Stream High Availability
DolphinDB employs a unified framework that can handle both real-time and historical data. The streaming features allow for streaming data publishing, subscription, preprocessing, real-time computing, and window calculations involving complex factors. To ensure non-interruptible streaming services, DolphinDB supports high availability for stream processing.
DolphinDB's streaming pub/sub architecture consists of Publishers, Brokers, and Subscribers. The Broker is hosted on DolphinDB data/compute node(s). Publishers and Subscribers can be hosted on DolphinDB data nodes or accessed via third-party APIs.
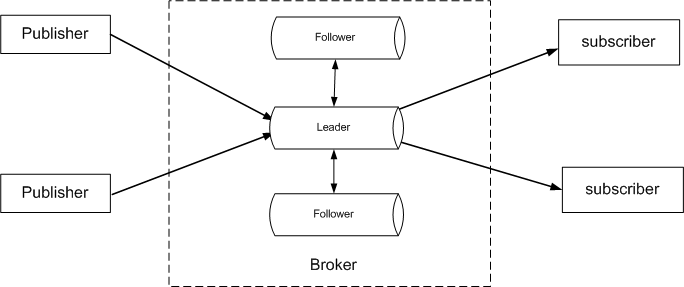
DolphinDB utilizes the Raft consensus protocol to orchestrate replicas and implement the high availability feature. High availability requires that database can tolerate nodes going offline without interrupting service. To achieve this, DolphinDB replicates data across nodes to ensure access to the data is maintained if any nodes become unavailable.
Using the Raft protocol also ensures automatic recovery: Only when a majority of nodes fail in a raft group, it will stop serving. The number of failures that can be tolerated is equal to (Replica Count - 1)/2. For example, with three replicas, one failure can be tolerated; with five replicas, two failures, and so on. There is typically only one leader in a raft group to respond to requests from clients, and the other nodes are followers.
DolphinDB provides high availability for the Brokers, Publishers, and Subscribers in the streaming architecture, and it demonstrates the following features:
-
Multiple raft groups can be deployed on a single data node.
-
Multiple stream tables can be defined in a raft group.
-
A high-availability stream table can be created by specifying a raft group ID.
-
Publishers write data to the leader of the raft group. If a write fails or exception occurs on non-leader node, the connection automatically switches to a new leader for data writing.
-
Subscribers receive data from the leader. When the leader is changed to follower after re-election, the Broker actively disconnects all subscriptions to the stream tables in that raft group. After disconnection, Subscribers reconnect and subscribe to the new leader upon receiving notification from the leader.
1. High Availability of Brokers
1.1. Configure Cluster
To enable high availability for streaming subscriptions in a DolphinDB cluster, it must be deployed across multiple servers. Then you need to configure HA-related parameters and create HA stream tables.
Key configuration parameters:
| Parameter | Description |
| clusterName | Sets the cluster name. |
| streamingHAMode | Sets the protocol used to enable high availability, currently fixed as "raft" to use the Raft algorithm. |
| streamingRaftGroups | Defines raft groups in the format "groupId:data_node+", where groupId is the group ID (an integer greater than 1) and data_node is the alias of data node in the group. Each raft group has at least 3 data nodes, separated with a colon (:). Multiple groups are separated by commas. |
| persistenceDir | The directory where shared stream tables are persisted. To save an HA stream table to disk, persistenceDir must be specified. In a cluster, each data node on the same physical machine should be configured with different persistenceDir. |
| streamingHALogDir | The directory to keep streaming raft logs. In a cluster, each data node on the same physical machine should be configured with different streamingHALogDir . The default directory is <HOME>/log/streamingHALog. |
The above parameters are configured in the file cluster.cfg. The following example configures two raft groups:
-
raft group 2: DataNode1, DataNode3 and DataNode5;
-
raft group 3: DataNode2, DataNode4, and DataNode6.
clusterName=cluster1
streamingHAMode=raft
streamingRaftGroups=2:DataNode1:DataNode3:DataNode5,3:DataNode2:DataNode4:DataNode6
persistenceDir=/ssd/dolphindb/persistenceDir/<ALIAS>
streamingHALogDir=/ssd/dolphindb/streamLog/<ALIAS>- clusterName must be set according to the actual cluster name.
- The node names specified in streamingRaftGroups must match the
names of the data nodes or computing nodes configured in
cluster.nodes. - The paths specified for persistenceDir and streamingHALogDir must be configured according to the actual directory structure of the server.
<ALIAS>is a macro variable that is automatically replaced with the alias of each node.
1.2. Check Configured Raft Groups
The function getStreamingRaftGroups is used to obtain and verify
the configured raft groups in the cluster on the current data node.
For example, call getStreamingRaftGroups() on DataNode1:
| id | sites |
| 2 | 192.168.1.11:19151:DataNode1,192.168.1.12:19153:DataNode3,192.168.1.13:19155:DataNode5 |
1.3. Get Raft Group Leader
After a raft group is configured, a leader is elected automatically to provide
streaming services for the clients, and the other nodes in the group will be
followers. When a leader is down, a new leader is re-elected automatically. To
check the leader of a raft group, use
getStreamingLeader(groupId) where the parameter groupId
is the raft group ID
To obtain the leader of a raft group, the function must be called on the data
nodes in that raft group. For example, to get the leader of raft group 2, call
getStreamingLeader(2) on DataNode1, DataNode3, or
DataNode5.
To obtain the leader of group 2 on other nodes, you need to first obtain the node
information configured in that raft group, and then use rpc to
obtain the leader on that node. For example:
t=exec top 1 id,node from pnodeRun(getStreamingRaftGroups) where id =2
leader=rpc(t.node[0],getStreamingLeader,t.id[0])1.4. Create HA Stream Tables
Use function haStreamTable to create a HA stream table:
haStreamTable(raftGroup, table, tableName, cacheLimit, [keyColumn],
[retentionMinutes=1440])
The parameter raftGroup is a raft group ID configured via streamingRaftGroups.
The optional parameter keyColumn is a string indicating the primary key. Setting the primary key can automatically filter out duplicate data. For example, the key column in IoT scenario can be set as the unique combination of device ID and message; For stock market it can be set as the unique combination of stock symbol and message. In this case, data from multiple data sources can be deduplicated.
Multiple HA stream tables can be defined in a raft group. Note:
-
A HA stream table persists its schema in the log, so recreation of the table is not required after server restart.
-
For HA subscription, a client only needs to subscribe to a HA stream table on any node in the raft group and enable reconnection. Streaming data will be published from leader to the client. If the leader fails, a new leader is re-elected and the connection is automatically switched to the new leader.
-
After HA streaming is enabled, stream tables can be defined on a data node no matter if it is high-available. A regular stream table and a HA stream table can be converted from one to another. When converting a regular stream table to a HA stream table with the same name, the data and logs of the previous table must be cleared (with command
dropStreamTable). The metadata of a stream table can be checked with functiongetPersistenceMeta.
For example, create a HA stream table haDevSt in the raft group 2:
t1=table(1:0, ["id","source_address","source_port","destination_address","destination_port"], [STRING,INT,INT,INT,INT] )
haStreamTable(2,t1,"haDevSt",100000,"id")1.5. Drop HA Stream Tables
Use the command dropStreamTable(tableName) to drop an HA stream
table.
Note:
-
All subscriptions must be canceled before dropping a stream table.
-
To drop a regular stream table, you can call
dropStreamTable,clearTablePersistence(objByName(tableName))(if persisted), orundef(tableName, SHARED).
2. High Availability of Publishers and Subscribers
2.1. Write Streaming Data
When publishing streaming data to a HA stream table, writes can only be directed to the leader. If data is written to a follower, an exception reporting NotLeader will be raised. Currently, Java/C++/Python API all support high-availability subscriptions to stream tables. The exception can be automatically captured and an available leader is connected for subsequent writes. For example:
-
Connect with Java API:
String[] haSites = new String[]{"192.168.1.11:19151","192.168.1.12:19153","192.168.1.13:19155"}; conn.connect(host,port,"admin", "123456", initScript, true,haSites); -
Connect with Python API:
conn.connect(host, port,"admin","123456", initScript, True, ["192.168.1.2:9921","192.168.1.3:9921","192.168.1.4:9921"])
2.2. Subscribe to Streaming Data
A DolphinDB client only needs to subscribe to a high-availability stream table on any node of a raft group and enable the automatic reconnection (i.e., set the reconnect parameter to true) upon subscription. If the leader fails, a new leader is elected and the subscription is automatically switched to the new leader.
The function subscribeTable allows persisting processed messages
and resubscribing from a specified offset when persistOffset is set to
true. The offset can be retrieved with function
getTopicProcessedOffset.
The following example creates a high-availability stream table haDevSt on raft
group 2. The following example executes subscribeTable on a
random node in the cluster and subscribes to the table haDevSt on the leader.
t1=table(1:0, ["id","source_address","source_port","destination_address","destination_port"], [STRING,INT,INT,INT,INT] )
haStreamTable(2,t1,"haDevSt",100000,"id")
t=select id,node from pnodeRun(getStreamingRaftGroups) where id =2
def msgProc(msg){ //process messages
}
subscribeTable(server=t.node[0], tableName="haDevSt", handler=msgProc, reconnect=true, persistOffset=true)When a client subscribes to a high-availability stream table through DolphinDB API, automatic reconnection must be enabled upon subscription. As of now, Java API, C++ API, and Python API have supported high availability for streaming data consumption. The API handles failover in the following ways:
-
When the client initiates subscription, all node sites of the raft group are saved.
-
If a leader fails, the Broker will actively close all connections to the stream table and the client will initiate reconnection.
-
If the client reconnects to a follower, a NotLeader exception is reported, which includes the leader information. Then the client attempts to reconnect to the new leader.
-
If the client fails to reconnect to a node multiple times, it attempts to connect to another configured node.
3. Design of Streaming High Availability
The high availability of streaming in DolphinDB utilizes the Raft consensus protocol to maintain data consistency. This involves leader election, log replication and safety. A leader is elected to receive write requests, replicate logs to followers and notify followers to commit the logs. When a leader fails, a new election is initiated by other followers to elect a new leader.
DolphinDB uses raft logs to record adding and deleting operations on stream tables. These logs are synchronously written to disk in sequential order. For large stream tables, DolphinDB cleans up old data in memory and saves it to disk. When consumers subscribe to historical data, it must be loaded from disk. Since the logs are stored sequentially, streaming data would need to be loaded from the beginning. To optimize the speed of subscribing to old data, DolphinDB assigns each raft log an LSN (Log Sequence Number), and each data file an LSN that represents its latest modification. During data restoration, DolphinDB compares the LSNs of the logs and data files: If a log's LSN is smaller than the data file's LSN, the operations in that log have already been performed on the file, so no redo is required. To prevent unlimited log growth, DolphinDB truncates the logs at certain size using checkpoints.
When streaming data is written to DolphinDB, the producer sends it to the leader. The leader first writes a log to the raft log, then replicates the log to the followers while asynchronously writing to the data file. Upon receiving the logs from the leader, the followers asynchronously write the logs to their local data files. Through the raft logs, data logs, and Raft consensus protocols, the system ensures no data loss even if a node fails. If a node goes offline or restarts, raft guarantees the leader will synchronize any data written during the node's downtime once it comes back online. This maintains consistency across replicas in the group and prevents data loss. However, this synchronization can be slow and may impact replication of new logs. Therefore, if a node has been offline for a long time with a large number of new data written, it is recommended to rejoin the raft group when the system is idle.
Writing and subscription to streams in DolphinDB is not transactional. This means that duplicate data may be written, for example, if the leader sends a successful write confirmation to the producer but the confirmation is not received due to network issues. In this case, the producer may rewrite the data, causing duplicates. After a subscriber receives and processes a message, it records the message number. The subscriber will subscribe starting from the next message based on the recorded number. If an exception occurs during message processing where data is saved but the message number is not recorded, the message may be subscribed repeatedly. To avoid duplicate data sent from the producer, DolphinDB provides keyed stream tables. By setting a primary key, the system can automatically filter out duplicate streams based on the primary key values.
4. Performance Benchmarking
To evaluate the performance impact of leader-follower replication, we deploy a 3-server HA cluster for benchmarking. To minimize the effects of network and disk I/O, the servers use 10 Gigabit network. The raft logs are stored on SSDs, while the stream tables are stored on HDDs. Both the HA and regular stream tables use synchronous writes without compression. The API client which writes data and the leader run on the same server. In this test, data writes to the HA and regular stream tables occur on the same disk of the same server. Tables and data are cleared before each test to enable a fair comparison.
The HA and regular stream tables use the same table schema. To test the impact of record size on performance, we measure two cases: tables with 11 columns and 211 columns. Since the raft logs must be flushed for each write batch, we also vary the write batch size since larger batches allow more efficient log flushing. Meanwhile, we evaluate the impact of multi-threaded writes by adding a 4-threaded test.
The results for tables with 11 columns are:
| Number of Records Written | Number of Threads | Batch Size per Thread | Number of Writes per Thread | HA Elapsed Time (ms) | HA Write Rate (Record/Sec) | Regular Elapsed Time (ms) | Regular Write Rate (Record/Sec) | HA/Regular Write Rate Ratio |
| 10,000 | 1 | 1 | 10,000 | 14,884 | 671.9 | 6,597 | 1,515.8 | 44.3% |
| 1,000,000 | 1 | 100 | 10,000 | 419,572 | 2,383.4 | 407,980 | 2,451.1 | 97.2% |
| 10,000,000 | 1 | 1,000 | 10,000 | 440,250 | 22,714.4 | 421,990 | 23,697.2 | 95.9% |
| 10,000,000 | 1 | 10,000 | 1,000 | 26,382 | 379,046.3 | 18,868 | 529,997.9 | 71.5% |
| 40,000 | 4 | 1 | 10,000 | 45,213 | 884.7 | 7,120 | 5,618.0 | 15.7% |
| 4,000,000 | 4 | 100 | 10,000 | 421,568 | 9,488.4 | 40,150 | 9,776.4 | 97.1% |
| 40,000,000 | 4 | 1,000 | 10,000 | 446,746 | 89,536.3 | 427,825 | 93,496.2 | 95.8% |
| 40,000,000 | 4 | 10,000 | 1,000 | 59,203 | 675,641.4 | 35,509 | 1,126,475.0 | 60.0% |
The results for tables with 211 columns are:
| Number of Records Written | Number of Threads | Batch Size per Thread | Number of Writes per Thread | HA Elapsed Time (ms) | HA Write Rate (Record/Sec) | Regular Elapsed Time (ms) | Regular Write Rate (Record/Sec) | HA/Regular Write Rate Ratio |
| 10,000 | 1 | 1 | 10,000 | 427,502 | 23.4 | 419,282 | 23.9 | 98.1% |
| 1,000,000 | 1 | 100 | 10,000 | 256,728 | 3,895.2 | 242,651 | 4,121.1 | 94.5% |
| 10,000,000 | 1 | 1,000 | 10,000 | 458,010 | 2,1833.6 | 339,780 | 29,430.8 | 74.2% |
| 10,000,000 | 1 | 10,000 | 1,000 | 167,349 | 59,755.4 | 112,188 | 89,136.1 | 67.0% |
| 40,000 | 4 | 1 | 10,000 | 429,201 | 93.2 | 415,907 | 96.2 | 96.9% |
| 4,000,000 | 4 | 100 | 10,000 | 295,807 | 13,522.3 | 171,150 | 23,371.3 | 57.9% |
| 40,000,000 | 4 | 1,000 | 10,000 | 519,405 | 77,011.2 | 372,236 | 107,458.7 | 71.7% |
| 40,000,000 | 4 | 10,000 | 1,000 | 589,830 | 67,816.2 | 327,665 | 122,075.9 | 55.6% |
The test results show that with a small number of columns and batch sizes, the write performance of HA stream table is greatly impacted. This is because the network transmission overhead of raft logs accounts for a large proportion of total processing time. With a large number of columns or batch sizes (e.g. 100-1000 records), the overall processing time increases. Since the 10 Gigabit network transmission has lower overhead compared to the larger disk flush cost, the performance difference between HA and regular stream tables is less noticeable. The results also demonstrate that write throughput can be improved by increasing the thread count and batch size. Overall, the replication cost is lower when flush costs are high, while small batches and records magnify the replication overhead impact.
5. Conclusion
DolphinDB's streaming data framework uses a high-availability multi-replica architecture based on Raft consensus protocol to provide high availability for Publishers, a Broker, and Subscribers. Performance benchmarks indicate that tuning batch size, column count, and other factors can optimize performance of DolphinDB's HA streaming to minimize the replication impact.