ANSI SQL Compatibility of DolphinDB SQL
Starting from version 1.30.17 / 2.00.5, DolphinDB has progressively adapted its SQL dialect to align with ANSI SQL. As of version 1.30.22 / 2.00.10, DolphinDB is now compatible with the common syntax and keywords of ANSI SQL.
1. Compatibility with ANSI SQL
Starting from version 1.30.22/2.00.10, DolphinDB SQL supports the following features:
- All DolphinDB SQL keywords can be written in all-capital or all-lowercase letters;
- Line breaks are allowed for SQL statements, but note that:
- Keywords with multiple words (such as ORDER BY, GROUP BY, UNION ALL, INNER JOIN, etc.) cannot be split into two lines;
- If an alias for a column or table is not specified with keyword as, it must follow the original name without a line break.
Note: Database or table names in SQL statements are case sensitive.
The following topics will declare DolphinDB's conformance to the SQL standards in detail, including:
- common features of SQL-92;
- SQL data types and its conversion functions;
- other query features supported in DolphinDB.
1.1 Compatibility with SQL-92 Keywords
The following table lists 92 commonly used ANSI SQL-92 keywords, 62 of which are supported in DolphinDB. Of the 30 that are not supported: 5 are partially compatible, 7 are constraint-related (less important for data analysis), and 10 have alternatives.
DolphinDB SQL does not cover DCL commands that deal with user access control, therefore privilege-related keywords like GRANT and DENY are not included in the table below.
Note:
- √: Compatible
- ×: Incompatible
- ○: Partially compatible
- The "Description" field will provide the DolphinDB alternatives to incompatible or partially compatible keywords.
| Keyword (A to Z) | Compatibility | Description |
|---|---|---|
| ADD | √ | ALTER..ADD.. |
| ALL | √ | |
| ALTER | √ | |
| AND | √ | |
| ANY | √ | |
| AS | √ | |
| ASC | √ | |
| BETWEEN | √ | |
| BY | √ | |
| CASE | √ | |
| CAST / CONVERT | √ | function cast |
| COALESCE | √ | |
| COLUMN | √ | |
| COUNT | √ | |
| CREATE | √ | |
| CROSS | √ | CROSS JOIN |
| DELETE | √ | |
| DESC | √ | |
| DISTINCT | √ | |
| DROP | √ | |
| ELSE | √ | CASE WHEN..THEN..ELSE END |
| END | √ | CASE WHEN..THEN..ELSE END |
| EXISTS | √ | |
| FALSE | √ | false |
| FROM | √ | |
| FULL | √ | FULL JOIN |
| GROUP | √ | |
| HAVING | √ | |
| IF | √ | IF |
| IN | √ | |
| INNER | √ | INNER JOIN |
| INSERT | √ | |
| IS | √ | IS NULL |
| JOIN | √ | |
| LEFT | √ | LEFT JOIN, or function left |
| LIKE | √ | |
| LOWER | √ | function lower |
| MAX / MIN | √ | function max/min |
| NOT | √ | |
| NULL | √ | |
| NULLIF | √ | function nullIf |
| ON | √ | JOIN .. ON |
| OR | √ | |
| ORDER | √ | |
| REPEAT | √ | function repeat |
| RIGHT | √ | function right |
| ROLLUP/WITH ROLLUP | √ | |
| SELECT | √ | |
| SET | √ | |
| SUBSTRING | √ | function substr |
| SUM | √ | function sum |
| TABLE | √ | |
| TEMPORARY | √ | |
| THEN | √ | |
| TRIM | √ | function trim |
| TRUE | √ | true |
| UNION | √ | |
| UPDATE | √ | |
| UPPER | √ | function upper |
| VALUES | √ | INSERT INTO .. VALUES .. |
| WHEN | √ | |
| WHERE | √ | |
| WITH | √ | |
| CHARACTER_LENGTH | ○ | function strlen |
| FETCH | ○ | TOP / LIMIT clause |
| FIRST | ○ | TOP / LIMIT clause. Note that DolphinDB keyword FIRST (NULLS FIRST) is used to specify that null values should be returned before non-null values. |
| TRANSACTION | ○ | TRANSACTION |
| WHILE | ○ | FOR / DO-WHILE |
| CHECK | × | constraint-related |
| CONSTRAINT | × | constraint-related |
| CONTAINS | × | LIKE |
| DEFAULT | × | |
| ESCAPE | × | |
| EXCEPT | × | filter with a WHERE clause |
| EXEC | × | Note that DolphinDB keyword EXEC is used to generate a scalar or a vector from one column. |
| EXTRACT | × | built-in time-related functions to extract a part of a date/time |
| FOREIGN | × | |
| GLOBAL | × | |
| IDENTITY | × | custom identity column, or function
rowNo |
| INTERSECT | × | filter with a WHERE clause |
| LAST | × | CONTEXT BY clause together with LIMIT clause. Note that DolphinDB keyword LAST (NULLS LAST) is used to specify that Null values should be returned after non-null values. |
| NATURAL | × | INNER JOIN |
| OUTER | × | LEFT JOIN, RIGHT JOIN, FULL JOIN |
| OVERLAPS | × | EXITS |
| POSITION | × | function strpos |
| PRIMARY | × | |
| REFERENCES | × | |
| RESTRICT | × | |
| SOME | × | ANY |
| SPACE | × | |
| TRANSLATE | × | function
strReplace/regexReplace |
| UNIQUE | × | |
| VIEW | × |
1.2 Compatibility with SQL Data Types and Conversion Functions
- SQL data types
| Keyword (A to Z) | Compatibility | Description |
|---|---|---|
| CHAR / CHARACTER | ○ | STRING/SYMBOL |
| DATE | ○ | DATE or function date |
| DATETIME | ○ | DATETIME |
| DECIMAL / DEC / NUMERIC | ○ | DECIMAL32, DECIMAL64, DECIMAL128 |
| DOUBLE | ○ | DOUBLE |
| FLOAT / REAL | ○ | FLOAT |
| INT / INTEGER | ○ | INT, SHORT, LONG |
| TIME | ○ | SECOND |
| TIMESTAMP | ○ | DATETIME |
| VARCHAR | ○ | STRING, SYMBOL |
| YEAR | × |
- Conversion functions
| Keyword (A to Z) | Compatibility | Description |
|---|---|---|
| DAY | ○ | function dayOfMonth |
| HOUR | ○ | function hour |
| INTERVAL (keyword) | × | function temporalAdd (with duration
specified) |
| MINUTE | ○ | function minuteOfHour |
| MONTH | ○ | function monthOfYear |
| SECOND | ○ | function secondOfMinute |
| YEAR | ○ | function year |
1.3 Other SQL Features
DolphinDB provides keywords specific to distributed computing, as well as some special join methods.
| Keyword (A to Z ) | Description |
|---|---|
| asof join | joins records on the most recent match |
| context by | similar to OVER, which is used to perform grouping calculations |
| cgroup by | performs cumulative grouping calculations |
| exec | generates a scalar, vector, or matrix |
| map | executes the SQL statement in each partition separately |
| partition | selects partitions |
| pivot by / unpivot | similar to Oracle PIVOT, which is used to rearrange a column of a table on two dimensions |
| sample | takes a random sample of a number of partitions in a partitioned table |
| top / limit | specifies the number of records to return; limit
and context by can be used together to select the
first n or last n rows of a group. |
| truncate | removes all rows from a DFS table |
| window join | a generalization of asof join |
DolphinDB also provides some query hints for SQL statements:
| Keyword | Description |
|---|---|
| [HINT_LOCAL] | obtains only the calculation results on the local server |
| [HINT_HASH] | groups data with the hash algorithm by default |
| [HINT_KEEPORDER] | keeps the order of output records consistent with the input |
| [HINT_SEQ] | executes queries on partitions serially to save the concurrency overhead |
| [HINT_NOMERGE] | skips the merge step of intermediate results from map clause to improve the performance. Instead of returning the merged results in an in-memory table, only the handles of DFS tables are returned. |
| [HINT_PRELOAD] | (TSDB engine only) loads all data into memory before filtering with where-conditions |
| [HINT_EXPLAIN] | prints the query execution plan to monitor the real-time performance and execution order of a SQL query |
| [HINT_SORT] | applies sorting algorithm to data grouping |
| [HINT_VECTORIZED] | applies vectorization to data grouping |
2. Data Preparation
2.1 Dataset
The following example uses the HR Sample Table from Oracle as the sample data. It is saved as the following DolphinDB tables:
- countries (dimension table)
- departments (dimension table)
- employees (dimension table)
- jobs (dimension table)
- job_history (DFS table hashed by EMPLOYEE_ID)
- locations (dimension table)
- regions (dimension table)
The schema of each table is listed below:
- countries (COUNTRIES.csv)
| Column Name | Type |
|---|---|
| COUNTRY_ID | SYMBOL |
| COUNTRY_NAME | STRING |
| REGION_ID | INT |
- departments (DEPARTMENTS.csv)
| Column Name | Type |
|---|---|
| DEPARTMENT_ID | INT |
| DEPARTMENT_NAME | STRING |
| MANAGER_ID | INT |
| LOCATION_ID | INT |
- employees (EMPLOYEES.csv)
| Column Name | Type |
|---|---|
| EMPLOYEE_ID | INT |
| FIRST_NAME | STRING |
| LAST_NAME | STRING |
| STRING | |
| PHONE_NUMBER | STRING |
| HIRE_DATE | DATE |
| JOB_ID | SYMBOL |
| SALARY | INT |
| COMMISSION_PCT | DOUBLE |
| MANAGER_ID | INT |
| DEPARTMENT_ID | INT |
- jobs (JOBS.csv)
| Column Name | Type |
|---|---|
| JOB_ID | SYMBOL |
| JOB_TITLE | STRING |
| MIN_SALARY | INT |
| MAX_SALARY | INT |
- job_history (JOB_HISTORY.csv)
| Column Name | Type |
|---|---|
| EMPLOYEE_ID | INT |
| START_DATE | DATE |
| END_DATE | DATE |
| JOB_ID | SYMBOL |
| DEPARTMENT_ID | INT |
- locations (LOCATIONS.csv)
| Column Name | Type |
|---|---|
| LOCATION_ID | INT |
| STREET_ADDRESS | STRING |
| POSTAL_CODE | LONG |
| CITY | STRING |
| STATE_PROVINCE | STRING |
| COUNTRY_ID | SYMBOL |
- regions (REGIONS.csv)
| Column Name | Type |
|---|---|
| REGION_ID | INT |
| REGION_NAME | STRING |
2.2 Create Databases and Tables
To create databases and tables in DolphinDB, you can use the
create statement in a SQL statement, or use DolphinDB built-in
funtions.
The following scripts use the SQL statements.
(1) Create the database
create database "dfs://hr" partitioned by HASH([INT, 10])
(2) Create tables
Take "job_history" as an example. For scripts creating other tables, refer to create_db_table_sql.txt
STEP 1: Create a DFS table.
create table "dfs://hr"."job_history" (
EMPLOYEE_ID INT,
START_DATE DATE,
END_DATE DATE,
JOB_ID SYMBOL,
DEPARTMENT_ID INT
)
partitioned by EMPLOYEE_ID
STEP 2: Import data
The INSERT INTO statement in DolphinDB only supports appending records to
in-memory tables. For dimension and DFS tables, you need to use function
tableInsert/append!.
job_history_tmp=loadText(dir+"JOB_HISTORY.csv")
job_history = loadTable("dfs://hr", "job_history")
job_history.append!(job_history_tmp)
2.3 Modify Columns
Note that the name of a DFS database or table cannot be referenced in DolphinDB directly because it may conflict with the variable name. You must use the loadTable function to load a table.
The ALTER statement is used to add, delete or rename columns to an existing table.
alter table tableObj add columnName columnType;
alter table tableObj drop [column] columnName;
alter table tableObj rename [column] columnName to newColumnName;
Alternatively, you can use DolphinDB
built-in functions addColumn, dropColumns!, and
rename!.
Note: For DFS tables, only the OLAP engine supports delete and rename operations.
(1) Add columns
Add a column "FULL_NAME" for table "employees", and update the table.
employees = loadTable("dfs://hr", "employees") // load table "employees"
alter table employees add FULL_NAME STRING
employees = loadTable("dfs://hr", `employees) // reload the table after adding the new column
update employees set FULL_NAME=FIRST_NAME + " " + LAST_NAME
select * from employees
Output:

(2) Rename columns
Rename the column "FULL_NAME" to "EMPLOYEE_NAME".
alter table employees rename "FULL_NAME" to "EMPLOYEE_NAME"
employees = loadTable("dfs://hr", `employees) // reload the table after renaming the column
select * from employees
Output:
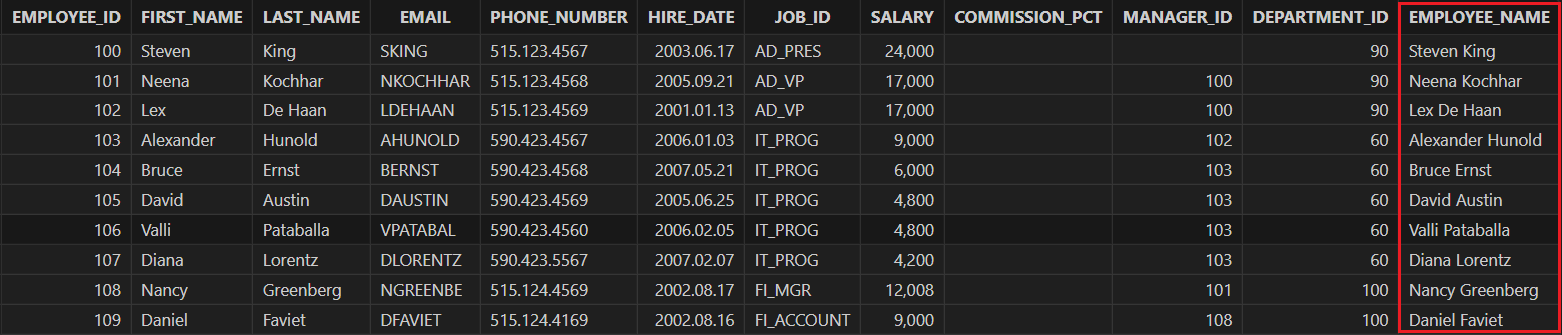
(3) Delete columns
Delete the newly added column "EMPLOYEE_NAME".
alter table employees drop EMPLOYEE_NAME
employees = loadTable("dfs://hr", `employees) // reload the table after deleting the column
select * from employees
Output:
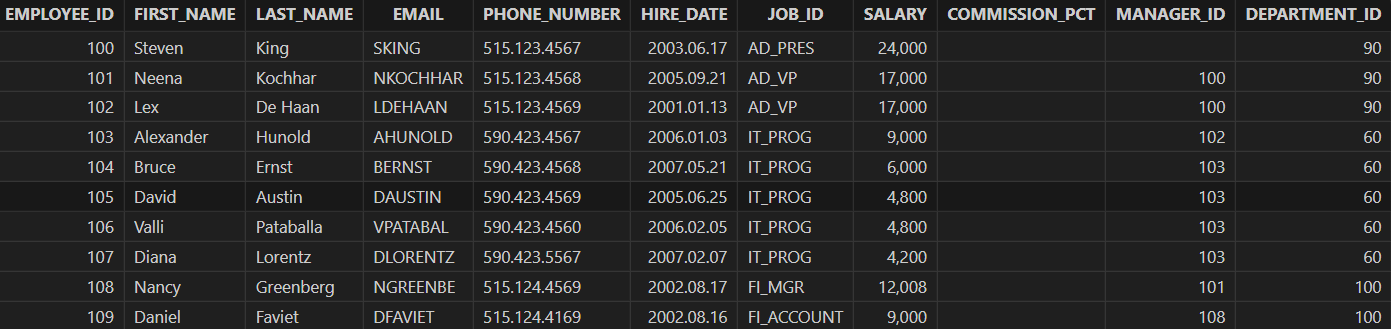
2.4 Delete Databases and Tables
(1) Delete the database
drop database if exists "dfs://hr"
(2) Delete the table
drop table if exists "dfs://hr"."job_history"
3. SQL Keywords
The table used in the following examples are all loaded using
tbName=loadTable("dfs://hr", `tbName).
3.1 Predicates
DolphinDB predicates are keywords that evaluate to true or false. The supported predicates include: (not) in, (not) like, between, (not) exists, is (not) null.
(1) (not) in
Query the records from table "employees" where "EMPLOYEE_ID" is [101, 103, 152].
select * from employees where EMPLOYEE_ID in [101, 103, 152];
Query the records from table "employees" where "EMPLOYEE_ID" is not in 100~150.
select * from employees where EMPLOYEE_ID not in 100..150;
(2) (not) like
Query the records from table "employees" where "PHONE_NUMBER" starts with "515".
select * from employees where PHONE_NUMBER like "515%";
Query the records from table "employees" where "JOB_ID" does not start with "AD".
select * from employees where JOB_ID not like "AD%";
(3) between
Count the number of employees hired in 2006.
select count(*) from employees where date(HIRE_DATE) between 2006.01.01 and 2006.12.31 // output: 24
(4) (not) exists
Since keyword exists does not support distributed
queries, we need to load dimension and DFS tables as in-memory tables first.
job_history = select * from loadTable("dfs://hr", "job_history")
employees = select * from loadTable("dfs://hr", "employees")
Query the records from the "employees" table for employees who have corresponding entries in the "job_history" table.
select * from employees where exists(select * from job_history where employees.EMPLOYEE_ID in job_history.EMPLOYEE_ID)
Query the records from the "employees" table for employees who do not have corresponding entries in the "job_history" table.
select * from employees where not exists(select * from job_history where employees.EMPLOYEE_ID in job_history.EMPLOYEE_ID)
(5) is (not) nullL
Query the records from table "departments" where "MANAGE_ID" is not null.
select * from departments where MANAGER_ID is not null
Query the records from table "employees" where "COMMISSION_PCT" is null.
select * from employees where COMMISSION_PCT is null
3.2 distinct
The keyword distinct is used with the select/exec clause to eliminate all the
duplicate records and return distinct values.
Note:
- The keyword
distinctsupports distributed queries to access data from DFS tables, but cannot be used with GROUP BY, CONTEXT BY, or PIVOT BY. - The SQL keyword
distinctdiffers from thedistinctfunction in that the latter does not preserve the order of the returned elements, and renames the columns in the result to "distinct_colName" by default.
select distinct COUNTRY_ID from locations // (1)
select distinct(COUNTRY_ID) from locations // (2)
Output:
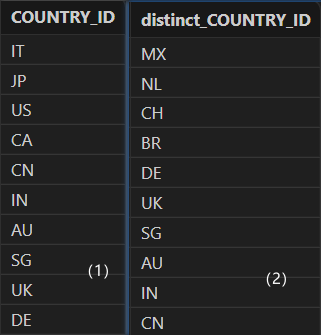
Query the records with distinct department IDs and manager IDs from table "employees".
select distinct DEPARTMENT_ID, MANAGER_ID from employees
3.3 any / all
The any and
all keywords allow you to perform a comparison between an
operand (i.e., a single column value) and a range of other values. The operand
includes: =, !=, >, <, <=, >=.
- any
Query the records on employees whose salary is the same as any employee in the purchasing department (with department ID=30).
select * from employees
where salary =
any(select salary
from employees
where department_id = 30)
order by employee_id
Output:
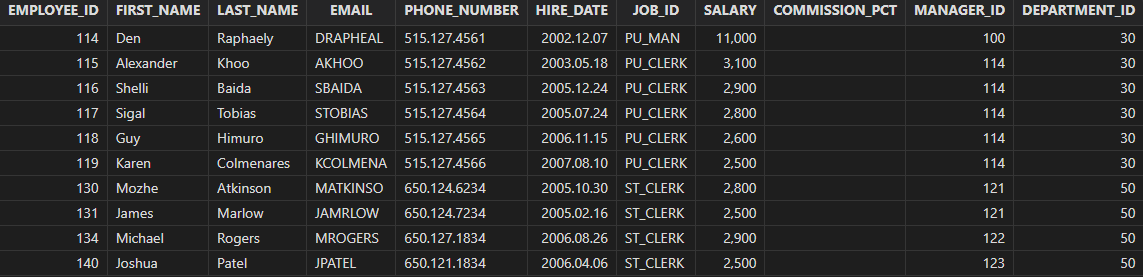
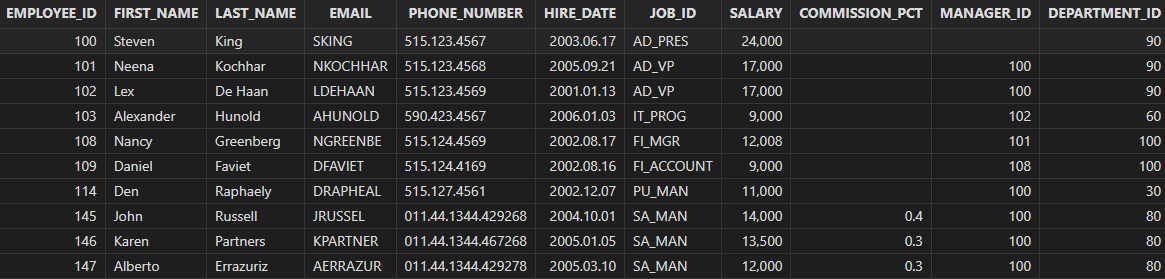
- all
Query the records on employees whose salary is greater than or equal to the minimum salary for the IT department (with department ID=60).
select * from employees
where salary >=
all (select salary from employees where department_id=60)
order by employee_id
Output:
Note: Currently, the
comparison such as ALL(1400, 3000) is not supported.
3.4 nulls first / last
The null ordering can be specified in an order by clause with nulls
first/last.
Sort the records by manager IDs in table "employees" with null values returned before non-null values.
select * from employees order by manager_id asc nulls first
Output:
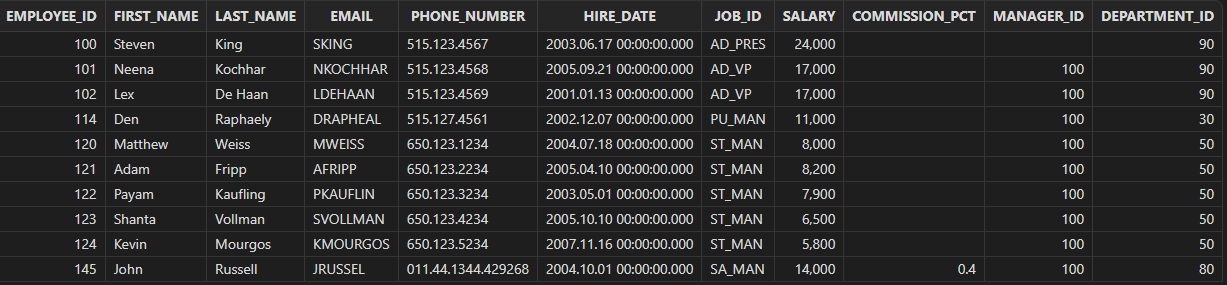
Sort the records by manager IDs in table "employees" with null values returned after non-null values.
select * from employees
order by manager_id asc nulls last
Output:

3.5 with
Using the with clause
simplifies complex SQL queries and improves readability. Repeated references to the
subquery may be more efficient as the data is easily retrieved from the temporary
table, rather than being re-queried by each reference.
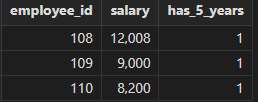
For example, we query the records on employees who have been working in the finance department for more than 5 years and have a salary of 8,000 or more.
The query first queries employees who have been working in the finance department (with department ID=100) for more than 5 years and generates a temporary table "employees_with_salary_increase". Then, queries are executed on table "employees_with_salary_increase" to select employees with a salary greater than 8,000. The results of this query are saved into table "employees_with_raise". The final results are obtained based on table "employees_with_raise".
with
employees_with_salary_increase as (
select employee_id, salary, year(now()) as current_year,
case when year(now()) - year(hire_date) > 5 then 1 else 0 end as has_5_years
from employees
where department_id = 100
),
employees_with_raise as (
select employee_id, salary, has_5_years
from employees_with_salary_increase
where salary > 8000
and has_5_years = 1
)
select employee_id, salary, has_5_years
from employees_with_raise
order by salary desc;
Output:
In subsequent versions, by using the with clause, subqueries can be used within
a complex query to perform operations in multiple steps and the temporary
results will be stored, which can greatly simplify the query process and improve
the efficiency.
3.6 union / union all
union/union all is used to combine the result
sets of 2 or more select / exec statements.
- union all
Query location IDs from the "locations" and "department" tables and use union
all to combine the query results (with duplicate records
keeping).
select location_id from locations
union all
select location_id from departments
order by location_id
Output:

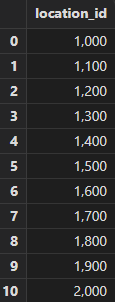
- union
Query location IDs from the "locations" and "department" tables and use union to
combine the query results (with duplicate records removed).
select location_id from locations
union
select location_id from departments
order by location_id
Output:
3.7 ROLLUP
ROLLUP automatically generates hierarchical summary results on top of GROUP BY results. It is commonly used to create statistical reports with subtotals and grand totals. DolphinDB supports the following two forms:
SELECT group_column(s), aggregate_function(column_name)
FROM table_name
WHERE condition
GROUP BY rollup(group_column_1, group_column_2, ...);SELECT group_column(s), aggregate_function(column_name)
FROM table_name
WHERE condition
GROUP BY group_column_1, group_column_2, ... WITH ROLLUP;The following examples are based on the employees table in the HR dataset. They count the number of employees by department and job, and generate department subtotals and a grand total.
Example 1: Use rollup to generate department subtotals and a grand total
SELECT department_id, job_id, count(*) as emp_cnt
FROM employees
GROUP BY rollup(department_id, job_id)
ORDER BY department_id, job_idResult levels:
-
(department_id, job_id): detail aggregation by department and job;
-
(department_id, NULL): department subtotal, aggregating all jobs in the department;
-
(NULL, NULL): grand total, aggregating the entire table.
Example 2: Equivalent WITH ROLLUP form
SELECT department_id, job_id, count(*) as emp_cnt
FROM employees
GROUP BY department_id, job_id WITH ROLLUP
ORDER BY department_id, job_idExample 3: Changing the order of grouping columns changes the subtotal level
ROLLUP subtotal levels depend on the order of grouping columns. The following form generates subtotals by job ((job_id, NULL)), rather than by department:
SELECT job_id, department_id, count(*) as emp_cnt
FROM employees
GROUP BY rollup(job_id, department_id)
ORDER BY job_id, department_id-
ROLLUP can only be used with the GROUP BY clause;
-
In the SELECT clause, columns other than grouping columns must be enclosed in aggregate functions (such as
count,sum,avg, ormax); -
In summary rows generated by ROLLUP, NULL values in the original data and summary rows generated by ROLLUP may all appear as NULL.
4. SQL Join
The syntax and functionality of SQL joins are mainly outlined in SQL-92 and SQL-99 specifications. As of version 2.00.10, DolphinDB has expanded support for joins with compatibility for both SQL-92 and SQL-99 syntax. This chapter will demonstrate the implementation of SQL joins in DolphinDB.
The following tables summarize the supported syntax in DolphinDB.
SQL92 Join
| Join | Syntax | Supported in DolphinDB |
|---|---|---|
| cross join | from t1,t2 | √ |
| equi join | from t1,t2 where t1.id= t2.id | √ |
| non-equi join | from t1,t2 where t1.id <op> t2.id, where <op> can be >, <,>=, <=, <>, between…and | √ |
| outer join | left join: from t1, t2 where t1.id = t2.id(+) right join: from t1, t2 where t1.id(+) = t2.id |
X |
| self join | from t t1, t t2 where t1.id <op> t2.id, where <op> can be =,>, <,>=, <=, <>, between…and | √ |
SQL99 Join
| Join | Syntax | Supported in DolphinDB |
|---|---|---|
| cross join | t1 cross join t2 | √ |
| equi join | t1 [inner] join t2 on t1.id = t2.id | √ |
| non-equi join | t1 join t2 on t1.id <op> t2.id,where <op> can be >, <,>=, <=, <>, between…and | X |
| outer join | left join: t1 left join t2 right join: t1 right join t2 full join: t1 full join t2 |
√ |
| natural join | t1 natural join t2 | X |
| join with the using clause | t1 [inner] join t2 using(id) | X |
| self join | t t1 join t t2 on t1.id <op> t2.id,where <op> can be =,>, <,>=, <=, <>, between…and | √ |
4.1 Table Joiners in DolphinDB
This section provides examples demonstrating how SQL joins are implemented in DolphinDB. Various table joiners are covered, including the cross join, inner join, left/semi join, right join and full join.
- cross join
Query all information on employees from both tables (employees a and employees b).
SQL 92
select *
from employees a, employees b
where a.employee_id <> b.employee_id
SQL99
select *
from employees a
cross join employees b
where a.employee_id <> b.employee_id
Part of the result:

- inner join
Query the ID of each employee and his/her manager's ID.
SQL92
select e1.employee_id, e1.manager_id
from employees e1, employees e2
where e1.manager_id = e2.employee_id
order by e1.employee_id, e1.manager_id
SQL99
select e1.employee_id, e1.manager_id
from employees e1
inner join employees e2
on e1.manager_id = e2.employee_id
order by e1.employee_id, e1.manager_id
Part of the result:

- left join
Query the ID of each employee and his/her manager's ID (if available).
select e1.employee_id, e1.last_name, e2.employee_id as manage_id, e2.last_name as manager_name
from employees e1
left join employees e2
on e1.manager_id = e2.employee_id
Part of the result:

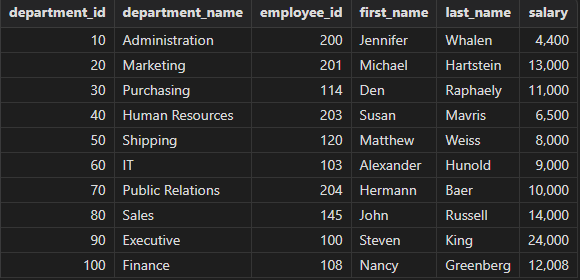
- left semi join
Query the records each department and one of its employees with salary higher than 2500.
select department_id, department_name,employee_id, first_name, last_name, salary
from departments
left semi join employees // or left semijoin
on departments.department_id = employees.department_id
and employees.salary > 2500
order by department_id
Part of the result:
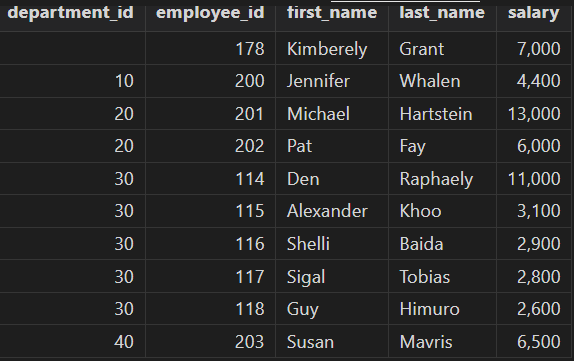
- right join
Query the information on each employee with a salary higher than 2500 and his/her department ID (if available).
select department_id, employee_id, first_name, last_name, salary
from departments
right join employees
on departments.department_id = employees.department_id
where employees.salary > 2500
order by department_id;
Part of the result:
- full join
Query the information on all employees and their departments.
select department_id, department_name, employee_id, first_name, last_name, salary
from departments a
full join employees b
on a.department_id = b.department_id
Part of the result:

4.2 Tables Supported by SQL Joins
SQL joins supports in-memory tables, DFS tables, dimension tables, and temporary tables (generated by uncorrelated subqueries).
Query the job history of each employee to test the compatibility of joins on each type of table.
select j.job_id, j.job_title, j.min_salary
, h.start_date, h.end_date
from jobs j
left join job_history h
on h.job_id = j.job_id
| Type | In-memory Table | DFS table | Dimension table | Subquery |
|---|---|---|---|---|
| In-memory Table | √ | √ | √ | √ |
| DFS table | √ | √ | √ | √ |
| Dimension table | √ | √ | √ | √ |
| Subquery | √ | √ | √ | √ |
4.3 Join Multiple Tables
In previous version, only two partitioned table can be joined. Now with the latest version, you can join multiple tables.
Join the employees and departments tables to obtain the detailed information on employees, including their IDs, names, managers, and departments.
select a.employee_id, a.last_name, a.manager_id, b.last_name as manager_name
, a.department_id, c.department_name
from employees a
inner join employees b
on a.manager_id = b.employee_id
inner join departments c
on a.department_id = c.department_id
Part of the result:

4.4 ON Clause
Query the job history of each employee. Both FI_ACCOUNT and AC_ACCOUNT are treated as AC_ACCOUNT (accountant).
select employee_id, j.job_id, j.job_title, j.min_salary
, h.start_date, h.end_date
from job_history h
left join jobs j
on j.job_id = case when h.job_id in ("FI_ACCOUNT", "AC_ACCOUNT") then "FI_ACCOUNT" else h.job_id end
order by employee_id
Output:

The join columns support:
- functions
- CASE WHEN
- columns of INT/STRING/SYMBOL type
Note that the constant expression, such as on 1=2, is not supported currently.
5. Compatibility for SQL Dialects
In addition to supporting ANSI SQL syntax, Oracle and MySQL deal with the
inconsistent behaviors of functions with the same name due to dialect-specific
features. Take function substr/concat for
example:
- For
select substr('HelloWorld',0,4), MySQL returns the null value; Forselect substr('HelloWorld',0,4) from dual, Oracle returns "Hell"; - MySQL
concatcan concatenate multiple strings, e.g.,select concat('my', 's', 'ql', '8'), while Oracleconcatcan only concatenate two strings.
Since version 1.30.22/2.00.10, DolphinDB has enhanced the compatibility for Oracle and MySQL dialects. You can select a dialect mode in a session and run scripts written in that dialect. In Oracle mode, DolphinDB provides a range of Oracle-compatible functions. In MySQL mode, DolphinDB supports using backticks (`) to quote table and column names as identifier delimiters, consistent with MySQL behavior; support for other MySQL-specific functions is currently limited. Future releases will continue to expand this support and further improve compatibility.
Note that only part of the functions or features of Oracle/MySQL are supported.
5.1 Use SQL Dialects with Client Tools
The dialect mode can be set in a session of the client tool, and then the parsing will be performed according to the specified SQL dialect. Take the DolphinDB GUI as an example:
Select File → Preferences → Always show sqlStd dropDown(√)

Then select the corresponding SQL dialect. Currently, three dialect modes are available: DolphinDB, Oracle and MySQL.
The following example queries information on employee salaries by department in Oracle mode, including department information, the number of employees, etc:
select
d.department_id,
d.department_name,
count(a.employee_id) as num_of_employee_id,
sum(a.salary) as total_salary,
avg(a.salary) as avg_salary,
max(a.salary) as max_salary,
decode(a.job_id, 'IT_PROG' , 'Programmer', 'FI_ACCOUNT', 'Accountant', 'Others') as job_title
from employees a
inner join departments d
on a.department_id = d.department_id
group by
d.department_id,
d.department_name,
decode(a.job_id, 'IT_PROG' , 'Programmer', 'FI_ACCOUNT', 'Accountant', 'Others') as job_title
Output:

The example above uses the
decode function. Other supported functions include:
concat, sysdate, nvl,
to_char, to_date, to_number,
regexp_like, trunc,
asciistr, instr, row_number.
With SQL dialect, the cost of SQL code migration is greatly reduced when migrating
from Oracle to DolphinDB.
MySQL mode is used in a similar way.
Currently, MySQL only supports the sysdate()
function.
5.2 Use SQL Dialects with APIs
- Java API
Specify SqlstdEnum (with three options: DolphinDB,
Oracle, MySQL) when constructing a
DBconnection object.
package com.dolphindb.sqlstd;
import com.xxdb.DBConnection;
import com.xxdb.comm.SqlStdEnum;
import com.xxdb.data.Entity;
import java.io.IOException;
public class OracleMode {
public static void main(String[] args) throws IOException {
DBConnection connection = new DBConnection(SqlStdEnum.Oracle);
connection.connect("192.168.1.206", 11702, "admin", "123456");
String sql = String.format(
"select employee_id, first_name, last_name, \n" +
" decode(job_id, 'IT_PROG' , 'Programmer', 'FI_ACCOUNT', 'Accountant', 'Others') as jobs_title\n" +
"from loadTable(%s, %s) a"
, "\"dfs://hr\"", "\"employees\""
);
Entity result = connection.run(sql);
System.out.println(result.getString());
}
}
- JDBC
Add the configuration parameter sqlStd to the url.
spring.datasource.url=jdbc:dolphindb://192.168.1.206:11702?databasePath=dfs://hr&sqlStd=Oracle
spring.datasource.username=admin
spring.datasource.password=123456
spring.datasource.driver-class-name=com.dolphindb.jdbc.Driver
6. Conclusion
Starting from version 1.30.22 / 2.00.10, DolphinDB has enhanced compatibility for ANSI SQL features, including:
- SQL keywords support all uppercase or all lowercase; field names are not case-sensitive, database/table names are case-sensitive;
- Line breaks in SQL statements;
- Predicates: (not) in, (not) like, (not ) between and, (not) exists, is (not) null;
- Keyword
distinctcan be used to eliminate duplicate records from multiple columns. As of the current version, it cannot be used withgroup by,context byorpivot by; order bysupportsnulls first/last;with asclause;union/union all;any/all;- Multiple joins (including cross join, inner join, left join, right
join, full join, left semi join):
- The use of comma (,) for cross join is supported. For
a join b, if not followed byoncondition, it means a cross join, otherwise it is an inner join. - Functions, and
case whenis supported in anoncondition. - Join columns can be of INT/STRING/SYMBOL type.
- The use of comma (,) for cross join is supported. For
- Joins support In-memory tables, partitioned tables, dimension tables, table objects returned by a SQL subquery. Note that the column referenced in a query cannot be used in its subquery.
In addition to supporting ANSI SQL syntax, DolphinDB has enhanced the compatibility for Oracle and MySQL dialects. You can select a dialect mode in a session and run scripts written in that dialect.
The compatibility of ANSI SQL will be enhanced in subsequent versions. For example, the window functions introduced in the SQL-2003 will be supported.