Storage-Compute Separation
DolphinDB's initial approach to storage-compute separation (pre-version 3.00.2) relied on stateless compute nodes. While these nodes can handle computational tasks, they lack data caching capabilities, requiring data to be pulled from storage nodes for each query - creating extra network overhead. Version 3.00.2 introduced compute groups, enabling data caching on compute nodes and delivering a more mature storage-compute separation.
Key features of DolphinDB storage-compute separation architecture:
- Resource Isolation: A compute group independently handles complex operations (SQL aggregations, filtering, joins, stream processing). Resources are allocated by compute group, ensuring isolation between groups.
- Fault Containment: Computing issues remain isolated from the storage layer, minimizing the impact of failures; Problems in one compute group don't affect others.
- Mixed Query Handling: Queries for each partition are routed based on data update frequency. Hot partitions are processed on data nodes to avoid compute node cache overhead, while cold partitions are handled on compute nodes with caching enabled for faster access, reducing data node load.
- Flexible Scaling: Compute nodes can be added or removed quickly during peak or quiet periods, with no impact on data nodes.
1. Architecture
1.1 Overview
DolphinDB's storage-compute separation architecture introduces compute groups which must contain compute nodes.
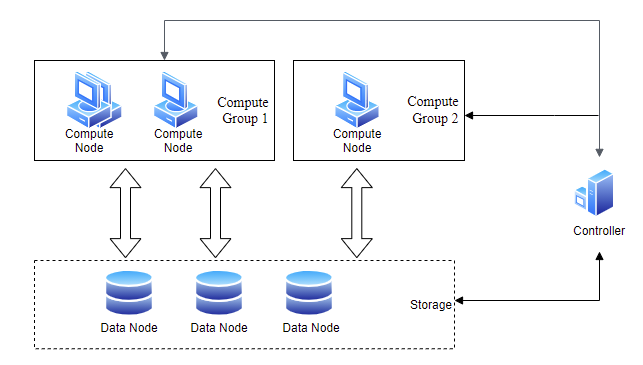
The architecture consists of three main components:
Compute Groups are collections of compute nodes that operate independently, providing resource isolation and fault containment between groups. Each group:
- Has a unique name and consists of compute nodes that belong exclusively to it.
- Has allocated computing capacity defined by its number of nodes, total memory size, and worker limits.
- Processes distributed SQL queries only within its own nodes.
- Can use configurable cache (memory and disk) to speed up queries.
- Retrieves data from data nodes over the network, with no permanent storage of its own.
Data Nodes handle data storage and local query tasks.
Controller (or controllers in high availability mode) coordinates and schedules tasks across the cluster.
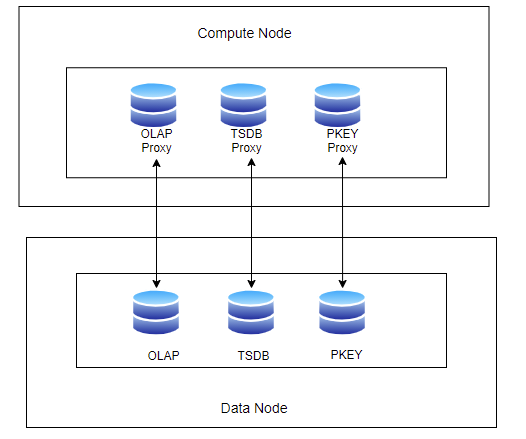
1.2 Proxy Storage Engines
DolphinDB employs multiple storage engines, each with its own optimized storage structure in cache. Rather than using a uniform cache layer on compute nodes, which would negate the specialized features of each engine, DolphinDB implements proxy storage engines on compute nodes. This approach ensures that data from each storage engine is managed by its corresponding proxy, preserving the performance optimizations designed for specific scenarios. Currently, cache management is available for OLAP, TSDB, and PKEY storage engines.
1.3 Distributed Query Processing
In the compute-storage separation architecture, queries are typically submitted to a node in a compute group and processed through a map → merge → reduce workflow. This node first obtains partition information from the controller and breaks down the query into partition-specific tasks (referred to simply as "partition queries"). The execution flows as follows:
Map Phase: Partition queries are routed to compute nodes within the same group. On cache hits, data is retrieved from compute node cache; on misses, the compute node either pulls data from data nodes or pushes the partition query to data nodes for local execution.
Merge Phase: The coordinator combines results from all map phase subtasks.
Reduce Phase (Optional): If needed, the coordinator performs additional processing on the merged results.
2. Caching Strategies
For time-series analysis, DolphinDB applies distinct caching strategies to hot write, hot query, and first-time query partitions. By fine-tuning these cache management strategies, users can achieve optimal performance in compute-storage separation architectures.
2.1 Queries for Hot Write Partitions
Time-series data is typically partitioned by time, with most writes occurring in recent partitions. Traditional caching becomes inefficient for these latest partitions as cached data quickly becomes outdated, leading to excessive cache reloads and I/O operations.
- Skip caching for hot write partitions: Queries for these partitions are pushed down to data nodes for execution, avoiding unnecessary data transfers.
- Cache stable partitions: In frequently updated partitions are cached to accelerate query performance.
- When set to 0: Partitions become eligible for caching immediately after updates.
- When non-zero: Partitions become cache-eligible only after the specified delay since their last update. During this delay, queries are sent directly to data nodes to avoid cache update overhead.
2.2 Queries for Hot Read Partitions
Caching rarely-queried partitions on compute nodes leads to low cache hits. To optimize cache efficiency, DolphinDB implements a hybrid design by selectively separating storage and computation: only frequently queried partitions are cached to the compute group, while other queries execute directly on data nodes.
- Set to 0: Partitions are cached on first access.
- Set to N (recommended range 1-5): Partitions are cached after N accesses by a compute group.
2.3 Cache Prewarming
Most object storage-based systems with uncoupled storage and computation (like Snowflake, StarRocks, and Redshift) face higher latency on first queries due to empty caches requiring high-latency storage access. DolphinDB allows first queries to be executed on data nodes with asynchronou cache prefetching for compute group through the xxx config parameter. In contrast, DolphinDB allows first queries to be executed directly on data nodes, with asynchronous cache prefetching for the compute group enabled through the enableComputeNodePrefetchData configuration parameter.
The implementation works as follows: The system pushes a query for an uncached partition down to the data node for execution, while simultaneously populating the compute group's cache in the background. When subsequent partition access occurs, it is likely to hit the cache on compute node, improving performance.
Compared to other systems, DolphinDB’s approach avoids network transfer costs that would typically result from cache misses and eliminates additional delay on first queries. By running some queries directly on data nodes, the system maintains performance close to the storage-computation coupled architecture.
The following diagram illustrates the complete partition query routing strategy.

3. Multi-Level Caching Mechanism
When the system routes a partition query to a compute node for direct execution, rather than redirecting to a data node, this compute node first checks whether the required data is available in cache. If the data is cached, it reads directly from cache. Otherwise, it fetches the data from storage nodes, caches it in the proxy storage engine, and then proceeds with execution.
Compute nodes implement a multi-level caching strategy. Data is first cached in memory, managed by a Clock replacement algorithm. When memory cache fills up, older data is evicted to disk cache, which uses a First-In-First-Out (FIFO) algorithm. Data stored in disk cache is compressed to save storage space. Once disk cache reaches capacity, the oldest data is removed.
While different proxy storage engines have varying cache formats and evictable units, DolphinDB employs a unified approach to multi-level cache design and eviction algorithms that remains consistent across different proxy storage engines, ensuring optimal performance.
4. Compute Group Configuration
4.1 Setting up Compute Groups
Add compute groups by including a "computeGroup" column in the cluster.nodes configuration file. This column is only applicable to compute nodes.
localSite,mode,computeGroup
192.168.1.243:23692:node0,datanode,
192.168.1.243:23693:node1,datanode,
192.168.1.243:23694:node2,datanode,
192.168.1.243:23695:node3,datanode,
192.168.1.243:23793:orca1,computenode,orca
192.168.1.243:23794:orca2,computenode,orca
192.168.1.243:23795:orca3,computenode,orca
192.168.1.243:23797:nova1,computenode,nova
192.168.1.243:23796:nova2,computenode,nova
192.168.1.243:23691:agent,agent,4.2 Scaling Compute Groups
Besides static configuration, compute groups can be scaled dynamically using built-in functions to match business demands during peak and off-peak periods.
Adding Compute Nodes
Use addNode to add nodes online and assign them to compute
groups using the computeGroup parameter. See function documentation for full
details.
Note: New nodes start inactive and require manual activation via the Web interface or CLI.
Removing Compute Nodes
Scaling down requires removing nodes from cluster using
removeNode, as removing nodes from compute groups is not
supported. See function
documentation for full details.
4.3 Managing Partition Cache
This section explains how to manage cache on compute nodes. For details on the built-in functions mentioned in this section, see the function documentation.
4.3.1 Overviewing Compute Group Caching
Track partition (chunk) cache information using
getComputeGroupChunksStatus(computeGroup). Omit the
computeGroup parameter to view all groups' status.
For each cached partition, these key details are provided:
- routedTo: Target compute node for partition queries.
- cachedOn: Cache location in the format alias:[version]. For example, orca2:[29] means the compute node orca2 caches partition data of version 29.
- computeGroup: Compute group(s) caching the partition. Note that partitions can be cached by multiple groups.
4.3.2 Monitoring and Managing Compute Node Cache
Use the getComputeNodeCacheStat function on a compute node
within a compute group to view that node’s total cache usage and capacity.
To get cache statistics for the entire compute group, aggregate the values
from all nodes in the group.
For detailed information about what data is cached on the node—such as which
tables or partitions are cached and the type of cache used—use the
getComputeNodeCacheDetails function.
After a graceful shutdown, the memory cache on a compute node is automatically flushed to disk. However, in cases of ungraceful shutdown, you can use the following functions for cache management:
flushComputeNodeMemCacheflushes the memory cache to disk.clearComputeNodeDiskCacheclears node disk cache.clearComputeNodeCacheclears both memory and disk cache.
Note that these operations cannot guarantee a complete flush.
5. Compatibility
Since version 3.00.2, compute nodes come in two types: regular nodes and compute group nodes. Regular compute nodes push down partition queries to data nodes for local operations, then combine the results. Compute group nodes can cache data and execute distributed queries within the group. A cluster can include both types of compute nodes.
The storage-compute separation implementation has introduced these behavior changes:
pnodeRun: When the nodes parameter is omitted and executed on a compute group node, it runs on all nodes in the group, executing the local function on each.repartitionDS: When local is false and executed on a compute group node, the data source is distributed only to nodes within the same group.
6. Access Control
Compute group access is controlled by the COMPUTE_GROUP_EXEC privilege, which determines whether users or groups can access specific compute groups. For example, you can restrict users to compute groups within their department by granting or denying this privilege.
Privilege checks occur at connection time, throwing exceptions for unauthorized access. Permissions are automatically revoked when compute groups are deleted.
7. Performance Testing
This section compares the performance of DolphinDB's storage-compute separation architecture with its integrated architecture. Testing was conducted on 3 servers with the following configuration:
- Operating System: CentOS Linux
- CPU: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
- Memory: 512GB (16x32 DDR4 3200 MT/s)
Three high-availability clusters were set up on the servers, with double replica per chunk. Each server had 1 controller, 1 data node, and 2 compute nodes (organized into two compute groups).
The test involved creating OLAP, TSDB, and PKEY tables, with data ranging from 2012.01.01 to 2012.03.10. The tables were COMPO partitioned: value partitioning on dates and hash partitioning on stock symbols.
Each partition contained 1,000,000 randomly generated records. The performance of different storage engines for querying data by specific dates was tested. The results are shown in the table below (in milliseconds):
| OLAP | TSDB | PKEY | |
|---|---|---|---|
| Data Node | 449.023 | 429.939 | 479.943 |
| Compute Node (Cache Miss) | 11370.401 | 35215.104 | 9087.79 |
| Compute Node (Cache Hit) | 436.844 | 405.112 | 462.049 |
As shown, when the cache is missed, the query time on compute nodes is, on average, 42 times longer than on data nodes. This is because compute nodes must fetch data from the data nodes, adding network overhead. However, when the cache is hit, the query performance on compute nodes is similar to, or even better than, data nodes. This is due to the compute nodes' caching mechanism, which uses proxy storage engines optimized for each storage engine type, leveraging their advantages during query execution.
8. Configuration Parameters and Functions
For configuration parameters related to the storage-compute separation model, see:
| Parameter | Description | Node |
|---|---|---|
| computeNodeCacheDir = <HomeDir>/Disaggregation | Specifies the directory for compute node cache. To specify multiple directories on the node, separate the paths with commas, e.g., /volume0/path/to/cache, /volume1/path/to/cache, /volume2/path/to/cache. The cache will be distributed across the directories based on disk load. | Compute Node |
| computeNodeCacheMeta=<computeNodeCacheDir>/meta | Specifies a directory for the compute node cache metadata. Default: <computeNodeCacheDir>/meta. If multiple directories are specified for computeNodeCacheDir, the first path is used. | Compute Node |
| computeNodeMemCacheSize=1 | A non-negative integer representing the maximum memory cache size (in GB) for the compute node. The default value is 1, and the maximum is 50% * maxMemSize. | Compute Node |
| computeNodeDiskCacheSize=64 | A non-negative integer representing the maximum disk cache size (in GB) for the compute node. The default value is 64. | Compute Node |
| enableComputeNodeCacheEvictionFromQueryThread=true | A Boolean value specifying whether query threads can perform cache eviction. Setting to true (default) improves the cache cleanup efficiency, but may increase query latency under limited cache conditions. | Compute Node |
| computeNodeCachingDelay=360 | A non-negative integer representing the time interval (in seconds) that must elapse after the last update of a partition before it can be cached on the compute node. Default is 360. | Controller |
| computeNodeCachingQueryThreshold=1 | A non-negative integer representing the threshold for caching based on the number of queries on a partition. The default value is 1, and the maximum is 32767. A partition can be cached on the compute node after exceeding the query threshold. | Controller |
| enableComputeNodePrefetchData=true | A Boolean value that determines the system's behavior during cache misses (i.e., when a partition cannot be found in the cache). When enabled (default), the system simultaneously assigns queries to the data node while initiating asynchronous cache prefetching in the compute group. This can lower latency but may increase network and CPU load due to repeated query execution. When disabled, queries are processed exclusively within the compute group. | Controller |
| enableTransferCompressionToComputeNode=true | A boolean value, defaulting to true. Controls whether the data node compresses data before transferring it to the compute node. | Data Node |
- addNode: Add node(s) to a cluster online.
- getComputeGroupChunksStatus: Obtain the metadata about all database chunks on the compute nodes.
- getComputeNodeCacheStat:Call the function on a compute node within a compute group to query that node’s total cache usage and capacity.
- getComputeNodeCacheDetails: Call the function on a compute node within a compute group to query the detailed composition of the cache.
- flushComputeNodeMemCache: Invoke the function to flush the memory cache to disk on the compute nodes.
- clearComputeNodeDiskCache: Invoke the function to clear the disk cache on the compute nodes.
- clearComputeNodeCache: Call the function on a compute node within a compute group to clear the memory and disk cache.
- setComputeNodeCachingDelay: Modify the value of computeNodeCachingDelay online.
- getComputeNodeCachingDelay: Get the value of computeNodeCachingDelay on the current node.
- setPrefetchComputeNodeData: Modify the value of enableComputeNodePrefetchData online.
- getPrefetchComputeNodeData: Get the value of enableComputeNodePrefetchData on the current node.