From MySQL to DolphinDB
DolphinDB provides several methods to transfer data between MySQL and DolphinDB. The following figure illustrates different methods for data migration between MySQL and DolphinDB:
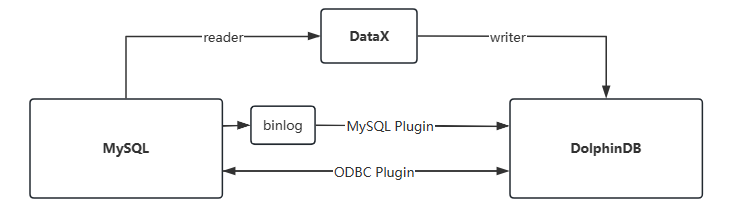
This section focuses on two primary methods: importing and exporting data via the MySQL plugin and the ODBC plugin. Detailed instructions on using the DataX middleware can be found in other pages.
The MySQL plugin is specifically designed for MySQL's Binlog mechanism, serving as a high-speed plugin for efficiently syncing MySQL data to DolphinDB. It supports two data loading methods:
load: Loads MySQL data into a DolphinDB in-memory table. This is ideal for scenarios with smaller datasets (typically less than 1GB) that require rapid access.loadEx: Loads MySQL data directly into either a DolphinDB distributed database or in-memory database. By integrating the loading, cleaning, and storage processes into a single operation, this method is particularly effective for handling large-scale data migrations.
The ODBC plugin, on the other hand, is designed for databases supporting the ODBC protocol. It allows DolphinDB to read data from any ODBC-compliant database and write data back to it, including MySQL.
| Plugin Name | Use Cases | Performance |
|---|---|---|
| ODBC | read and write | moderate |
| MySQL | read only | high |
Installing MySQL and ODBC Plugins
The MySQL and ODBC plugins are pre-installed by default and can be loaded simply by running the following script.
Load MySQL plugin:
loadPlugin("mysql")Load ODBC plugin:
loadPlugin("odbc")The example scripts in this section reference a snapshot table. Below is the script for creating the snapshot table in MySQL:
// execute in MySQL
create database mysqldb;
create table mysqldb.snapshot(
Dates VARCHAR(10),
DateTime TIMESTAMP,
SecurityID VARCHAR(50),
BidPrice DOUBLE,
PreClosePx DOUBLE
);
insert into mysqldb.snapshot (Dates,DateTime,SecurityID,bidPrice,PreClosePx)
values('2024-01-01','2024-01-01 12:00:00','SID001',1.2345,6.789);Create the snapshot table in DolphinDB:
// execute in DolphinDB
create database "dfs://Level2DB" partitioned by VALUE([2024.01.01]),HASH([SYMBOL,20]),engine='TSDB'
create table "dfs://Level2DB"."snapshot" (
Dates DATE,
DateTime TIMESTAMP,
SecurityID SYMBOL,
BidPrice DOUBLE[],
PreClosePx DOUBLE
)
partitioned by _"DateTime",_"SecurityID"
sortColumns=["SecurityID","DateTime"],
keepDuplicates=ALLUsing mysql::load Method
This section uses the snapshot table from MySQL as an example to demonstrate how to
import data into a DolphinDB in-memory table using the mysql::load
method.
Loading Data as DolphinDB In-Memory Table
The MySQL plugin enables DolphinDB data nodes to act as clients, allowing them to execute SQL queries on MySQL datasets and retrieve the results. These results are then serialized into DolphinDB's in-memory tables. During the loading process, the plugin automatically maps MySQL data types to corresponding DolphinDB data types. Data type mappings between DolphinDB and MySQL data types can be found in Plugins > MySQL > Data Types.
For example, use the load method to load data:
conn = mysql::connect(`127.0.0.1, 3306, `root, `root, `mysqldb)
tb = mysql::load(conn, "SELECT * FROM snapshot WHERE DATES = '2024-01-01'")
tb.schema()Data Cleaning
After loading a MySQL table into a DolphinDB in-memory table, data cleaning can be
performed before importing it into the database. Below are some common cases for
column type conversion using DolphinDB's replaceColumn!
function.
- Temporal Type Conversion
MySQL and DolphinDB temporal types do not always align, and time values in MySQL are often stored as strings. Explicit conversion is required, as shown below:
tb.replaceColumn!("DATES",tb["DATES"].string().temporalParse('yyyy-MM-dd')) - Optimizing with SYMBOL Type
DolphinDB's SYMBOL type, a specialized enumerated string format, stores labeled attributes (e.g., stock symbols, device IDs) as integers, enhancing sorting, comparison, and compression. Conversion script:
tb.replaceColumn!("SecurityID",tb["SecurityID"].symbol()) - Combining Multiple Columns into an Array Vector
Multiple columns can be combined into an array vector, such as storing order book data or equipment monitoring data as a DOUBLE array vector. This format can significantly boost analysis and computation efficiency:
tb.replaceColumn!("bidPrice",fixedLengthArrayVector(tb["bidPrice"]))
Persisting Data to Database
After loading data into memory, the table can be directly inserted into a database
using tableInsert. Ensure the corresponding DFS table and database
are already created. Use the following script to insert the data:
dfsTable = loadTable("dfs://Level2DB", "snapshot")
tableInsert(dfsTable, tb)Using mysql::loadEx Method
In addition to explicitly using in-memory tables for database import, DolphinDB mysql
plugin offers the loadEx function that combines loading, cleaning,
and storage into one streamlined process. Its pipeline mechanism connects multiple
processing steps - like filtering, transformation, and aggregation - allowing data
to flow smoothly while each step operates independently. This method makes data
processing both efficient and simple to implement.
Below are examples of its usage for different scenarios.
Importing an Entire Table
When the schema of a MySQL table matches the schema of a DolphinDB distributed table and no data cleaning is needed, you can directly import the entire table using the following steps:
Create a DolphinDB table with the same schema as the MySQL table:
create table "dfs://Level2DB"."snapshot_same" (
Dates STRING,
DateTime TIMESTAMP,
SecurityID STRING,
BidPrice DOUBLE,
PreClosePx DOUBLE
)
partitioned by _"DateTime",_"SecurityID"
sortColumns=["SecurityID","DateTime"],
keepDuplicates=ALLUse loadEx to import the entire table “snapshot” from MySQL:
db = database("dfs://Level2DB")
mysql::loadEx(conn, db,"snapshot_same", `DateTime`SecurityID, `snapshot)
select * from loadTable("dfs://Level2DB", "snapshot_same")Importing Data Using SQL
To import only a subset of the MySQL table, filter the data using a SQL query. This is useful for data selection, time filtering, and preliminary transformations.
For example, import the first row of the snapshot table with a SQL statement:
db = database("dfs://Level2DB")
mysql::loadEx(conn, db,"snapshot_same", `DateTime`SecurityID, "SELECT * FROM snapshot LIMIT 1")
select * from loadTable("dfs://Level2DB", "snapshot_same")Data Transformation Before Import
If data transformation is required before importing into DolphinDB, you can use
the transform parameter in the loadEx function to
specify a user-defined function.
The example below demonstrates how to use a user-defined function,
replaceTable, to convert column types during the import
process:
db = database("dfs://Level2DB")
def replaceTable(mutable t){
t.replaceColumn!("DATES",t["DATES"].string().temporalParse('yyyy-MM-dd'))
t.replaceColumn!("SecurityID",t["SecurityID"].symbol())
t.replaceColumn!("bidPrice",fixedLengthArrayVector(t["bidPrice"]))
return t
}
t=mysql::loadEx(conn, db, "snapshot",`DateTime`SecurityID, 'select * from snapshot limit 1 ',,,,replaceTable)Using ODBC Plugin
The ODBC plugin enables connections to other data sources (e.g., MySQL), facilitating data import into DolphinDB databases or the export of DolphinDB in-memory tables to MySQL or other databases.
This section uses the snapshot table from MySQL as an example to demonstrate how to import data into a DolphinDB in-memory table using the ODBC plugin.
First, establish a connection to a MySQL database via the
odbc::connect method.
conn1 = odbc::connect("Dsn=mysqlOdbcDsn") // mysqlOdbcDsn is the name of data source name
conn2 = odbc::connect("Driver={MySQL ODBC 8.0 UNICODE Driver};Server=127.0.0.1;Database=Level2DB;User=user;Password=pwd;Option=3;") The ODBC plugin enables DolphinDB data nodes to act as clients, allowing them to execute SQL queries on MySQL datasets and retrieve the results. These results are then serialized into DolphinDB's in-memory tables. During the loading process, the plugin automatically maps ODBC data types to corresponding DolphinDB data types. Data type mappings between DolphinDB and ODBC data types can be found in the Plugins > ODBC > Data Type Mappings.
For instance, use the query method to load data where Dates
= '2024-01-01', and then use tableInsert to write the
data into the database:
tb = odbc::query(conn1,"SELECT * FROM mysqldb.snapshot WHERE Dates = '2024-01-01'")
dfsTable = loadTable("dfs://Level2DB", "snapshot_same")
tableInsert(dfsTable, tb)
odbc::close(conn1)Importing Large MySQL Datasets in Parallel
The loadEx method of the MySQL plugin allows efficient parallel
import to DolphinDB DFS tables by breaking large MySQL datasets into smaller chunks
(around 100MB). This approach leverages the distributed architecture of DolphinDB
while avoiding common issues caused by importing large datasets in a single
operation, such as query bottlenecks, memory exhaustion.
For optimal performance, you can align MySQL partitions with the partitioning columns (e.g., dates, stock codes, device IDs) in DolphinDB DFS table. This ensures that multiple processes do not write to the same partition simultaneously, preventing write conflicts.
The following example demonstrates how to partition a large MySQL dataset by specified fields and import it into DolphinDB. The table schemata for MySQL and DolphinDB used in this example are outlined in the following table.
| Database | Database Name | Table Name | Columns |
|---|---|---|---|
| MySQL | demo | sample |
|
| DolphinDB | dfs://demo | sample |
|
Create MySQL database and table as follows:
create database demo;
create table demo.sample(
ts VARCHAR(20),
id VARCHAR(10),
val DOUBLE
);
insert into demo.sample (ts,id,val) values('2024-01-01 12:00:00','SID001',1.2);
insert into demo.sample (ts,id,val) values('2024-01-01 12:00:00','SID002',2.3);
insert into demo.sample (ts,id,val) values('2024-01-01 12:00:00','SID003',3.4);
insert into demo.sample (ts,id,val) values('2024-01-01 12:00:00','SID004',4.5);
insert into demo.sample (ts,id,val) values('2024-01-01 12:00:00','SID005',5.6);
insert into demo.sample (ts,id,val) values('2024-01-02 12:00:00','SID001',6.7);
insert into demo.sample (ts,id,val) values('2024-01-02 12:00:00','SID002',7.8);
insert into demo.sample (ts,id,val) values('2024-01-02 12:00:00','SID003',8.9);
insert into demo.sample (ts,id,val) values('2024-01-02 12:00:00','SID004',9.1);
insert into demo.sample (ts,id,val) values('2024-01-02 12:00:00','SID005',1.2);Use a two-level partitioning strategy to create a DolphinDB database and table: VALUE partitioning for the ts column and HASH partitioning for the id column.
create database "dfs://demo" partitioned by VALUE([2024.01.01]),HASH([SYMBOL,10]),engine='TSDB'
create table "dfs://demo"."sample" (
ts DATETIME,
id SYMBOL,
val DOUBLE
)
partitioned by "ts", "id"
sortColumns=["id","ts"],
keepDuplicates=ALLUse for loop to import data:
// loop through dates
dates=2024.01.01 .. 2024.01.02
// loop through IDs
IDs=`SID001`SID002`SID003`SID004`SID005
// Data transformation
def replaceTable(mutable t){
t.replaceColumn!("ts",t["ts"].string().temporalParse('yyyy-MM-dd HH:mm:ss')) // convert the ts column to specified timestamp format
t.replaceColumn!("id",t["id"].symbol()) // conver the id column to SYMBOL type
return t // return the modified table
}
// data import loop
for(d in dates){
for(id in IDs){
strSQL="select * from demo.sample where id='"+string(id)+"' and date(ts)=date('"+ datetimeFormat(d,"yyyy-MM-dd") +"') "
dbName="dfs://demo"
tableName="sample"
partitionSchema=`ts`id
mysql::loadEx(conn,database(dbName),tableName,partitionSchema,strSQL,,,,replaceTable)
}
}
// check the import results
select * from loadTable("dfs://demo","sample")When using in practice, carefully manage your query volume and number of loops to
avoid overloading MySQL. Since MySQL read speed is usually the bottleneck, consider
adding sleep intervals between operations. For automated data migration, combine
this with submitJob for scheduled batch processing.
Synchronizing MySQL Data
Core business data and configuration settings typically reside in relational
databases like MySQL. To associate external data with the time series data in
DolphinDB, you can use DolphinDB cached tables (cachedTable) for
efficient synchronization. This approach allows for seamless data joins and analysis
while maintaining up-to-date reference data. This section shows how to implement
this synchronization solution.
Create a table in MySQL:
use mysqldb;
create table mysqldb.config(id int,val float);
INSERT INTO config(id,val) VALUES(1,RAND());Load the DolphinDB MySQL plugin and define a function to sync MySQL config table:
login("admin","123456")
// load MySQL plugin
loadPlugin("MySQL")
use mysql
// user-defined function for data synchronization
def syncFunc(){
// retrieve MySQL data
conn = mysql::connect("127.0.0.1",3306,"root","123456","mysqldb")
t = load(conn,"config")
// return table
return t
}
config = cachedTable(syncFunc,60)
select * from configMySQL's configuration info is cached and updated in DolphinDB's dimension table “config”, allowing direct script reference without managing synchronization details. While this simplifies development, note that the polling-based updates make it unsuitable for real-time synchronization.
Data Types Conversion Rules of mysql Plugin
Integral Type
- DolphinDB only supports signed numeric types and handles unsigned types by converting them to larger signed types (e.g., unsigned CHAR to signed SHORT, unsigned SHORT to signed INT). Note that 64-bit unsigned numbers aren't supported.
- 'unsigned long long' is not supported in DolphinDB. For MySQL's 'bigint
unsigned' columns, use DOUBLE or FLOAT in DolphinDB by explicitly specifying
this in the schema parameter when using
loadorloadEx. - Each integer type in DolphinDB uses its minimum value to represent null: -128 for CHAR; -32,768 for SHORT; -2,147,483,648 for INT and -9,223,372,036,854,775,808 for LONG.
Floating-Point Types
- All IEEE754 floating-point numbers are signed.
- MySQL float and double values can be converted to any DolphinDB numeric types (BOOL, CHAR, SHORT, INT, LONG, FLOAT, DOUBLE).
- The newdecimal/decimal type can only be converted to DOUBLE.
String and Enum Types
- Char and varchar types with a length of 10 or fewer characters are converted to the DolphinDB SYMBOL. Otherwise, it will be converted to STRING type.
- String type can be converted to either DolphinDB STRING or SYMBOL.
- Enum type can be converted to either DolphinDB STRING or SYMBOL (default).