DolphinDB 高可用 MVCC 表使用指南
1. 概述
高可用 MVCC 表是DolphinDB基于 Raft 共识协议构建的高可用多版本并发控制(MVCC)表,旨在为关键业务提供强一致性与服务高可用的数据存储解决方案。与普通的 MVCC 表相比,高可用 MVCC 表的所有写操作(如 append、update)都会先通过 Raft 层进行日志复制和共识,然后才应用到表中,从而在节点故障时能够保证数据不丢失;而读操作可直接访问本地副本,无需经过 Raft 共识,因此不会引入额外的延迟。
在此基础上,高可用 MVCC 表通过 Checkpoint 机制进一步保障系统的轻量化和快速恢复:它定期将内存状态持久化到磁盘并清理过期的 Raft 日志,一方面通过截断旧日志防止磁盘空间无限增长;另一方面在节点重启时可优先加载最新的 Checkpoint 文件快速恢复到某个时间点的状态,只需回放其后少量日志即可同步至集群最新状态,从而大大缩短故障恢复时间。此外,Checkpoint 作为表结构和数据的完整物理快照,也为数据安全提供了基础保障。
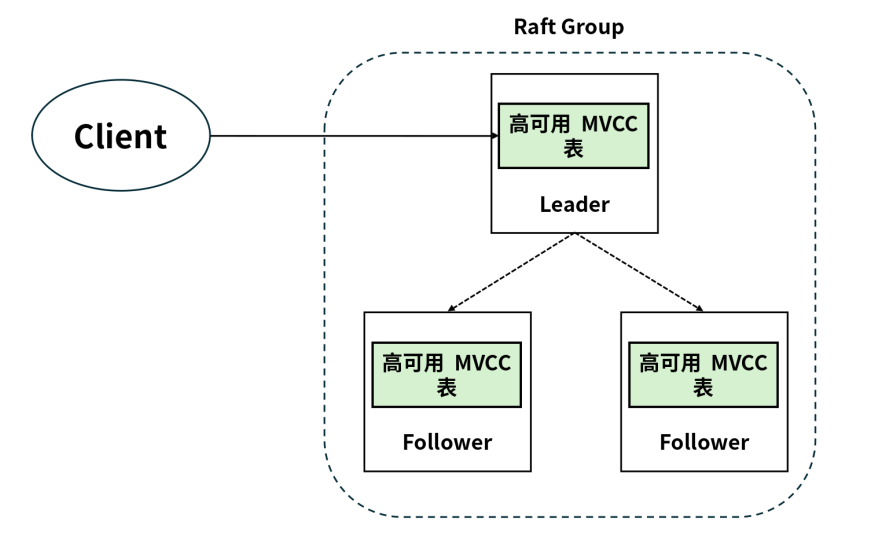
如上图所示,DolphinDB 的高可用 MVCC 表采用了基于 Raft 协议的高可用多副本架构。相同表数据的副本存储在 Raft 组内不同的数据节点上,Raft 协议用来维护多个副本的一致性。Raft 组具有自动恢复的性质,能够容忍小于半数的节点宕机,例如包含三个节点的组,可以容忍一个节点出现故障;包含五个节点的组,可以容忍两个节点出现故障。正常情况下 Raft 组内只有一个 Leader 负责响应来自所有客户端的操作请求、为客户端提供服务,其他节点都是 Follower。
DolphinDB 中高可用 MVCC 表具有以下特性与使用约束:
-
每个节点上可以定义一个或多个 Raft 组,一个 Raft 组可以容纳多个高可用 MVCC 表。
-
创建高可用 MVCC 表时,必须且只能为其指定所属的一个 Raft 组。
-
所有事务操作(如 append、update 操作)只能在 Leader上执行。
-
读取操作不会引入共识层面的额外延迟,但在 Follower 节点上读取可能因日志同步滞后而存在数据延迟,因此建议在 Leader 节点上进行读取。
本教程将详细介绍如何配置与使用高可用 MVCC 表。
2. 高可用 MVCC 表配置与管理
2.1 配置项
要使用高可用 MVCC 表,要求在集群中配置至少三个数据节点或计算节点。
相关的配置项主要的有:
-
mvccTableRaftGroups:配置 Raft 组。格式为:"groupId:node_name1:node_name2:node_name3",其中 groupId 表示 Raft 组号,为大于等于 2 的整数,node_name 为数据节点或计算节点的节点名字,须配置至少 3 个,中间用冒号分隔。系统支持配置多组,用逗号分隔。建议每组的节点分别位于不同的服务器上,以防止一台服务器宕机,组内节点都不可用。
-
mvccTableHADir:高可用 MVCC 表的持久化存储目录。默认目录为:<HomeDir>/log/mvccHA。在集群模式中,需要保证同一机器上的数据节点或计算节点配置了不同的 mvccTableHADir。
-
mvccTableCheckpointInterval:用于控制定期做 Checkpoint 的时间间隔。单位为秒。默认值为300秒。
用户需要在集群 cluster.cfg 配置文件中配置上述参数。以下例子配置了2个 Raft 组,组2包含3个数据节点,分别为 datanode2、datanode3、datanode4。组3包含3个数据节点,分别为 datanode5、datanode6、datanode7。
mvccTableRaftGroups=2:datanode2:datanode3:datanode4,3:datanode5:datanode6:datanode7
mvccTableCheckpointInterval=3002.2 获取 Raft 组
可使用
getHaMvccRaftGroups
函数以获取用户在集群配置的 Raft 组。从而确定当前节点的 Raft 组 ID,供后续建表操作使用。
此函数只能获取当前节点上配置的 Raft 组。例如在上述例子中配置的 datanode2 上运行
getHaMvccRaftGroups()
,结果如下:
| id | sites |
|---|---|
|
2 |
datanode2,datanode3,datanode4 |
2.3 获取 Raft 组的Leader
在集群中配置 Raft 组后,每个 Raft 组会自动选举产生一个 Leader,其余节点作为 Follower。Leader 负责接收并处理客户端请求。当 Leader 发生故障时,系统会自动发起重新选举,选出新的 Leader,从而保证服务的高可用性。
可以通过调用
getHaMvccLeader
函数获取指定 Raft 组当前的 Leader 节点。函数语法如下:
getHaMvccLeader(groupId)其中参数 groupId 是 Raft 组的编号。
需要注意的是,只能在该组配置的数据节点上运行该函数。例如要获取上述例子配置的 Raft 组2的 Leader,可以在 datanode2、datanode3、datanode4上 运行下列代码:
getHaMvccLeader(2)若要在非该组的节点上获取组2的 Leader,需要先获取配置了该组的任意节点,然后使用 rpc 函数到该节点获取
Leader。例子如下:
t=exec top 1 id,node from pnodeRun(getHaMvccRaftGroups) where id =2
leader=rpc(t.node[0],getHaMvccLeader,t.id[0])2.4 创建高可用 MVCC 表
使用函数 haMvccTable 创建高可用 MVCC 表。语法见 haMvccTable。
一个 Raft 组可以包含多个高可用 MVCC 表。这里要注意以下几点:
-
高可用 MVCC 表在日志中持久化了表结构信息,重启后不需要重新建表。
-
只能在 Leader 上执行创建高可用 MVCC 表的函数。
下面的例子在 Raft 组2上创建了一个高可用 Mvcc 表 hmt,指定了每一列的默认值,且允许 name 和 value 列包含空值。
schemaTb = table(10:0, `name`id`value, [STRING,INT,DOUBLE])
haMvccTable(2:2, schemaTb, `hmt, 2,(`str,2,3),[true,false,true])2.5 获取 Raft 组中高可用 MVCC 表的元信息
可以用
getHaMvccTableInfo
函数获取属于该 groupId 的所有高可用 MVCC 表的元信息。语法和介绍见
getHaMvccTableInfo
注:如果要查询 groupId=2 的高可用 MVCC 表的元信息,则必须在 raftGroup 为2的 Raft 成员节点上执行该运维函数。
例如:首先在 Raft 组2的 leader 节点 上创建高可用 MVCC 表
schemaTb = table(10:0, `name`id`value, [STRING,INT,DOUBLE])
haMvccTable(10:0, schemaTb, `t1, 2)在 Raft 组2的任意节点上执行 getHaMvccTableInfo(2) ,可以得到 t1 表的元数据信息如下:
| tableName | rows | memoryUsed | schema | defaultValues | allowNull |
|---|---|---|---|---|---|
|
t1 |
0 |
568 |
name:STRING, id:INT, value:DOUBLE |
NULL, NULL,NULL |
true, true, true |
2.6 读高可用 MVCC 表
在读取高可用 MVCC 表数据前,需要先获取表的句柄。可以在 Raft 组内任意节点上执行 loadHaMvccTable
获取指定的句柄,然后使用 select 语句查询表数据。例如在 datanode2 上获取2.5中 hmt 表的数据:
t=loadHaMvccTable(`hmt)
select * from t得到结果:
| name | id | value |
|---|---|---|
|
str |
2 |
3.0000 |
|
str |
2 |
3.0000 |
2.7 删除高可用 MVCC 表
使用 dropHaMvccTable 删除指定高可用 MVCC 表。语法见 dropHaMvccTable。
3. 高可用 MVCC 表的数据操作
高可用 MVCC 表支持数据操作(插入、更新、删除)和表结构操作(新增列、修改列等)。
不支持以下操作:addColumn、reorderColumns!、upsert!、drop、erase!。
在 Raft 组2新建表:
schemaTb = table(10:0, ["sym","date","price1","price2","price3","price4","price5","price6","qty1","qty2","qty3","qty4","qty5","qty6"], ["SYMBOL","DATE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","DOUBLE","INT","INT","INT","INT","INT","INT"])
trades=haMvccTable(10:0, schemaTb, `trades,2)3.1 插入数据
可以通过以下方法往高可用 MVCC 表中插入数据:
-
SQL insert语句//往指定列插入数据,其他列为空 insert into trades(sym,date) values(`S,2000.12.31) //往所有列插入数据 insert into trades values(`S`IBM,[2000.12.31,2000.12.30],[10.0,20.0],[10.0,20.0],[10.0,20.0],[10.0,20.0],[10.0,20.0],[10.0,20.0],[10,20],[10,20],[10,20],[10,20],[10,20],[10,20]) -
append!函数如果使用
append!函数往表中插入数据,新数据必须是表。例如:tmp=table(`S`IBM as col1,[2000.12.31,2000.12.30] as col2,[10.0,20.0] as col3,[10.0,20.0] as col4,[10.0,20.0] as col5,[10.0,20.0] as col6,[10.0,20.0] as col7,[10.0,20.0] as col8,[10,20] as col9,[10,20] as col10,[10,20] as col11,[10,20] as col12,[10,20] as col13,[10,20] as col14) trades.append!(tmp) -
tableInsert函数tableInsert函数会返回插入的行数。如果使用
tableInsert函数往表中插入数据,新数据必须是表。tmp=table(`S`IBM as col1,[2000.12.31,2000.12.30] as col2,[10.0,20.0] as col3,[10.0,20.0] as col4,[10.0,20.0] as col5,[10.0,20.0] as col6,[10.0,20.0] as col7,[10.0,20.0] as col8,[10,20] as col9,[10,20] as col10,[10,20] as col11,[10,20] as col12,[10,20] as col13,[10,20] as col14) trades.tableInsert(tmp) // output: 2 -
写入高可用
Java、C++ 和 Python API 已支持对该表的高可用写入:在
connect函数中通过 highAvailabilitySites 参数指定多个候选节点(host:port格式的数组)。当 Leader 切换时,API 会自动捕获异常并从中获取新 Leader 信息,切换至新 Leader 继续写入,从而确保节点故障时写入任务不中断。Python API代码举例如下:host = "127.0.0.1" port = 26903 sites = [host+":26903",host+":26904", host+":26905"] s.connect(host=host, port=port, userid="admin", password="123456", highAvailability=True, highAvailabilitySites=sites, reconnect=True)
3.2 更新已存在的列
可以通过以下方法为高可用 MVCC 表更新列:
-
SQL update语句update trades set qty1=qty1+10; update trades set qty1=qty1+10 where sym=`IBM; -
update!函数trades.update!(`qty1, <qty1+10>); trades.update!(`qty1, <qty1+10>, <sym=`IBM>); -
sqlUpdate函数sqlUpdate(trades,<qty1+10 as qty1>).eval() -
赋值语句
trades[`qty1] = <qty1+10>; trades[`qty1, <sym=`IBM>] = <qty1+10>;
3.3 删除行
可以通过以下方法为高可用 MVCC 表删除行:
-
SQL delete语句delete from trades where qty3<20; -
sqlDelete函数sqlDelete(trades,< qty3<30 >).eval()
3.4 增加列
可以通过以下方法为高可用 MVCC 表增加列:
-
SQL update语句update trades set logPrice1=log(price1), newQty1=double(qty1); -
update!函数trades.update!(`logPrice1`newQty1, <[log(price1), double(qty1)]>); -
赋值语句
trades[`logPrice1`newQty1] = <[log(price1), double(qty1)]>;
3.5 删除列
-
通过
drop!函数删除列:trades.drop!("qty1"); -
通过
dropColumns!函数删除列:dropColumns!(trades,`qty3)
3.6 重命名列
通过
rename!
函数重命名列:
trades.rename!("qty2", "qty2New");3.7 修改列
通过
replaceColumn!
函数修改列
replaceColumn!(trades,`qty4,trades[`qty5])3.8 设置高可用 MVCC 表列属性
通过 setHaMvccColumnNullability 设置高可用 MVCC 表的列是否允许为空。语法和用法见 setHaMvccColumnNullability。
通过 setHaMvccColumnDefaultValue 设置高可用 MVCC 表的列的默认值。语法和用法见 setHaMvccColumnDefaultValue。
4. 高可用 MVCC 表运维
4.1 Checkpoint 管理
DolphinDB 提供了两个运维函数用于管理高可用 MVCC 表的 Checkpoint:
-
checkpointHaMvcccheckpointHaMvcc函数可以用来手动强制执行组内节点的 Checkpoint 例如在 Raft 组2中任意节点执行:checkpointHaMvcc(2) -
isCheckpointingHaMvccisCheckpointingHaMvcc可以实时监控指定的 Raft 组是否正在执行 Checkpoint 操作。这为系统的健康检查和运维诊断提供了便利,有助于了解系统后台任务的运行状态。例如在 Raft 组2中任意节点执行:isCheckpointingHaMvcc(2)注:上述两个函数只在当前节点生效,如需在 Raft 组内的其他节点上执行,请先建立与目标节点的连接。
5. 高可用 MVCC 表性能
经测试对比,高可用 MVCC 表(HaMvccTable)在纯写入(insert)场景下,其性能约为普通 MVCC 表(mvccTable)的一半,但在更新和查询等其他场景中,两者性能差异不显著。
因此,如果您的应用场景是日志汇聚、传感器数据等对写入吞吐要求极高,且可以接受短暂服务不可用或数据丢失风险的场景,普通 MVCC 表可能更合适。 如果您的应用场景是金融交易记录、用户核心信息等要求数据强一致性和服务高可用,即使牺牲部分写入性能也值得选择高可用 MVCC 表。
详细的高可用 MVCC 与普通 MVCC 的性能基准测试见文章:高可用 MVCC 与普通 MVCC 的性能基准测试。
6.常见问题
本节汇总了高可用 MVCC 表使用过程中的常见限制与报错,并提供了相应的解决方法,帮助您快速定位和排除问题。
-
Leader 未完成选举
- 报错信息:The leader has not been elected. Try again later。
- 报错原因:Leader 还在选举中。
- 解决方法:首先确保 Raft 组中多数节点(如 3 节点组中至少 2 个)处于正常运行状态,且网络连接正常。正常情况下三个节点的 Raft 组Leader 选举耗时在1-2分钟。建议在应用程序中增加重试机制:遇到此报错时等待 30 秒后重试操作,重复此过程直至成功。
-
非 Leader 节点执行操作报错
- 报错信息:<NotLeader>。
- 报错原因:在非Leader节点执行表操作。
- 解决方法:如果在 server 中操作,需手动切换至 Leader 节点执行;如果是API报错,且正确配置了高可用,会自动切换到Leader节点。
-
Leader 选举后写服务延迟
- 报错信息:Leader is not ready for writes (timeout waiting for logs to be applied) 。
- 报错原因:新选举出的 Leader 需要完成内部状态同步后才能对外提供写服务。
- 解决办法:Leader 选举后自动恢复写服务的时间取决于 Checkpoint 时间、宕机时间等因素。建议在脚本中增加重试机制:当遇到此报错时,等待 1-2 秒后重试写入,并重复此过程直至写入成功。
-
大数据量报错
- 报错信息:写入报错:Append failed in raft group 2, reason: 3, detail: serialize failed: data too large更新报错:Raft propose failed: 3, detail: serialize failed: data too large。
- 报错原因:为确保高可用 MVCC 表的稳定性,DolphinDB 限制了一次性写入或更新数据的大小。
- 解决方法:建议分多批次写入更新,每批数据量控制在128MB以内。
-
写入/更新报错
- 报错信息:Append failed in raft group 2, reason: 2。
- 报错原因:事务执行过程中发生 Leader 切换,可能触发此报错。实际上,事务可以成功提交完成。
- 解决办法:建议try catch 忽略此类报错。
7. 总结
高可用 MVCC 表是 DolphinDB 为需要强一致性和高可用的关键业务提供的多版本并发控制表。它通过 Raft 协议实现了自动故障转移和数据不丢失,尽管在写入性能上较普通 MVCC 表有所下降(约为普通表的一半),但在更新和查询方面表现优异。用户应根据自身业务对数据一致性与写入吞吐的不同要求,在两种表类型间做出合理选择。