Importing Text Files
DolphinDB provides flexible methods for text file import. Its built-in functions support data import by specifying column delimiters (such as commas, commonly used in CSV files). For files with fixed-width columns without separators, API methods or custom plugins are required.
The page will introduce various methods and techniques for importing text data with detailed examples.
Built-in Functions
DolphinDB provides the following functions to facilitate text file import:
loadText: Imports text files as in-memory tables.ploadText: Imports text files as partitioned in-memory tables in parallel, offering better import performance thanloadText.loadTextEx: Imports text files directly into either a distributed database or in-memory database.textChunkDS: Divides the text file into multiple data sources. It can be used with functionmrto load data.
The following table outlines common parameters of these functions.
| Parameter | Description |
|---|---|
| filename | A string indicating the directory of input text file. |
| delimiter | A STRING scalar indicating the table column separator. It can consist of one or more characters, with the default being a comma (','). |
| schema |
A table with the following columns, among which "name" and "type" columns are required.
|
| skipRows | An integer between 0 and 1024 indicating the rows in the beginning of the text file to be ignored. The default value is 0. |
| arrayDelimiter | A single character indicating the delimiter for columns holding the array vectors in the file. If specified, the corresponding type column of the schema parameter must be set as array vector. |
| containHeader | A Boolean value indicating whether the file contains a header row. If not set, the system automatically analyzes first row. |
These built-in functions support loading text files from the DolphinDB server’s local disk. Therefore, users must first save the decompressed dataset to the server.
Getting Started
DolphinDB provides two primary data import approaches: users can either load data into in-memory tables for processing before writing to databases, or directly import data into database tables.
Loading to Memory and Importing to Database
DolphinDB provides loadText function for importing data from
text files into memory. Users can process and clean data in memory and then
import the processed data to database.
For example, the following is a CSV file named demo1.csv, which contains the columns: time (timestamp), customerId (device ID), temp (temperature), and amp (current).
time,customerId,temp,amp
2024.01.01T00:00:01.000,DFXS001,49,20.017752074636518
2024.01.01T00:00:02.000,DFXS001,8,91.442090226337313
2024.01.01T00:00:03.000,DFXS001,16,23.859648313373327
2024.01.01T00:00:04.000,DFXS001,98,78.651371388696134
2024.01.01T00:00:05.000,DFXS001,14,24.103266675956547Since CSV file is comma-separated and delimiter is (“,“) by default, users
can import the data into a DolphinDB in-memory table using the
loadText function with just the filename
specified.
dataFilePath = "/home/data/demo1.csv"
loadText(filename = dataFilePath)Alternatively, specify delimiter explicitly:
tmpTB = loadText(filename = dataFilePath, delimiter = ",")Check the results:
select * from tmpTB;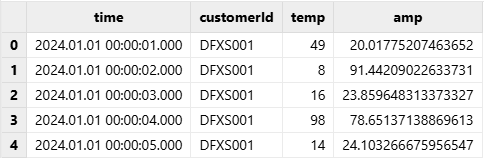
After loading and processing data in memory, users can use
tableInsert or append! functions to import
data to the distributed database. Ensure that the target database and table are
already created before proceeding.
Script for creating the database and table:
create database "dfs://demoDB" partitioned by VALUE([2024.03.06])
create table "dfs://demoDB"."data"(
time TIMESTAMP,
customerId SYMBOL,
temp INT,
amp DOUBLE
)
partitioned by timeThen write data into database with the following script:
dfsTable = loadTable("dfs://demoDB", "data")
tmpTB = loadText(filename = dataFilePath)
tableInsert(dfsTable, tmpTB)Importing to Database Directly
In addition to explicitly using in-memory tables for database import, DolphinDB
provides loadTextEx function that combines loading, cleaning,
and storage into one streamlined process. Ensure that the target database and
table are already created before proceeding.
The following example demonstrates how to import demo1.csv to table
“data” in database “demoDB”. To start with an empty database, use the
truncate function to remove existing rows.
// remove existing rows
truncate("dfs://demoDB","data")
// import to database
dataFilePath="/home/data/demo1.csv"
loadTextEx(dbHandle=database("dfs://demoDB"), tableName="data",
partitionColumns=["time"], filename=dataFilePath);Check the results:
pt = loadTable("dfs://demoDB","data")
select * from ptOutput:
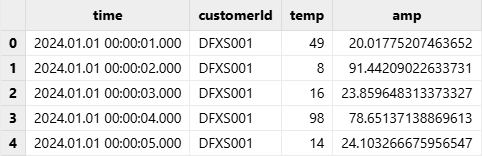
Unlike loadText, loadTextEx requires users to
specify database details including database name, table name, and partitioning
columns. Besides, loadTextEx offers transform parameter
to clean or process data directly during database import. For more informatin
about transform parameter, see Data Cleaning and Preprocessing.
Handling Column Names and Data Types
Unlike traditional systems requiring manual format settings, DolphinDB automatically identifies both column names and data types when importing text files. It identifies headers when the first row has no numeric-leading columns, then infers column types through data sampling.
While sampling-based detection is generally reliable, occasional manual adjustments by modifying schemaparameter may be needed.
Extracting Text File Schema
Users can use the extractTextSchema function to preview a text
file's schema before data loading, including details like column names, data
types, and the number of columns. It helps users identify potential issues such
as incorrect delimiters or mismatched data types and modify the schema
accordingly for proper data loading.
For example, use extractTextSchema to get the schema of the
sample file sample.csv:
dataFilePath="/home/data/sample.csv"
schemaTB=extractTextSchema(dataFilePath)
schemaTB;
/* output
name type
---------- ------
symbol SYMBOL
exchange SYMBOL
cycle INT
tradingDay DATE
date DATE
time INT
open DOUBLE
high DOUBLE
low DOUBLE
close DOUBLE
volume INT
turnover DOUBLE
unixTime LONG
*/Specifying Column Names and Types
If the column names or data types automatically inferred by the system are not
expected, we can specify the column names and data types by modifying the schema
table generated by function extractTextSchema or creating the
schema table directly.
Specifying Column Names
For example, use the following script to modify schema and rename column “symbol” as “securityID” :
dataFilePath="/home/data/sample.csv"
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set name = ["securityID","exchange","cycle","tradingDay","date","time","open","high","low","close","volume","turnover","unixTime"]Use function loadText to import a text file and specify
schema parameter as the modified schemaTB.
tmpTB=loadText(filename=dataFilePath,schema=schemaTB);Call function schema to view the table schema. Column “symbol”
has been renamed as “securityID”.
tmpTB.schema().colDefs;
/* output
name typeString typeInt extra comment
---------- ---------- ------- ----- -------
securityID SYMBOL 17
exchange SYMBOL 17
cycle INT 4
tradingDay DATE 6
date DATE 6
time INT 4
open DOUBLE 16
high DOUBLE 16
low DOUBLE 16
close DOUBLE 16
volume LONG 5
turnover DOUBLE 16
unixTime LONG 5
*/Specifying Data Type
For example, if the column 'volume' is automatically recognized as INT, and the required type is LONG, we need to specify the data type of column 'volume' as LONG in the schema table.
dataFilePath="/home/data/sample.csv"
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set type="LONG" where name="volume";Use function loadText to import a text file and specify
schema parameter as schemaTB.
tmpTB=loadText(filename=dataFilePath,schema=schemaTB);Call function schema to view the table schema. The data type of
column “volume” is LONG.
tmpTB.schema().colDefs;
/* output
name typeString typeInt extra comment
---------- ---------- ------- ----- -------
symbol SYMBOL 17
exchange SYMBOL 17
cycle INT 4
tradingDay DATE 6
date DATE 6
time INT 4
open DOUBLE 16
high DOUBLE 16
low DOUBLE 16
close DOUBLE 16
volume LONG 5
turnover DOUBLE 16
unixTime LONG 5
*/Specifying the Format of Temporal Types
For dates and time values, if the automatically inferred data types do not meet expectations, we need to specify not only the data type, but also the format (represented by a string) in column 'format' of the schema table, such as "MM/dd/yyyy". For more details about temporal formats in DolphinDB, see Parsing and Format of Temporal Variables.
Execute the following script to generate the data file for this example.
dataFilePath="/home/data/timeData.csv"
t=table(["20190623 14:54:57","20190623 15:54:23","20190623 16:30:25"] as time,`AAPL`MS`IBM as sym,2200 5400 8670 as qty,54.78 59.64 65.23 as price)
saveText(t,dataFilePath);Before loading the file, use function extractTextSchema to get
the schema of the data file:
schemaTB=extractTextSchema(dataFilePath)
schemaTB;
/* output
name type
----- ------
time SECOND
sym SYMBOL
qty INT
price DOUBLE
*/The automatically inferred data type of column 'time' is SECOND while the expected data type is DATETIME. If the file is loaded without specifying parameter schema, column 'time' will be empty. In order to load the file correctly, we need to specify the data type of column 'time' as DATETIME and the format of the column as "yyyyMMdd HH:mm:ss".
update schemaTB set type="DATETIME" where name="time"
schemaTB[`format]=["yyyyMMdd HH:mm:ss",,,];Use function loadText to import a text file and specify
schema parameter as schemaTB.
tmpTB=loadText(filename=dataFilePath,schema=schemaTB)
tmpTB;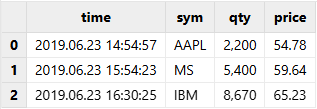
Importing Selected Columns
Users can import some columns instead of all columns from a text file by modifying the schema table.
For example, suppose the data analysis focuses solely on 7 columns: symbol, date,
open, high, close, volume, and turnover. First, use function
extractTextSchema to get the text file schema:
dataFilePath="/home/data/sample.csv"
schemaTB=extractTextSchema(dataFilePath);Use function rowNo to generate indices of the columns in the
text file and assign them to column "col" in the schema table. Modify the schema
table so that only the rows indicating the 7 columns to be imported remain.
update schemaTB set col = rowNo(name)
schemaTB=select * from schemaTB where name in `symbol`date`open`high`close`volume`turnover;- Column indices start from 0. In the example above, the column index for the first column 'symbol' is 0.
- The order of the columns cannot be changed when loading text files. To
adjust the order of the columns, use function
reorderColumns!after loading the text file.
Finally, use function loadText and specify parameter
schema to import the selected columns from the text file.
tmpTB=loadText(filename=dataFilePath,schema=schemaTB);Call function schema to view the table schema. Only the selected
columns are imported:
tmpTB.schema().colDefs;
/* output
name typeString typeInt extra comment
---------- ---------- ------- ----- -------
symbol SYMBOL 17
date DATE 6
open DOUBLE 16
high DOUBLE 16
low DOUBLE 16
close DOUBLE 16
volume LONG 5
turnover DOUBLE 16
*/Skipping Rows
When importing text files, users frequently encounter header descriptions, comments, or metadata rows that need to be bypassed before data processing. DolphinDB addresses this with the skipRows parameter, allowing users to exclude up to 1024 initial rows from the import process.
For example, use function loadText to import sample.csv
and then get the total rows:
dataFilePath="/home/data/sample.csv"
tmpTB=loadText(filename=dataFilePath)
select count(*) from tmpTB;
/* output
count
-----
5040
*/Check the first 5 rows:
select top 5 * from tmpTB;
Set skipRows=1000 in function loadText to skip the first 1000
lines of the text file when importing the file:
tmpTB=loadText(filename=dataFilePath,skipRows=1000)
select count(*) from tmpTB;
/* output
count
-----
4041
*/Check the first 5 rows:

If the first line of the file contains column headers, specifying skipRows will also remove these headers, resulting in the columns being labeled with default names like col0, col1, col2, and so on.
To retain the original column names and skip the first n rows, we can get the
schema of the text file with function extractTextSchema, and
then specify parameter schema when importing:
schema=extractTextSchema(dataFilePath)
tmpTB=loadText(filename=dataFilePath,schema=schema,skipRows=1000)
select count(*) from tmpTB;
/* output
count
-----
4041
*/Check the first 5 rows:
select top 5 * from tmpTB;
Data Cleaning and Preprocessing
DolphinDB provides various built-in functions for common data cleaning task, including handling missing values, duplicate values, and outliers, and performing data normalization and standardization. This section focuses on several common scenarios.
DolphinDB provides two methods for importing data: loadText function
and loadTextEx function (See Getting Started). While both methods support basic data cleaning,
loadTextEx introduces a distinctive transform parameter
that enables data cleaning and preprocessing during data import. This parameter
accepts a unary function that processes the loaded table and returns a cleaned
dataset, which is then directly written to the distributed database without
intermediate memory storage. Our focus will be on practical applications of the
transform parameter in loadTextEx.
Converting Integers into Specified Temporal Types
In such case, specifying the schema directly may result in empty column.
One way is to use the transform parameter of the
loadTextEx function to wrap the
replaceColumn! function for type conversion.
First, create a distributed database and a table.
dataFilePath="/home/data/sample.csv"
dbPath="dfs://testDB"
db=database(dbPath,VALUE,2018.01.02..2018.01.30)
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set type="TIME" where name="time"
tb=table(1:0,schemaTB.name,schemaTB.type)
tb=db.createPartitionedTable(tb,`tb1,`date);Define a user-defined function i2t to encapsulate the data
processing logic, converting the time column to TIME type with millisecond
precision.
def i2t(mutable t){
return t.replaceColumn!(`time,temporalParse(lpad(string(t.time), 9,`0), "HHmmssSSS"))
}When processing data in a user-defined function, please try to use in-place modifications (functions that finish with !) if possible for optimal performance.
Call function loadTextEx and assign function
i2t to parameter transform. The system executes
function i2t with the imported data, and then saves the result
to the database.
loadTextEx(dbHandle=db,tableName=`tb1,partitionColumns=`date,filename=dataFilePath,transform=i2t);Column 'time' is stored as data type TIME instead of INT in the text file:
select top 5 * from loadTable(dbPath,`tb1);
Data Type Conversion between Temporal Types
We may need to load a DATE type column in a text file as MONTH type to the database. We can use the same methodology as in the previous section.
First, create a distributed database and a table.
dataFilePath="/home/data/sample.csv"
dbPath="dfs://testDB"
db=database(dbPath,VALUE,2018.01.02..2018.01.30)
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set type="MONTH" where name="tradingDay"
tb=table(1:0,schemaTB.name,schemaTB.type)
tb=db.createPartitionedTable(tb,`tb2,`date)Define a user-defined function d2m to preprocess the data,
specifying the data type of column 'tradingDay' as MONTH.
def d2m(mutable t){
return t.replaceColumn!(`tradingDay,month(t.tradingDay))
}Define a user-defined function d2m to preprocess the data,
specifying the data type of column 'tradingDay' as MONTH.
tmpTB=loadTextEx(dbHandle=db,tableName=`tb2,partitionColumns=`date,filename=dataFilePath,transform=d2m);Column 'tradingDay' is stored as MONTH in the database instead of as DATE in the text file:
select top 5 * from loadTable(dbPath,`tb2);
Handling Null Values
Efficient handling of missing values is essential when working with real-world
datasets. DolphinDB offers built-in functions like bfill,
ffill, interpolate, and
nullFill, enabling quick and effective handling of
incomplete data in tables. As parameter transform only takes a function
with one parameter, to assign a DolphinDB built-in function with multiple
parameters to transform, we can use partial
application to convert the function into a function with only one
parameter. The following example assigns function nullFill! to parameter
transform to fill the null values in the text file with 0.
db=database(dbPath,VALUE,2018.01.02..2018.01.30)
tb=db.createPartitionedTable(tb,`tb1,`date)
tmpTB=loadTextEx(dbHandle=db,tableName=`tb1,partitionColumns=`date,filename=dataFilePath,transform=nullFill!{,0});Importing Data as Array Vectors
In DolphinDB, an array vector is a two-dimensional vector where each row is a variable-length vector. With array vectors, multiple columns with the same data type, such as columns of a stock's quotes, can be stored in one single column.
Advantanges of using an array vector:
- It can significantly reduce the complexity of some common queries and calculations.
- When multiple columns contain repetitive data, using an array vector helps improve data compression and enhances query performance.
Three ways of importing:
- Import text files directly as array vectors.
- Combine columns into an array vector after importing text files as in-memory tables and then import into the distributed database.
- Use
loadTextExfunctioN with transform specified to automatically process array vector data before importing to the distributed database.
Importing Text Files Directly as Array Vectors (Version 2.00.4 and Later)
Currently, DolphinDB doesn't support importing multiple columns from a text file into a single column directly. To import array vectors:
- Combine the related columns into one and separate the values in each row with a user-specified delimiter.
- When importing data, specify the parameter arrayDelimiter to define the delimiter. The system will then parse the column containing the delimiter as an array vector.
Create a table with an array vector column and save it into a CSV file.
bid = array(DOUBLE[], 0, 20).append!([1.4799 1.479 1.4787, 1.4796 1.479 1.4784, 1.4791 1.479 1.4784])
ask = array(DOUBLE[], 0, 20).append!([1.4821 1.4825 1.4828, 1.4818 1.482 1.4821, 1.4814 1.4818 1.482])
TradeDate = 2022.01.01 + 1..3
SecurityID = rand(`APPL`AMZN`IBM, 3)
t = table(SecurityID as `sid, TradeDate as `date, bid as `bid, ask as `ask)
saveText(t,filename="/home/data/t.csv",delimiter=',',append=true)Update the bid and ask columns in schema table as array vector type.
path = "/home/data/t.csv"
schema=extractTextSchema(path);
update schema set type = "DOUBLE[]" where name="bid" or name ="ask"Use loadText or loadTextEx to import data,
specify the parameter arrayDelimiter to indicate the delimiter (which is
"," in the example) for columns holding the array vectors in the file.
//Use loadText to import text files as in-memory tables
t = loadText(path, schema=schema, arrayDelimiter=",")
//Use loadTextEx to import text files into a distributed database
//Create the target database and table
db = database(directory="dfs://testTSDB", partitionType=VALUE, partitionScheme=`APPL`AMZN`IBM, engine="TSDB" )
name = `sid`date`bid`ask
type = ["ESYMBOL","DATE","DOUBLE[]","DOUBLE[]"]
tbTemp = table(1:0, name, type)
db.createPartitionedTable(tbTemp, `pt, `sid, sortColumns=`date)
pt = loadTextEx(dbHandle=db, tableName=`pt, partitionColumns=`sid, filename=path, schema=schema, arrayDelimiter=",")Processing in Memory
If it is not easy to modify text files directly, you can import the files as in-memory tables, then combine the columns into an array vector before loading the data into distributed databases.
The following example shows how to store the bid and offer prices of level 2 snapshot data as an array vector.
See the script for creating databases and tables and generating simulated data.
First, use loadText to load simulated data to memory. Then, use
fixedLengthArrayVector to concatenate multiple columns of
bid and offer prices and return a single column respectively . Last, import the
processed data into the database.
snapFile="/home/data/snapshot.csv"
dbpath="dfs://LEVEL2_Snapshot_ArrayVector"
tbName="Snap"
schemas=extractTextSchema(snapFile)
update schemas set type = `SYMBOL where name = `InstrumentStatus
//Use loadText to load text files. Elapsed time: 90s.
rawTb = loadText(snapFile,schema=schemas)
//Save as a single column. Elapsed time: 15s.
arrayVectorTb = select SecurityID,TradeTime,PreClosePx,OpenPx,HighPx,LowPx,LastPx,TotalVolumeTrade,TotalValueTrade,InstrumentStatus,fixedLengthArrayVector(BidPrice0,BidPrice1,BidPrice2,BidPrice3,BidPrice4,BidPrice5,BidPrice6,BidPrice7,BidPrice8,BidPrice9) as BidPrice,fixedLengthArrayVector(BidOrderQty0,BidOrderQty1,BidOrderQty2,BidOrderQty3,BidOrderQty4,BidOrderQty5,BidOrderQty6,BidOrderQty7,BidOrderQty8,BidOrderQty9) as BidOrderQty,fixedLengthArrayVector(BidOrders0,BidOrders1,BidOrders2,BidOrders3,BidOrders4,BidOrders5,BidOrders6,BidOrders7,BidOrders8,BidOrders9) as BidOrders ,fixedLengthArrayVector(OfferPrice0,OfferPrice1,OfferPrice2,OfferPrice3,OfferPrice4,OfferPrice5,OfferPrice6,OfferPrice7,OfferPrice8,OfferPrice9) as OfferPrice,fixedLengthArrayVector(OfferOrderQty0,OfferOrderQty1,OfferOrderQty2,OfferOrderQty3,OfferOrderQty4,OfferOrderQty5,OfferOrderQty6,OfferOrderQty7,OfferOrderQty8,OfferOrderQty9) as OfferOrderQty,fixedLengthArrayVector(OfferOrders0,OfferOrders1,OfferOrders2,OfferOrders3,OfferOrders4,OfferOrders5,OfferOrders6,OfferOrders7,OfferOrders8,OfferOrders9) as OfferOrders,NumTrades,IOPV,TotalBidQty,TotalOfferQty,WeightedAvgBidPx,WeightedAvgOfferPx,TotalBidNumber,TotalOfferNumber,BidTradeMaxDuration,OfferTradeMaxDuration,NumBidOrders,NumOfferOrders,WithdrawBuyNumber,WithdrawBuyAmount,WithdrawBuyMoney,WithdrawSellNumber,WithdrawSellAmount,WithdrawSellMoney,ETFBuyNumber,ETFBuyAmount,ETFBuyMoney,ETFSellNumber,ETFSellAmount,ETFSellMoney from rawTb
//Import into database. Elapsed time: 60s.
loadTable(dbpath, tbName).append!(arrayVectorTb)Total Elapsed time: 165s.
Processing withTransform Parameter
Use loadTextEx function and specify transform parameter
to import text files into distributeddatabases by one step.
Define a user-defined function toArrayVector to combine 10-level
data into a single column, reorder the columns, and return the processed
table.
def toArrayVector(mutable tmp){
//Store multiple columns into a single column. Add it to tmp table, same with update!
tmp[`BidPrice]=fixedLengthArrayVector(tmp.BidPrice0,tmp.BidPrice1,tmp.BidPrice2,tmp.BidPrice3,tmp.BidPrice4,tmp.BidPrice5,tmp.BidPrice6,tmp.BidPrice7,tmp.BidPrice8,tmp.BidPrice9)
tmp[`BidOrderQty]=fixedLengthArrayVector(tmp.BidOrderQty0,tmp.BidOrderQty1,tmp.BidOrderQty2,tmp.BidOrderQty3,tmp.BidOrderQty4,tmp.BidOrderQty5,tmp.BidOrderQty6,tmp.BidOrderQty7,tmp.BidOrderQty8,tmp.BidOrderQty9)
tmp[`BidOrders]=fixedLengthArrayVector(tmp.BidOrders0,tmp.BidOrders1,tmp.BidOrders2,tmp.BidOrders3,tmp.BidOrders4,tmp.BidOrders5,tmp.BidOrders6,tmp.BidOrders7,tmp.BidOrders8,tmp.BidOrders9)
tmp[`OfferPrice]=fixedLengthArrayVector(tmp.OfferPrice0,tmp.OfferPrice1,tmp.OfferPrice2,tmp.OfferPrice3,tmp.OfferPrice4,tmp.OfferPrice5,tmp.OfferPrice6,tmp.OfferPrice7,tmp.OfferPrice8,tmp.OfferPrice9)
tmp[`OfferOrderQty]=fixedLengthArrayVector(tmp.OfferOrderQty0,tmp.OfferOrderQty1,tmp.OfferOrderQty2,tmp.OfferOrderQty3,tmp.OfferOrderQty4,tmp.OfferOrderQty5,tmp.OfferOrderQty6,tmp.OfferOrderQty7,tmp.OfferOrderQty8,tmp.OfferOrderQty9)
tmp[`OfferOrders]=fixedLengthArrayVector(tmp.OfferOrders0,tmp.OfferOrders1,tmp.OfferOrders2,tmp.OfferOrders3,tmp.OfferOrders4,tmp.OfferOrders5,tmp.OfferOrders6,tmp.OfferOrders7,tmp.OfferOrders8,tmp.OfferOrders9)
//Delete previous columns
tmp.dropColumns!(`BidPrice0`BidPrice1`BidPrice2`BidPrice3`BidPrice4`BidPrice5`BidPrice6`BidPrice7`BidPrice8`BidPrice9`BidOrderQty0`BidOrderQty1`BidOrderQty2`BidOrderQty3`BidOrderQty4`BidOrderQty5`BidOrderQty6`BidOrderQty7`BidOrderQty8`BidOrderQty9`BidOrders0`BidOrders1`BidOrders2`BidOrders3`BidOrders4`BidOrders5`BidOrders6`BidOrders7`BidOrders8`BidOrders9`OfferPrice0`OfferPrice1`OfferPrice2`OfferPrice3`OfferPrice4`OfferPrice5`OfferPrice6`OfferPrice7`OfferPrice8`OfferPrice9`OfferOrderQty0`OfferOrderQty1`OfferOrderQty2`OfferOrderQty3`OfferOrderQty4`OfferOrderQty5`OfferOrderQty6`OfferOrderQty7`OfferOrderQty8`OfferOrderQty9`OfferOrders0`OfferOrders1`OfferOrders2`OfferOrders3`OfferOrders4`OfferOrders5`OfferOrders6`OfferOrders7`OfferOrders8`OfferOrders9)
//Change the order of columns
tmp.reorderColumns!(`SecurityID`TradeTime`PreClosePx`OpenPx`HighPx`LowPx`LastPx`TotalVolumeTrade`TotalValueTrade`InstrumentStatus`BidPrice`BidOrderQty`BidOrders`OfferPrice`OfferOrderQty`OfferOrders`NumTrades`IOPV`TotalBidQty`TotalOfferQty`WeightedAvgBidPx`WeightedAvgOfferPx`TotalBidNumber`TotalOfferNumber`BidTradeMaxDuration`OfferTradeMaxDuration`NumBidOrders`NumOfferOrders`WithdrawBuyNumber`WithdrawBuyAmount`WithdrawBuyMoney`WithdrawSellNumber`WithdrawSellAmount`WithdrawSellMoney`ETFBuyNumber`ETFBuyAmount`ETFBuyMoney`ETFSellNumber`ETFSellAmount`ETFSellMoney)
return tmp
}Use loadTextEx function and specify transform as
toArrayVector function. The system will apply
toArrayVector function to the data in the text file and
store the result into the database.
db=database(dbpath)
db.loadTextEx(tbName, `Tradetime`SecurityID, snapFile, schema=schemas, transform=toArrayVector)Total Elapsed time: 100s. 65 seconds quicker than using the
loadText function.
Importing Data in Parallel
Importing a Single File in Parallel
The ploadText function works the same way as the
loadText function but offers the added capability of
loading text files as partitioned in-memory tables using multithreading. It
makes full use of multi-core CPUs to load a file in parallel, making it
well-suited for efficiently loading large files (16MB or more). The parallelism
depends on the number of CPU cores and the configuration parameter
workerNum.
The following compares the performance of functions loadText and
ploadText.
First generate a text file of about 4GB:
filePath="/home/data/testFile.csv"
appendRows=100000000
t=table(rand(100,appendRows) as int,take(string('A'..'Z'),appendRows) as symbol,take(2010.01.01..2018.12.30,appendRows) as date,rand(float(100),appendRows) as float,00:00:00.000 + rand(86400000,appendRows) as time)
t.saveText(filePath);Load the file with loadText and ploadText
respectively. A 6-core 12-thread CPU is used for this test.
timer loadText(filePath);
Time elapsed: 12629.492 ms
timer ploadText(filePath);
Time elapsed: 2669.702 msThe results show that with the configuration of this test, the performance of
ploadText is about 4.5 times as fast as that of
loadText.
Importing Multiple Files in Parallel
In big data applications, data import is often about the batch import of dozens or even hundreds of large files instead of importing one or two files. For optimal performance, we should import a large number of files in parallel.
Function loadTextEx imports a text file into a specified
database, either on disk or in memory. As the partitioned tables in DolphinDB
support concurrent reading and writing, they support multi-threaded data
import.
When we use function loadTextEx to import a text file into a
distributed database, the system imports data into memory first, and then writes
the data to the database on disk. These two steps are completed by the same
function to ensure optimal performance.
The following example shows how to batch write multiple files on disk to a DolphinDB partitioned database. First, execute the following script in DolphinDB to generate 100 files. These files have about 10 million records and have a total size of about 778MB.
n=100000
dataFilePath=".testData/multiImport_"+string(1..100)+".csv"
for (i in 0..99){
trades=table(sort(take(100*i+1..100,n)) as id,rand(`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S,n) as sym,take(2000.01.01..2000.06.30,n) as date,10.0+rand(2.0,n) as price1,100.0+rand(20.0,n) as price2,1000.0+rand(200.0,n) as price3,10000.0+rand(2000.0,n) as price4,10000.0+rand(3000.0,n) as price5)
trades.saveText(dataFilePath[i])
};Create a partitioned database and a table in the database:
dbPath="dfs://DolphinDBdatabase"
db=database(dbPath,VALUE,1..10000)
tb=db.createPartitionedTable(trades,`tb,`id);Function cut can group elements in a vector. The following
script calls function cut to group the file paths to be
imported, and then calls function submitJob to assign write
jobs to each thread.
def writeData(db,file){
loop(loadTextEx,db,`tb,`id,file)
}
parallelLevel=10
for(x in dataFilePath.cut(100/parallelLevel)){
submitJob("loadData"+parallelLevel,"loadData",writeData,db,x)
};In DolphinDB, multiple threads are not allowed to write to the same partition of a database at the same time. In the example above, each text file has a different value of the partitioning column (column 'id'), so we don't need to worry that multiple threads may write to the same partition at the same time. When designing concurrent reads and writes of partitioned tables in DolphinDB, please make sure that only one thread writes to the same partition at the same time.
Use function getRecentJobs to get the status of the last n batch
jobs on the local node. The following script calculates the time consumed to
import batch files in parallel. The result shows it took about 1.59 seconds with
a 6-core 12-threaded CPU.
select max(endTime) - min(startTime) from getRecentJobs() where jobId like ("loadData"+string(parallelLevel)+"%");
/*
max_endTime_sub
---------------
1590
*/The following script shows it took 8.65 seconds to sequentially import 100 files into the database with a single thread.
timer writeData(db, dataFilePath);
Time elapsed: 8647.645 msWith the configuration of this test, the speed of importing 10 threads in parallel is about 5.5 times that of single thread import.
The number of records in the table:
select count(*) from loadTable("dfs://DolphinDBdatabase", `tb);
/*
count
------
10000000
*/Importing a Single Large Text File
DolphinDB supports the use of Map-Reduce in data import. We can divide a text file into multiple parts and import all or some of the parts into DolphinDB with Map-Reduce.
We can use function textChunkDS to divide a text file into multiple
data sources with each data source meaning a part of the text file, and then use
function mr to write the data sources to the database. Function
mr can also process data before saving data to database.
Saving Data in Two Separate Tables
For example, save stocks and futures data in two separate tables.
Execute the following script in DolphinDB to generate a text file that includes both stocks data and futures data. The size of the file is about 1.6GB.
n=10000000
dataFilePath="/home/data/chunkText1.csv"
trades=table(rand(`stock`futures,n) as type, rand(`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S,n) as sym,take(2000.01.01..2000.06.30,n) as date,10.0+rand(2.0,n) as price1,100.0+rand(20.0,n) as price2,1000.0+rand(200.0,n) as price3,10000.0+rand(2000.0,n) as price4,10000.0+rand(3000.0,n) as price5,10000.0+rand(4000.0,n) as price6,rand(10,n) as qty1,rand(100,n) as qty2,rand(1000,n) as qty3,rand(10000,n) as qty4,rand(10000,n) as qty5,rand(10000,n) as qty6)
trades.saveText(dataFilePath);Create the partitioned databases and tables to store stocks data and futures data, respectively:
dbPath1="dfs://stocksDatabase"
dbPath2="dfs://futuresDatabase"
db1=database(dbPath1,VALUE,`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S)
db2=database(dbPath2,VALUE,2000.01.01..2000.06.30)
tb1=db1.createPartitionedTable(trades,`stock,`sym)
tb2=db2.createPartitionedTable(trades,`futures,`date);Define a function to divide data into stocks data and futures data, and to save the data to corresponding databases.
def divideImport(tb, mutable stockTB, mutable futuresTB)
{
tdata1=select * from tb where type="stock"
tdata2=select * from tb where type="futures"
append!(stockTB, tdata1)
append!(futuresTB, tdata2)
}Use function textChunkDS to divide the text file into multiple
parts. In this example the size of each part is 300MB. The file is divided into
4 parts.
ds=textChunkDS(dataFilePath,300)
ds;
/* output
(DataSource<readTableFromFileSegment, DataSource<readTableFromFileSegment, DataSource<readTableFromFileSegment, DataSource<readTableFromFileSegment)
*/Call function mr and specify the result of function
textChunkDS as the data source to import the file into the
database. As the map function (specified by parameter mapFunc) only
accepts a table as the input, here we use partial application to convert
function divideImport into a function that only takes a table
as the input.
mr(ds=ds, mapFunc=divideImport{,tb1,tb2}, parallel=false);In this example, different data sources generated by function
textChunkDS may contain data for the same partition. As
DolphinDB does not allow multiple threads to write to the same partition at
the same time, we need to set parallel=false in function
mr, otherwise an exception will be thrown.
The stocks table contains only stocks data and the futures table contains only futures data.
// stock
select top 5 * from loadTable(dbPath1, `stock);
// futures
select top 5 * from loadTable(dbPath2, `futures);Stocks table:

Futures table:

Quickly Loading Data from the Beginning and the End of Large Files
We can use function textChunkDS to divide a large file into
multiple small data sources (chunks), then load the first and the last one.
Execute the following script in DolphinDB to generate the data file:
n=10000000
dataFilePath="/home/data/chunkText2.csv"
trades=table(rand(`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S,n) as sym,sort(take(2000.01.01..2000.06.30,n)) as date,10.0+rand(2.0,n) as price1,100.0+rand(20.0,n) as price2,1000.0+rand(200.0,n) as price3,10000.0+rand(2000.0,n) as price4,10000.0+rand(3000.0,n) as price5,10000.0+rand(4000.0,n) as price6,rand(10,n) as qty1,rand(100,n) as qty2,rand(1000,n) as qty3,rand(10000,n) as qty4, rand(10000,n) as qty5, rand(1000,n) as qty6)
trades.saveText(dataFilePath);Then use function textChunkDS to divide the text file into
multiple parts. In this example the size of each part is 10MB.
ds=textChunkDS(dataFilePath, 10);Call function mr to load the first chunk and the last chunk:
head_tail_tb = mr(ds=[ds.head(), ds.tail()], mapFunc=x->x, finalFunc=unionAll{,false});View the number of records in table 'head_tail_tb':
select count(*) from head_tail_tb;
/*
count
------
192262
*/Other Considerations
Encoding of Strings
As strings in DolphinDB are encoded in UTF-8, if a text file with string columns
is not UTF-8 encoded, the string columns must be changed to UTF-8 encoding after
importing. DolphinDB provides functions convertEncode,
fromUTF8 and toUTF8 to convert encoding of
strings.
For example, use function convertEncode to convert the encoding
of column 'exchange' in the tmpTB table:
dataFilePath="/home/data/sample.csv"
tmpTB=loadText(filename=dataFilePath, skipRows=0)
tmpTB.replaceColumn!(`exchange, convertEncode(tmpTB.exchange,"gbk","utf-8"));Parsing Numeric Types
DolphinDB can automatically recognize the following formats of numeric data:
- Numeric values, such as 123
- Numeric values with thousands separators, such as 100,000
- Numeric values with decimal point (floating point number), such as 1.231
- Scientific notation, such as 1.23E5
If a column is specified as a numeric type, the system ignores letters or other symbols before and after numeric values when importing. If there are no numbers in an entry, it will be loaded as a null value. Please see the following example for more details.
First, execute the following script to create a text file.
dataFilePath="/home/data/testSym.csv"
prices1=["2131","$2,131", "N/A"]
prices2=["213.1","$213.1", "N/A"]
totals=["2.658E7","-2.658e7","2.658e-7"]
tt=table(1..3 as id, prices1 as price1, prices2 as price2, totals as total)
saveText(tt,dataFilePath);In the text file, both column 'price1' and column 'price2' contain numbers and characters. If we load the text file without specifying parameter schema, the system will identify these 2 columns as SYMBOL types:
tmpTB=loadText(dataFilePath)
tmpTB;
id price1 price2 total
-- ------ ------ --------
1 2131 213.1 2.658E7
2 $2,131 $213.1 -2.658E7
3 N/A N/A 2.658E-7
tmpTB.schema().colDefs;
name typeString typeInt comment
------ ---------- ------- -------
id INT 4
price1 SYMBOL 17
price2 SYMBOL 17
total DOUBLE 16If column 'price1' is specified as INT type and column 'price2' is specified as DOUBLE type, the system will ignore characters and symbols before and after the number when importing. If there are no numbers, an entry is recognized as a null value.
schemaTB=table(`id`price1`price2`total as name, `INT`INT`DOUBLE`DOUBLE as type)
tmpTB=loadText(dataFilePath,,schemaTB)
tmpTB;
id price1 price2 total
-- ------ ------ --------
1 2131 213.1 2.658E7
2 2131 213.1 -2.658E7
3 2.658E-7Automatically Removing Double Quotation Marks
In CSV files, double quotation marks are sometimes used in numeric columns with special characters (such as delimiters). In DolphinDB, the system automatically strips double quotation marks in these columns.
In the text file of the following example, column 'num' contains numeric values with thousands separators.
dataFilePath="/home/data/test.csv"
tt=table(1..3 as id, ["\"500\"","\"3,500\"","\"9,000,000\""] as num)
saveText(tt,dataFilePath);We can see that the system automatically strips the double quotation marks when importing the text file.
tmpTB=loadText(dataFilePath)
tmpTB;
/*
id num
-- -------
1 500
2 3500
3 9000000
*/