nearest join 引擎
nearest join 引擎由 createNearestJoinEngine 函数创建。
nearest join 引擎是一个类似 window join 引擎的窗口数据关联引擎。nearest join 引擎默认左右表数据是有序的,按连接列对左右表数据分组。在分组内,对每条左表数据关联时间不晚于左表记录的最近 k 条右表数据,基于关联结果进行指定的计算并输出。
nearest join 引擎在创建时通过参数 useSystemTime 指定以下两种规则中的一种,用于判断哪些右表数据是时间不晚于左表的最近 k 条右表记录:
-
规则一:以数据注入引擎时的系统时间为时序标准,则每一条左表记录注入引擎时立刻关联并输出
-
规则二:以数据中的时间列为时序标准,当右表数据的最新时刻大于左表数据的时刻时触发该条左表数据关联并输出
在规则二的基础上,通过参数 maxDelayedTime 设置超时强制触发规则。
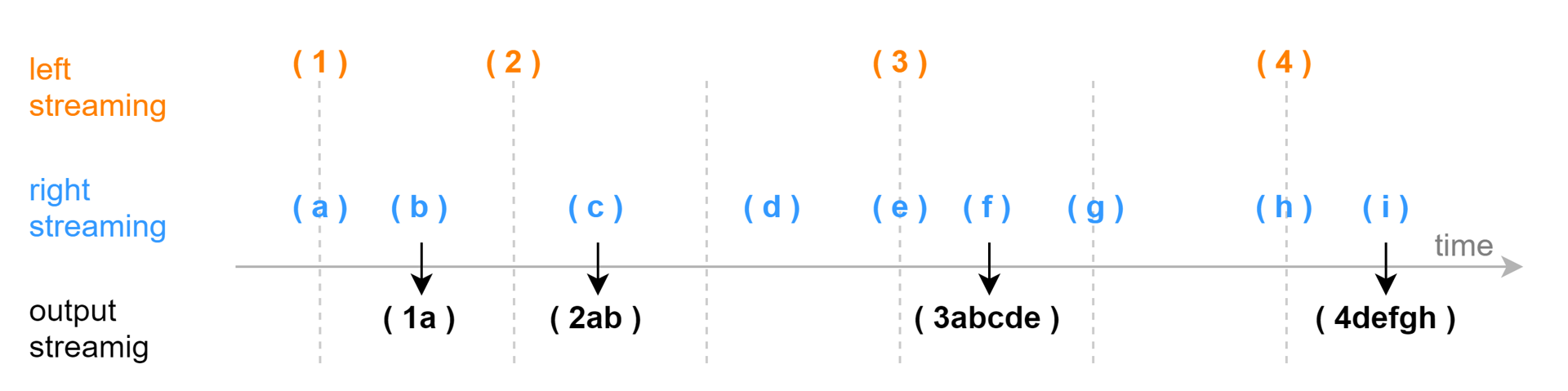
下图展示在一个分组中,以非系统时间触发输出的连接效果。参数 kNearest 设置为 5,每一条左表记录关联时间不晚于该记录的最近 5 条右表数据。输出由时间戳大于左表时刻的第一条右表记录触发,窗口计算不包含这条触发计算的右表记录。
createNearestJoinEngine 函数的语法如下:
createNearestJoinEngine( name, leftTable, rightTable, outputTable, kNearest,
metrics, matchingColumn, [timeColumn], [useSystemTime=false], [garbageSize = 5000],
[maxDelayedTime], [nullFill], [cachedTableCapacity=1024], [snapshotDir],
[snapshotIntervalInMsgCount] )
其参数的详细含义可以参考:createNearestJoinEngine 函数。
应用例子 1-快照频的滚动逐笔因子计算
行情快照和逐笔成交数据从不同维度刻画市场状态,许多高频因子的计算需要将两者有机结合。nearest join 引擎提供了一种高效的方式,为每个行情快照记录匹配其发生前最近的 N 笔逐笔成交数据,实现快照与成交数据的精准融合。这种融合后的数据能够充分捕捉到最新市场微观结构特征,为后续高频因子计算提供丰富的输入基础。
这个场景的核心特征是,每条行情快照记录匹配一个固定数量的最近逐笔成交记录,输出结果与原始快照行情的每条记录一一对应。以下脚本使用 nearest join 引擎,为每个快照关联其发生前最近的10笔逐笔成交,并计算因子:
// create table
share streamTable(1:0, `Sym`Time`BidPrice`AskPrice, [SYMBOL, TIME, DOUBLE[], DOUBLE[]]) as snapshotStream
share streamTable(1:0, `Sym`TradeTime`TradePrice`TradeQty, [SYMBOL, TIME, DOUBLE, LONG]) as tradeStream
colNames = [`Time, `Sym, `TradePriceList, `TradeQtyList, `factor1, `factor2]
colTypes = ["TIME", "SYMBOL", "DOUBLE[]", "LONG[]", "DOUBLE", "DOUBLE"]
share streamTable(10000:0, colNames, colTypes) as outputStream
// create engine
defg myWavg(x){
weight = 1..size(x)
return wavg(x, weight)
}
defg withdrawsVolume(Prices, Volumes){
prevPrices = prev(Prices)
prevVolumes = prev(Volumes)
withdraws = iif(prevPrices == Prices, prevVolumes - Volumes, 0)
withdraws = withdraws[withdraws > 0]
return sum(withdraws)
}
metrics = [
<toArray(tradeStream.TradePrice)>,
<toArray(tradeStream.TradeQty)>,
<myWavg(tradeStream.TradePrice)>,
<withdrawsVolume(tradeStream.TradePrice, tradeStream.TradeQty)>
]
njEngine=createNearestJoinEngine(
name="njEngine",
leftTable=snapshotStream,
rightTable=tradeStream,
outputTable=outputStream,
kNearest=10,
metrics=metrics,
matchingColumn=`Sym,
timeColumn=`Time`TradeTime,
maxDelayedTime=1500
)
// subscribe topic
subscribeTable(tableName="snapshotStream",
actionName="joinLeft",
offset=-1,
handler=appendForJoin{njEngine, true},
msgAsTable=true)
subscribeTable(tableName="tradeStream",
actionName="joinRight",
offset=-1,
handler=appendForJoin{njEngine, false},
msgAsTable=true)-
快照数据 snapshotStream 注入引擎的左表, 逐笔成交数据 tradeStream 注入引擎的右表。
-
引擎参数 useSystemTime=false 表示通过数据中的时间列(左表为 Time 字段,右表为 TradeTime 字段)作为时序标准进行关联计算。
-
引擎参数 kNearest=10表示左表 snapshotStream中的每条数据将与右表 tradeStream中最近 10 条数据关联。
-
引擎参数 metrics 表示计算指标,如 toArray(TradeQty) 表示将右表 TradeQty 字段聚合为 array vector 类型。注意,此处 TradeQty 是右表 tradeStream中的字段,且左表中不存在同名字段。若在 metrics 指定了左表和右表中具有相同名称的列,默认取左表的列,可以通过 "tableName.colName" 指定该列来自哪个表, 如 tradeStream.TradeQty 。
-
引擎参数 maxDelayedTime 是对默认触发机制的补充,以右表最新收到的任意一个分组数据强制触发的方式保证左表所有分组及时匹配并输出,默认值为 3 秒。若不使用 maxDelayedTime 触发机制,对于任意一条左表记录,它必须等到右表出现一条同一分组且时间戳大于它的记录才触发连接计算。但考虑到实际的应用场景中,某个分组的右表记录可能迟迟未能到达,或者始终不可能出现时间戳一条大于某个分组左表数据的右表记录。为了保证左表每条记录都能匹配并输出,建议将 maxDelayedTime 设置为合适的值,使用右表其他分组中最新的数据来强制触发计算。
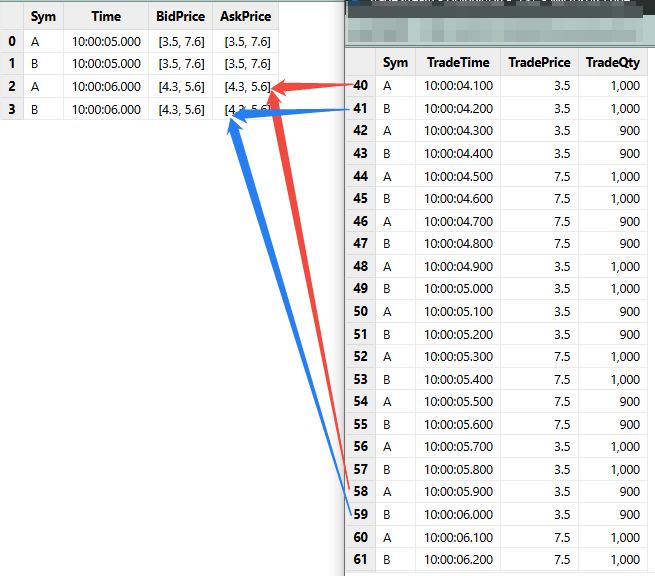
构造数据写入输入的 2 个流数据表(即左表和右表):
// generate data: snapshot
t1 = table(`A`B`A`B as Sym, 10:00:00.000+(5 5 6 6)*1000 as Time, array(DOUBLE[]).append!([3.5 7.6, 3.5 7.6, 4.3 5.6, 4.3 5.6]) as BidPrice, array(DOUBLE[]).append!([3.5 7.6, 3.5 7.6, 4.3 5.6, 4.3 5.6]) as AskPrice)
// generate data: trade
n = 70
t2 = table(take(`A`B, n) as Sym, 10:00:00.000+(1..n)* 100 as TradeTime, take(3.5 3.5 3.5 3.5 7.5 7.5 7.5 7.5, n) as TradePrice, take(1000 1000 900 900, n) as TradeQty)
// input data
snapshotStream.append!(t1)
tradeStream.append!(t2)输入的左、右表关联联系如下:
关联得到的结果表 output 如下,其中 TradePriceList 和 TradeQtyList 两列为 array vector 类型数据,记录了窗口中全部成交记录的 TradePrice 字段明细、TradeQty 字段明细。
