Stream for DolphinDB
Real-time stream processing handles a continuous "stream" of data as the data is published. The process includes real-time data collection, cleaning, analysis, warehousing, and displaying of results. The stream-based applications include trading, social networks, Internet of Things, system monitoring, and many other examples. DolphinDB's built-in stream processing framework is efficient and convenient, which supports stream publishing, subscription, data preprocessing, real-time in-memory calculation, complex window calculation, stream-table joins, anomaly detection, etc.
The advantages of Stream for DolphinDB over other streaming analytics systems are:
- High throughput, low latency, high availability
- One-stop solution that is seamlessly integrated with time-series database and data warehouse
- Natural support of stream-table duality and SQL statements
Stream for DolphinDB provides numerous convenient features, such as:
- Built-in time-series, cross-sectional, anomaly detection, and reactive state streaming engines.
- High frequency data replay
- Streaming data filtering
1. Flowchart and Related Concepts
Stream for DolphinDB uses the publish-subscribe model. Real-time data is ingested into the stream table and is then published to all subscribers. A data node, compute node or a third-party application can subscribe to and consume the streaming data through DolphinDB script or API. The DolphinDB streaming flowchart is as follows:
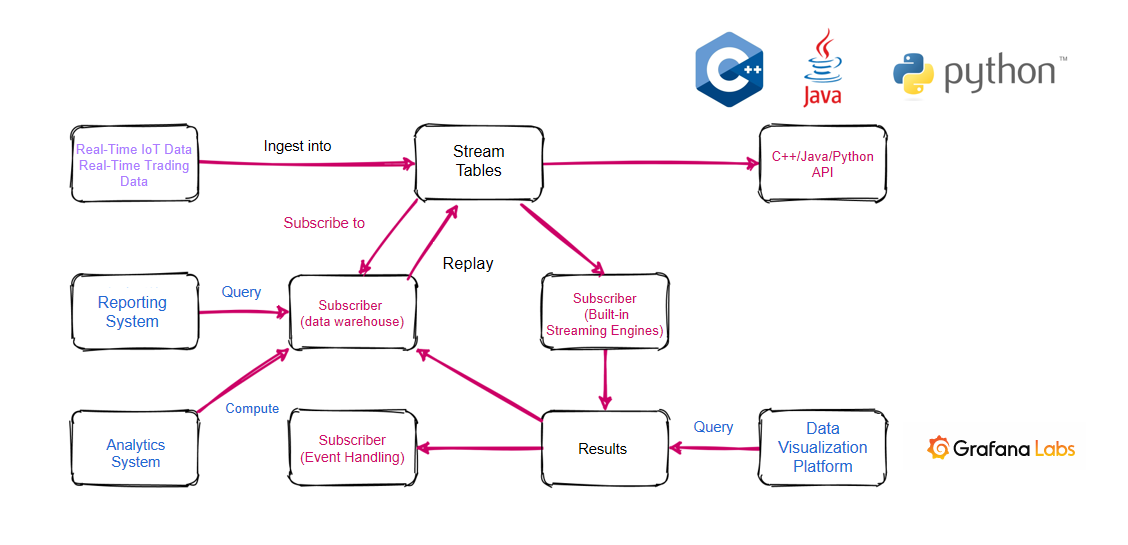
Real-time data is ingested into a stream table on a publisher node. The streaming data can be subscribed by various types of objects:
- Data warehouse for further analysis and reporting.
- Streaming engine to perform calculations and to output the results to another stream table. The results can be displayed in real time in a platform such as Grafana and can also serve as a data source for event processing by another subscription.
- API. For example, a third-party Java application can subscribe to streaming data with Java API.
1.1. Stream Table
Stream table is a special type of in-memory table to store and publish streaming data. Stream table supports concurrent read and write. A stream table can be appended to, but the records of a stream table cannot be modified or deleted. SQL statements can be used to query stream tables.
1.2. Publish-Subscribe
Stream for DolphinDB uses the classic publish-subscribe model. After new data is ingested to a stream table, all subscribers are notified to process the new data. A data node or compute node uses function subscribeTable to subscribe to the streaming data.
1.3. Streaming Engine
The streaming engine refers to a module dedicated to real-time calculation and analysis of streaming data. DolphinDB provides dozens of Streaming Engines for real-time calculation with streaming data.
2. Core Functionalities
To enable streaming, specify the configuration parameter maxPubConnections on the publisher node and subPort on the subscriber nodes. For details of streaming configuration, see Reference.
2.1. Publish Streaming Data
Use function streamTable to define a stream table. Real-time data is ingested into the stream table and then published to all subscribers. A publisher usually has multiple subscribers in multiple sessions, so a stream table must be shared across all sessions with the command share before publishing streaming data.
Define and share the stream table "pubTable":
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTableThe stream table created by function streamTable may contain duplicate records. You can create a stream table with primary keys with function keyedStreamTable. For a stream table with primary keys, subsequent records with identical primary key values as an existing record will not be written to the stream table.
share keyedStreamTable(`timestamp, 10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable2.2. Subscribe to Streaming Data
Use function subscribeTable to subscribe to streaming data.
Syntax of function subscribeTable:
subscribeTable([server],tableName,[actionName],[offset=-1],handler,[msgAsTable=false],[batchSize=0],[throttle=1],[hash=-1],[reconnect=false],[filter],[persistOffset=false],[timeTrigger=false],[handlerNeedMsgId=false], [raftGroup])Parameter Description:
Only parameters tableName and handler are required. All other parameters are optional.
The parameter server is a string indicating the alias or the remote connection handle of a server where the stream table is located. If it is unspecified or an empty string (""), it means the local instance.
There are 3 possibilities regarding the locations of the publisher and the subscriber:
Publisher and subscriber are on the same local data node: use empty string ("") for server or leave it unspecified.
subscribeTable(tableName="pubTable", actionName="act1", offset=0, handler=subTable, msgAsTable=true)Publisher and subscriber are not on the same data node but in the same cluster: specify the publisher node's alias for server.
subscribeTable(server="NODE2", tableName="pubTable", actionName="act1", offset=0, handler=subTable, msgAsTable=true)The publisher is not in the same cluster as the subscriber: specify the remote connection handle of the publisher node for server.
pubNodeHandler=xdb("192.168.1.13",8891) subscribeTable(server=pubNodeHandler, tableName="pubTable", actionName="act1", offset=0, handler=subTable, msgAsTable=true)
The parameter tableName is a string indicating the shared stream table name.
subscribeTable(tableName="pubTable", actionName="act1", offset=0, handler=subTable, msgAsTable=true)The parameter actionName is a string indicating the subscription task name. It can have letters, digits and underscores. It must be specified if multiple subscriptions on the same node subscribe to the same stream table.
topic1 = subscribeTable(tableName="pubTable", actionName="realtimeAnalytics", offset=0, handler=subTable, msgAsTable=true) topic2 = subscribeTable(tableName="pubTable", actionName="saveToDataWarehouse", offset=0, handler=subTable, msgAsTable=true)
Function subscribeTable returns the subscription topic. It is the combination of the alias of the node where the stream table is located, the stream table name, and the subscription task name (if actionName is specified), separated by forward slash "/". If the local node alias is NODE1, the two topics returned by the example above are as follows:
topic1:
NODE1/pubTable/realtimeAnalyticstopic2:
NODE1/pubTable/saveToDataWarehouseIf the subscription topic already exists, an exception is thrown.
- The parameter offset is an integer indicating the position of the first message where the subscription begins. A message is a row of the stream table. The offset is relative to the first row of the stream table when it is created. If offset is unspecified or -1, the subscription starts with the next new message. If offset=-2, the system will get the persisted offset on disk and start subscription from there. If some rows were cleared from memory due to cache size limit, they are still included in determining where the subscription starts.
The following example illustrates the role of offset. We write 100 rows to 'pubTable' and create 2 subscription topics:
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable1
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable2
vtimestamp = 1..100
vtemp = norm(2,0.4,100)
tableInsert(pubTable,vtimestamp,vtemp)
topic1 = subscribeTable(tableName="pubTable", actionName="act1", offset=-1, handler=subTable1, msgAsTable=true)
topic2 = subscribeTable(tableName="pubTable", actionName="act2", offset=50, handler=subTable2, msgAsTable=true)subTable1 is empty and subTable2 has 50 rows. When offset is -1, the subscription will start from the next new message.
- The parameter handler is a unary function or a table. If handler is a function, it is used to process the subscribed data. The only parameter of the function is the subscribed data, which can be a table or a tuple of the subscribed table columns. Quite often we need to insert the subscribed data into a table. For convenience handler can also be a table, and the subscribed data is inserted into the table directly.
The following example shows the two uses of handler. In the subscription of "act1", the subscribed data is written directly to subTable1; in the subscription of "act2", the subscribed data is filtered with the user-defined function myHandler and then written to subTable2.
def myhandler(msg){
t = select * from msg where temperature>0.2
if(size(t)>0)
subTable2.append!(t)
}
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable1
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable2
topic1 = subscribeTable(tableName="pubTable", actionName="act1", offset=-1, handler=subTable1, msgAsTable=true)
topic2 = subscribeTable(tableName="pubTable", actionName="act2", offset=-1, handler=myhandler, msgAsTable=true)
vtimestamp = 1..10
vtemp = 2.0 2.2 2.3 2.4 2.5 2.6 2.7 0.13 0.23 2.9
tableInsert(pubTable,vtimestamp,vtemp)The result shows that 10 messages are written to pubTable. SubTable1 receives all of them whereas subTable2 receives 9 messages as the row with vtemp=0.13 is filtered by myhandler.
- The parameter msgAsTable is a Boolean value indicating whether the subscribed data is ingested into handler as a table or as a tuple. If msgAsTable=true, the subscribed data is ingested into handler as a table and can be processed with SQL statements. The default value is false, which means the subscribed data is ingested into handler as a tuple of columns.
def myhandler1(table){
subTable1.append!(table)
}
def myhandler2(tuple){
tableInsert(subTable2,tuple[0],tuple[1])
}
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable1
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable2
topic1 = subscribeTable(tableName="pubTable", actionName="act1", offset=-1, handler=myhandler1, msgAsTable=true)
topic2 = subscribeTable(tableName="pubTable", actionName="act2", offset=-1, handler=myhandler2, msgAsTable=false)
vtimestamp = 1..10
vtemp = 2.0 2.2 2.3 2.4 2.5 2.6 2.7 0.13 0.23 2.9
tableInsert(pubTable,vtimestamp,vtemp)- The parameter batchSize is an integer indicating the number of unprocessed messages to trigger the handler. If it is positive, the handler does not process messages until the number of unprocessed messages reaches batchSize. If it is unspecified or non-positive, the handler processes incoming messages as soon as each batch is ingested.
In the following example, batchSize is set to 11.
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable1
topic1 = subscribeTable(tableName="pubTable", actionName="act1", offset=-1, handler=subTable1, msgAsTable=true, batchSize=11)
vtimestamp = 1..10
vtemp = 2.0 2.2 2.3 2.4 2.5 2.6 2.7 0.13 0.23 2.9
tableInsert(pubTable,vtimestamp,vtemp)
print size(subTable1)Write 10 messages to pubTable. Now the subscribing table subTable1 is empty.
insert into pubTable values(11,3.1)
print size(subTable1)After 1 more message is written to pubTable, the number of unprocessed messages reaches the value of batchSize and triggers the handler. The subscribing table subTable1 receives 11 records.
- The parameter throttle is a floating-point number indicating the maximum waiting time (in seconds) before the handler processes the messages if the number of unprocessed messages is smaller than batchSize. The default value is 1. This optional parameter has no effect if batchSize is not specified. If throttle is less than the configuration parameter subThrottle/1000, throttle is effectively subThrottle/1000.
There is little difference in the amount of time it takes to process one message versus a batch of messages (for example, 1000 messages). If each individual message triggers the handler, the speed of data ingestion may overwhelm the speed of data consumption. Moreover, data may pile up at the subscriber node and use up all memory. If batchSize and throttle are configured properly, we can improve throughput by adjusting the frequency at which the handler processes the messages.
2.3. Automatic reconnection
To enable automatic reconnection after network disruption, the stream table must be persisted on the publisher. Please refer to "Streaming Data Persistence" for enabling persistence. When parameter reconnect is set to true, the subscriber will record the offset of the streaming data. When the network connection is interrupted, the subscriber will automatically resubscribe from the offset. If the subscriber crashes or the stream table is not persisted on the publisher, the subscriber cannot automatically reconnect.
2.4. Filtering of Streaming Data on the Publisher Node
Streaming data can be filtered at the publisher. It may significantly reduce network traffic. Use command setStreamTableFilterColumn on the stream table to specify the filtering column (as of now a stream table can have only one filtering column), then specify the parameter filter in function subscribeTable. Only the rows with filtering column values in filter are published to the subscriber.
In the following example, the value of the parameter filter is a vector. Only the data of 'IBM' and 'GOOG' are published to the subscriber:
share streamTable(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT]) as trades
setStreamTableFilterColumn(trades, `symbol)
trades_slave=table(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT])
filter=symbol(`IBM`GOOG)
subscribeTable(tableName="trades", actionName="trades_1", handler=append!{trades_1}, msgAsTable=true, filter=filter)In the following example, the value of the parameter filter is a pair.
share streamTable(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT]) as trades
setStreamTableFilterColumn(trades, `price)
trades_1=table(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT])
subscribeTable(tableName="trades", actionName="trades_1", handler=append!{trades_1}, msgAsTable=true, filter=1:100)In the following example, the value of the parameter filter is a tuple.
share streamTable(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT]) as trades
setStreamTableFilterColumn(trades, `price)
trades_1=table(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT])
subscribeTable(tableName="trades", actionName="trades_1", handler=append!{trades_1}, msgAsTable=true, filter=(10,1:5))2.5. Unsubscribe
Each subscription is uniquely identified with a subscription topic. If a new subscription has the same topic as an existing subscription, the new subscription cannot be established. To renew a subscription, you need to cancel the existing subscription with command unsubscribeTable.
Unsubscribe from a local table:
unsubscribeTable(tableName="pubTable", actionName="act1")Unsubscribe from a remote table:
unsubscribeTable(server="NODE_1", tableName="pubTable", actionName="act1")To delete a shared stream table, use command undef:
undef("pubStreamTable", SHARED)2.6. Streaming Data Persistence
By default, the stream table keeps all streaming data in memory. streaming data can be persisted to disk for the following 3 reasons:
- Backup and restore streaming data. When a node reboots, the persisted data can be automatically loaded into the stream table.
- Avoid out-of-memory problem.
- Resubscribe from any position.
If the number of rows in the stream table reaches a preset threshold, the first half of the table will be persisted to disk. The persisted data can be resubscribed.
To initiate streaming data persistence, we need to add a persistence path to the configuration file of the publisher node:
persisitenceDir = /data/streamCacheThen execute command enableTableShareAndPersistence to share the stream table and enable persistence of it.
The following example shares pubTable as sharedPubTable and enables the persistence of it. The parameter cacheSize is set to 1000000, and the default values of parameters asynWrite and compress are both true. When the stream table reaches 1 million rows, the first half of them are compressed to disk asynchronously.
pudTable=streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE])
enableTableShareAndPersistence(table=pubTable, tableName=`sharedPubTable, cacheSize=1000000)When enableTableShareAndPersistence is executed, if the persisted data of sharedPubTable already exists on the disk, the system will load the latest cacheSize=1000000 rows into the memory.
Whether to enable persistence in asynchronous mode is a trade-off between data consistency and latency. If data consistency is the priority, we should use the synchronous mode. This ensures that data enters the publishing queue after the persistence is completed. On the other hand, if low latency is more important and we don't want disk I/O to affect latency, we should use asynchronous mode. The configuration parameter persistenceWorkerNum only works when asynchronous mode is enabled. With multiple publishing tables to be persisted, increasing the value of persistenceWorkerNum can improve the efficiency of persistence in asynchronous mode.
Persisted data can be deleted with command clearTablePersistence.
clearTablePersistence(pubTable)To turn off persistence, use command disableTablePersistence.
disableTablePersistence(pubTable)Use function getPersistenceMeta to get detailed information regarding the persistence of a stream table:
getPersistenceMeta(pubTable);The result is a dictionary with the following keys:
//The number of rows in memory:
sizeInMemory->0
//Whether asynchronous mode is enabled:
asynWrite->true
//The total number of rows of the stream table:
totalSize->0
//Whether the data is persisted with compression:
compress->true
//The offset of data in memory relative to the total number of rows. memoryOffset = totalSize - sizeInMemory.
memoryOffset->0
//The number of rows that have been persisted to disk:
sizeOnDisk->0
//How long the log file will be kept in terms of minutes. The default value is 1440 minutes (one day).
retentionMinutes->1440
//The path where the persisted data is saved
persistenceDir->/hdd/persistencePath/pubTable
//hashValue is the identifier of the worker for persistence of the stream table.
hashValue->0
//The offset of the first of the persisted streaming messages on disk relative to the entire stream table.
diskOffset->02.7. Delete Stream Tables
All subscriptions must be canceled before stream tables are deleted.
To delete a shared stream table, use function undef or dropStreamTable. For example, delete table pubTable created above:
undef(`pubTable, SHARED)
dropStreamTable(`pubTable)Function undef can remove variables or function definitions from memory. For a persisted stream table, execute dropStreamTable and the table will be removed from the memory and disk.
dropStreamTable(`pubTable);3. Streaming Engines
3.1. Creating Streaming Engines
DolphinDB Streaming Engines can be used real-time stream processing. For example, you can create a reactive state engine:
rse = createReactiveStateEngine(name="reactiveDemo", metrics =<cumsum(price)>, dummyTable=tickStream, outputTable=result, keyColumn="sym", snapshotDir= "/home/data/snapshot", snapshotIntervalInMsgCount=20000)You can remove the definition of the streaming engine from memory with dropStreamEngine:
dropStreamEngine("reactiveDemo")Note: DolphinDB versions 1.30.21/2.00.9 and earlier do not support concurrent access to the streaming engines. To use this feature, the server version must be higher than 1.30.21/2.00.9, and you must use the share statement/function to share the engine, for example, share(engine, name) or share engine as name (the shared name of the engine must be the same as the engine name).
3.2. Parallel Processing
To process large volumes of data, you can specify the parameters filter and hash of function subscribeTable for parallel processing with multiple subscribers.
The following example uses reactive state engines to calculate a factor in parallel. Suppose the configuration parameter subExecutors is set to 4, 4 engines are thus created. Each engine subscribes to the stock data based on the hash value of the stockID and processes with a different subscription thread. The results generated by the 4 engines are output into one table.
share streamTable(1:0, `sym`price, [STRING,DOUBLE]) as tickStream
setStreamTableFilterColumn(tickStream, `sym)
share streamTable(1000:0, `sym`factor1, [STRING,DOUBLE]) as resultStream
for(i in 0..3){
rse = createReactiveStateEngine(name="reactiveDemo"+string(i), metrics =<cumsum(price)>, dummyTable=tickStream, outputTable=resultStream, keyColumn="sym")
subscribeTable(tableName=`tickStream, actionName="sub"+string(i), handler=tableInsert{rse}, msgAsTable = true, hash = i, filter = (4,i))
}Note: If multiple reactive state engines use one output table, the table must be a shared table. Otherwise, it is not thread-safe, and parallel writes to such table may cause system crashes.
3.3. Snapshot
DolphinDB's built-in streaming engines (except join engines) support snapshots to save the engine state and restore the engine after system interruption.
For example, the snapshot of a reactive state engine contains the latest processed message ID and the current state (i.e., the intermediate results) of the engine. If an exception occurs, the engine can be restored to the state of the last snapshot after rebooting, and the subscription will start from the next message once it has been processed.
share streamTable(1:0, `sym`price, [STRING,DOUBLE]) as tickStream
result = table(1000:0, `sym`factor1, [STRING,DOUBLE])
rse = createReactiveStateEngine(name="reactiveDemo", metrics =<cumsum(price)>, dummyTable=tickStream, outputTable=result, keyColumn="sym", snapshotDir= "/home/data/snapshot", snapshotIntervalInMsgCount=20000)
msgId = getSnapshotMsgId(rse)
if(msgId >= 0) msgId += 1
subscribeTable(tableName=`tickStream, actionName="factors", offset=msgId, handler=appendMsg{rse}, handlerNeedMsgId=true)To enable snapshot for a reactive state streaming engine:
(1) Specify the parameters snapshotDir and snapshotIntervalInMsgCount of function createReactiveStateEngine.
The parameter snapshotDir is used to specify the directory where the snapshot is saved, and snapshotIntervalInMsgCount indicates the number of messages between 2 snapshots. After a streaming engine is initialized, the system checks if a file named with the engine name and with a .snapshot extension is in the directory. For the above example, if the file /home/data/snapshot/reactiveDemo.snapshot already exists, the snapshot is loaded to restore the engine. You can obtain the message ID of the latest snapshot with function getSnapshotMsgId. If not, -1 is returned.
(2) Set the following parameters of function subscribeTable:
- The message offset (the position of the first message where the subscription begins) must be specified;
- The parameter handler must be
appendMsgwhich can have 2 parameters passed: msgBody and msgId; - The parameter handlerNeedMsgId must be true.
4. High Availability
4.1. HA Streaming
To implement uninterrupted streaming services, DolphinDB adopts a high-availability architecture of data replication based on Raft consensus algorithm to achieve high availability for streams.
4.2. HA Streaming Engines
In addition to the HA streaming mentioned above, DolphinDB also supports HA streaming engines for uninterrupted stream processing. If high availability is enabled for an engine, after the engine is created on the leader, it will be created on each follower, and the snapshot will be synchronized to followers as well. When a leader is down, the raft group will automatically switch to a new leader and resubscribe to the table, and the engine will be restored to the latest snapshot for continuous real-time processing.
The following example creates 2 high-availability stream tables and a high-availability reactive state engine, and then submits high-availability subscription on the raft group 2.
haStreamTable(raftGroup=2, table=table(1:0, `sym`price, [STRING,DOUBLE]), tableName="haTickStream", cacheLimit=10000)
haStreamTable(raftGroup=2, table=table(1:0, `sym`factor1, [STRING,DOUBLE]), tableName="result", cacheLimit=10000)
ret = createReactiveStateEngine(name="haReact", metrics=<cumsum(price)>, dummyTable=objByName("haTickStream"), outputTable=objByName("result"), keyColumn=`sym, snapshotDir= "/home/data/snapshot", snapshotIntervalInMsgCount=20000, raftGroup=2)
subscribeTable(tableName="haTickStream", actionName="haFactors", offset=-1, handler=getStreamEngine("haReact"), msgAsTable=true, reconnect=true, persistOffset=true, handlerNeedMsgId=true, raftGroup=2)Note:
To configure high availability for a streaming engine, parameters raftGroup, snapshotDir and snapshotIntervalInMsgCount must be specified.
When submitting subscription with function subscribeTable:
To enable high availability for the subscribers, the parameter raftGroup must be specified. The function can only be executed on the leader if raftGroup is set.
To enable high availability for the streaming engine, handlerNeedMsgId must be set to true and handler must be an engine object. The engine object is the handler returned when you create an engine, or it can be obtained with
getStreamEngine(engineName).To automatically resubscribe to a high-availability stream table, set reconnect to true to automatically reconnect to the new leader in case of a leader switch.
To avoid data loss on the subscribers, set persistOffset to true when subscribing to a high-availability stream table.
5. Streaming API
The consumer of streaming data may be a streaming engine, a third-party message queue, or a third-party program. DolphinDB provides streaming API for third-party programs to subscribe to streaming data. When new data arrives, API subscribers receive notifications on time. This allows DolphinDB streaming modules to be integrated with third-party applications. Currently, DolphinDB provides Java, Python, C++ and C# streaming API.
6. Status monitoring
6.1. Streaming
As streaming calculations are conducted in the background, DolphinDB provides function getStreamingStat to monitor the streaming status.
After calling function subscribeTable, you can check the subscription job with getStreamingStat().pubTables. When the worker thread begins data processing, the table subWorkers shows the corresponding thread status.
6.2. Streaming Engines
Function getStreamEngineStat returns a dictionary. The key indicates the streaming engine type, and the value is a table containing metrics of the engine.
For example, getStreamEngineStat().DailyTimeSeriesEngine returns a table as below:

There is only one Daily Time Series Engine engine1 in the system, and it occupies about 32 KB memory.
The memory usage of a streaming engine is mainly due to the continuous data ingested into the engine. When creating an engine, you can manage the frequency of historical data cleanup with parameter keyPurgeFreqInSec to control the memory usage.
It is recommended to remove the engines that are no longer in use from memory with function dropStreamEngine. To delete an engine handle, set the handle to null.
7. Performance Tuning
If an extremely large amount of streaming data arrive in a short period of time, we may see an extremely high value of queueDepth in table subWorkers on the subscriber node. When the message queue depth on the a subscriber node reaches queueDepthLimit, new messages from the publisher node are blocked from entering subscriber nodes. This leads to a growing message queue on the publisher node. When the message queue depth of the publisher node reaches queueDepthLimit, the system blocks new messages from entering the stream table on the publisher node.
There are several ways to optimize streaming performance:
Adjust parameters batchSize and throttle to balance the cache on the publisher and the subscriber nodes. This can achieve a dynamic balance between streaming data ingestion speed and data processing speed. To take full advantage of batch processing, we can set batchSize to wait for streaming data to accumulate to a certain amount before consumption. This, however, needs a certain amount of memory usage. If batchSize is too large, it is possible that some data below the threshold of batchSize get stuck in the buffer for a long time. To handle this issue, we can set parameter throttle to consume the buffer data even if batchSize is not met.
Increase parallelism by adjusting the configuration parameter subExecutors to speed up message queue processing on the subscriber node.
When each executor processes a different subscription, if there is great difference in throughput of different subscriptions or the complexities of calculation, some executors may idle. If we set subExecutorPooling=true, all executors form a shared thread pool to process all subscribed messages together. All subscribed messages enter the same queue and multiple executors read messages from the queue for parallel processing. With the shared thread pool, however, there is no guarantee that messages will be processed in the order they arrive. Therefore parameter subExecutorPooling should not be turned on when messages need to be processed in the order they arrive. By default, the system uses a hash algorithm to assign an executor to each subscription. If we would like to ensure the messages in two subscriptions are processed by the order as they arrive, we can specify the same value for parameter hash in function
subscribeTableof the two subscriptions, so that the same executor processes the messages of the two subscriptions.If the stream table enables synchronous persistence, disk I/O maybe become a bottleneck. One way to handle this is to use the method in section 2.4 to persist data in asynchronous mode while setting up a reasonable persistence queue by specifying maxPersistenceQueueDepth (default 10 million messages). Alternatively, we can also use SSD hard drives to improve write performance.
Publisher node may become the bottleneck. For example, there may be too many subscribing clients. We can use the following methods to handle this problem. First, we can reduce the number of subscriptions for each publisher node with multi-level cascading. Applications that can tolerate delay can subscribe to secondary or even third tier publisher nodes. Second, some parameters can be adjusted to balance throughput and latency. The parameter maxMsgNumPerBlock sets the size of the messages batches. The default value is 1024. In general, larger batches increase throughput but increase network latency.
If the ingestion speed of streaming data fluctuates greatly and peak periods cause the consumption queue to reach the queue depth limit (default 10 million), then we can modify configuration parameters maxPubQueueDepthPerSite and maxSubQueueDepth to increase the maximum queue depth of the publisher and the subscriber. However, as memory consumption increases as queue depth increases, memory usage should be planned and monitored to properly allocate memory.
8. Visualization
Streaming data visualization can be either real-time value monitoring or trend monitoring.
- Real-time value monitoring: conduct rolling-window computation of aggregate functions with streaming data periodically.
- Trend monitoring: generate dynamic charts with streaming data and historical data.
Various data visualization platforms support real-time monitoring of streaming data, such as the popular open source data visualization framework Grafana. DolphinDB has implemented the interface between the server and client of Grafana. For details, please refer to the tutorial: https://github.com/dolphindb/grafana-datasource/blob/master/README.md