Unified Batch and Stream Processing
Stream and batch processing serve complementary roles in data analytics. While batch processing is optimal for historical data analysis in research environments, stream processing empowers real-time applications like trading systems. Organizations traditionally employ separate platforms for each paradigm - such as Hive for batch and Flink for stream processing. However, maintaining separate systems presents several challenges:
- Redundant code development
- Complex system maintenance
- Time-consuming result validation
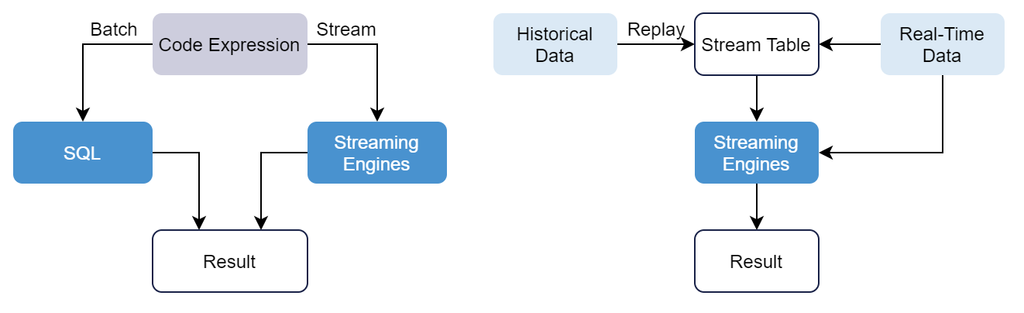
DolphinDB addresses these challenges through its unified stream-batch processing framework, enabling developers to maintain a single codebase that supports both batch (research) and stream (trading) processing while ensuring consistent results. The framework operates through two implementations:
- Replaying historical data to simulate real-time data streams.
- Reusing factor expressions developed in research environments in real-time processing.
Historical Data Replay
DolphinDB offers the feature to simulate real-time data streams by replaying historical data. This ensures processing consistency between research and production environments, as the streaming engines process both live and replayed data through identical workflows.
Example: Computing a high-frequency factor using user-defined function
sum_diff and the built-in ema function.
def sum_diff(x, y){
return (x-y)/(x+y)
}
factor1 = <ema(1000 * sum_diff(ema(price, 20), ema(price, 40)),10) - ema(1000 * sum_diff(ema(price, 20), ema(price, 40)), 20)>
// Define reactive state engine
share streamTable(1:0, `sym`date`time`price, [STRING,DATE,TIME,DOUBLE]) as tickStream
result = table(1:0, `sym`factor1, [STRING,DOUBLE])
rse = createReactiveStateEngine(name="reactiveDemo", metrics =factor1, dummyTable=tickStream, outputTable=result, keyColumn="sym")
subscribeTable(tableName=`tickStream, actionName="factors", handler=tableInsert{rse}) Historical data is replayed into the engine for calculation.
// Load one day of data from trades table, replay into stream table tickStream
sqlObj = <select SecurityID, Date, Time, Price from loadTable("dfs://trade", "trade") where Date=2021.03.08>
inputDS = replayDS(sqlObj, `Date, `Time, 08:00:00.000 + (1..10) * 3600000)
replay(inputDS, tickStream, `Date, `Time, 1000, true, 2)Additionally, batch processing can also be implemented by appending historical data in batches into streaming engines, which can bypass the publish-subscribe overhead. The following script writes tick trade for a day into a reactive state engine:
tmp = select SecurityID, Date, Time, Price from loadTable("dfs://trade", "trade") where Date=2021.03.08
getStreamEngine("reactiveDemo").append!(tmp)Factor Expression Reuse
In DolphinDB, factor expressions and function definitions describe semantics, while specific computations are handled by batch or stream computing engines. Streaming engines can reuse factor expressions in batch processing and return identical results, saving the efforts of code rewriting in production. This method streamlines validation in live applications through batch calculations, significantly reducing debugging costs.
Example: Computing the daily ratio of buy volumes over total trade volumes
Define a function buyTradeRatio. The @state
decorator at line 1 is used to declare the function as a state function for
optimization in stream processing, which can be omitted in batch processing.
@state // Decorator for stream processing optimization
def buyTradeRatio(buyNo, sellNo, tradeQty){
return cumsum(iif(buyNo>sellNo, tradeQty, 0))\\cumsum(tradeQty)
}In batch processing, use SQL queries to leverage parallelism.
factor = select SecurityID, Time, buyTradeRatio(BuyNo, SellNo, TradeQty) as Factor
from loadTable("dfs://trade","trade")
where Date=2020.12.31 and Time>=09:30:00.000
context by SecurityID csort Time In stream processing, specify the UDF buyTradeRatio (with an
@state decorator) as the calculation metrics. The following
script creates the demo reactive state engine grouping by SecurityID, with input
message format matching the in-memory table tickStream:
tickStream = table(1:0, `SecurityID`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo, [SYMBOL,DATETIME,DOUBLE,INT,DOUBLE,LONG,LONG])
result = table(1:0, `SecurityID`TradeTime`Factor, [SYMBOL,DATETIME,DOUBLE])
factors = <[TradeTime, buyTradeRatio(BuyNo, SellNo, TradeQty)]>
demoEngine = createReactiveStateEngine(name="demo", metrics=factors, dummyTable=tickStream, outputTable=result, keyColumn="SecurityID")