details about each column, see getStreamingStat().subWorkers and getStreamingStat().pubConns.
- Streaming Engine Status: Contains the status of various streaming engines. For details about each column, see getStreamEngineStat.
- Stream Table Status: Contains the status of non-persisted and persisted shared stream tables. For details about each column, see getStreamTables.
- CEP Streaming Engine Status: Contains the status of the CEP engine, data views, and an interface to send events to CEP engines. For details, refer to CEP Streaming Engine.
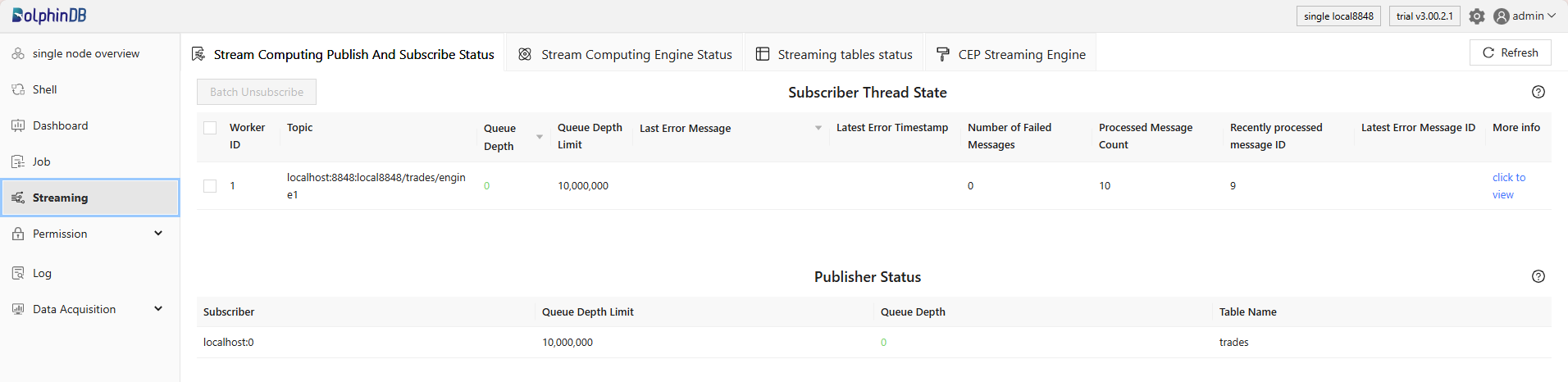
On this page, you can:
- Refresh: Click the Refresh button in the upper right corner to update the status. Regular refreshing is advised to track transient data and observe the status trends.
- Navigation Tabs: Click the navigation tabs at the top to switch between different tabs and view the latest status of subscribers/publishers, streaming engines, and stream tables.
- Sorting: Click fields with a triangle icon (e.g., queue depth, last error message) to sort the data ascendingly or descendingly.
- Batch Operations: Select multiple threads and click Batch Unsubscribe to stop subscribing to data. Select multiple engines/tables and click Batch Delete to delete the selected engines/tables.
- Function Details: Hover over table names to view the corresponding
state functions. For example, hover over the table name “Subscriber Thread
State” and
getStreamingStat().subWorkersappears.
For more information on the stream monitoring interface, refer to Stream.
Monitoring Functions
In addition to the web interface, users of other clients can also query the streaming status directly through the following functions.
This function monitors the streaming process and returns a dictionary with the following tables:
- Table pubConns displays the status of the connections between the local publisher node and all of its subscriber nodes. Each row represents a subscriber node.
- Table subConns displays the status of the connections between the local subscriber node and the publisher nodes. Each row is a publisher node that the local node subscribes to.
- Table pubTables displays the status of stream tables. Each row represents a stream table.
- Table persistWorkers displays the status of workers (threads) responsible for stream table persistence.
- Table subWorkers displays the status of workers of subscriber nodes.
- Table udpPubTables displays the publishing status using UDP multicast.
Note: The data returned by getStreamingStat() is
transient, so regular execution is required to track trends in the streaming
status.
This function monitors the status of all streaming engines defined in the system. It returns a dictionary that maps streaming engine types to the corresponding tables, as shown below.
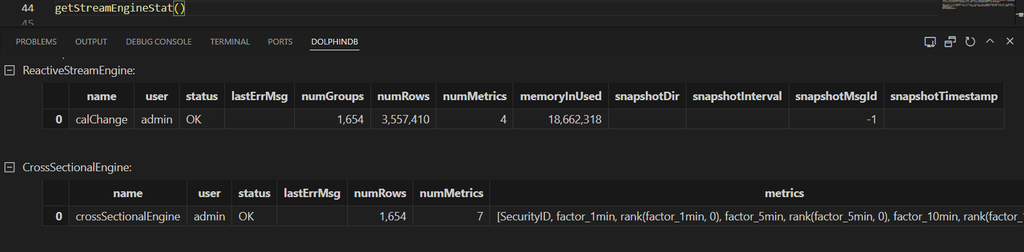
In the example above, there are a reactive state streaming engine and a cross-sectional streaming engine in the system. Their status, including engine names, processed row counts, and memory usage is displayed in the output tables.
This function monitors the information of specified stream tables and returns a table, as shown below.
| name | shared | persisted | cachePurgeEnabled | loaded | columns | rowsInMemory | totalRows | memoryUsed | accessControlEnabled |
|---|---|---|---|---|---|---|---|---|---|
| snapshotStreamTable | true | false | false | true | 42 | 8,046,454 | 8,046,454 | 1,610,615,184 | false |
In the example above, there is a non-persisted stream table named snapshotStreamTable in the system, which contains 42 columns and 8,046,454 rows.
Key Indicators
This section introduces key monitoring indicators, the issues they indicate, and recommended solutions.
Queue Depth
To troubleshoot stream data delays and blockages, it's essential to monitor the queue depth of subscriber and publisher status, particularly when there are multiple subscriptions to different topics on a node. If the data volume exceeds system capacity, the system handles data backlog progressively from the subscriber queue → publisher queue → data writing. Once the subscriber queue depth reaches queueDepthLimit, new messages from the publisher node are blocked, leading to a growing publisher queue depth. When it reaches queueDepthLimit, the system blocks new messages from entering the stream table on the publisher node.
The trend of queue depth can be monitored in the web interface by continuously refreshing the status. A persistent increase in queue depth indicates that the subscriber queue processes data slower than it is received, delaying computations. In the example below, data in the subscriber queue is piling up but has not reached its limit, so there is no backlog in the publisher queue yet.

Blockages in stream consumption can arise from several issues:
- Complex configurations in the metrics parameter of the streaming engine.
- Multiple computational tasks running on the same thread.
- Excessively high historical data replay rate set in the
replayfunction, overloading the data flow.
To prevent continuous increase in queue depth, it is recommended to employ various strategies to optimize streaming performance, such as parallel processing, micro-batching, and incremental computing. For more strategies, refer to Stream for DolphinDB - Performance Tuning.
Worker ID
The Worker ID column of the Subscriber Thread State table corresponds to the
hash parameter set in the subscribeTable function,
calculated as worker ID = hash % subExecutor + 1. The maximum of
worker ID is the value of the configuration parameter subExecutor, which
specifies the number of message processing threads in the subscriber node.
Suppose subExecutor is set to 4, there are at most 4 background threads
for processing jobs submitted by subscribeTable. It is
recommended to distribute stream computing tasks across workers to prevent
overloading and ensure efficient resource utilization.
Last Error Message
If an error occurs during subscription or a streaming engine, click details to view the latest error message. This column can be sorted descendingly to display threads with errors at the top.
For instance, when writing a stream table to a streaming engine, an error occurs if the schema defined by the dummyTable parameter differs to that of the subscribed stream table, as shown in figures below. To resolve this, unsubscribe the table, then modify the handler parameter before resubscribing.


Memory
As a streaming engine continuously receives subscribed data, it accumulates more
data in its cache, increasing its memory consumption. To adjust memory usage,
specify the keyPurgeFreqInSec parameter to clear the historical data that is no
longer needed. You can use the dropStreamEngine function
to release memory for unused engines. Additionally, if the handle of a streaming
engine still exists in memory, it is necessary to release it by setting the
returned handle to NULL.