2.00.11
Version 2.00.11.5
System Impacts Caused by Bug Fixes
Introduced a change regarding the permissions for shell function
calls by administrators:
-
In previous release, there is no restriction for administrators to call the
shellfunction. -
Since this release, calling
shellfunctions is not allowed for any user by default, including administrators. To call theshellfunction, you must set the configuration parameter enableShellFunction to true.
Version 2.00.11
Changes Made to Match Industry Practices
- Modified the behavior of configuration parameter
datanodeRestartInterval:
In previous releases, the controller would automatically start data nodes after a crash or manual shutdown;
Since this release, the controller determines whether to start the data node based on the data node outage type. By default, the controller will not attempt to restart a data node automatically if:
-
the data node was stopped via the
stopDataNodecommand executed on the controller. -
or the data node was stopped via the stop node button in the web interface.
-
-
In previous releases, granting the DB_OWNER permission for databases with specific prefix patterns could overwrite the previous grant operation;
Since this release, repeated grants of the DB_OWNER permission using prefix patterns are now additive instead of overwriting.dbNames = ["dfs://db1_owner*", "dfs://db2_owner*"] grant("user1", DB_OWNER, dbNames[0]) grant("user1", DB_OWNER, dbNames[1]) getUserAccess("user1")[`DB_OWNER_allowed][0] // Output (previous releases): dfs://db2_owner* // Output (since this release): dfs://db1_owner*,dfs://db2_owner* -
Modified the behavior of granting permissions after a global denial. The permissions include: DB_READ, DB_WRITE, DB_INSERT, DB_UPDATE, DB_DELETE, TABLE_READ, TABLE_WRITE, TABLE_INSERT, TABLE_UPDATE, TABLE_DELETE, DBOBJ_CREATE, DBOBJ_DELETE, VIEW_EXEC, DB_MANAGE, DB_MANAGE, DB_OWNER, DB_OWNER
- In previous releases, the grant operation could take effect;
- Since this release, the grant operation does not take effect.
deny("group1", DB_OWNER, "*") grant("group1",DB_OWNER, "dfs://test1*" ) // In previous releases, the grant operation could take effect. // An error will be reported since this release: Invalid grant: grant [dfs://test1*] and [deny *] are in conflict.' addGroupMember("user2", "group1") deny("group1", DB_OWNER, "*") grant("user2",DB_OWNER, "dfs://test1*" ) // In previous releases, the grant operation could take effect. // Since this release, this operation does not take effect or throw an error. -
Query result ordering has changed when using
context byon a partitioned table without usingorder by.In previous releases,
-
The order was undefined if the
fromclause did not contain a table join, the table used a COMPO partition, and the only context-by column was a partitioning column. -
In cases other than that mentioned above:
-
If the
selectstatement did not contain aggregate functions, order-sensitive functions, or user-defined functions, and there was no HAVING clause, the results were sorted based on the partitions. -
Otherwise, the results were grouped and ordered based on the context-by columns.
-
Since this release, the returned results are ordered based on the context-by columns.
n = 10 t = table([1,2,3,3,2,1,1,3,2,1] as id,[1,2,3,3,2,1,1,3,2,1] as sym, 1..10 as val) if(existsDatabase("dfs://test")){ dropDatabase("dfs://test") } db = database("dfs://test", HASH, [INT,2]) pt = db.createPartitionedTable(t, `pt, `id).append!(t) select sym from pt context by sym // Output (previous releases): [2,2,2,1,3,3,1,1,3,1] // Output (since this release):[1,1,1,2,2,2,2,2,3,3] -
-
In previous releases, the marketName parameter for function
addMarketHolidaycould use non-alphabetic characters and had no length limit;Since this release, marketName can only consist of four uppercase letters.
System Impacts Caused by Bug Fixes
-
In previous releases, denying the DB_OWNER permission for databases with specific prefix patterns incorrectly denied the DB_OWNER permission for all databases;
Since this release, this operation is no longer allowed.
deny("user1", DB_OWNER,"dfs://db1_owner*") // No error is reported in previous releases. // An error will be reported since this release: DENY to DB_OWNER only applies when objs is '*'.'
-
Enhanced error messages when the order-by column is of BLOB type or an array vector:
In previous releases, the sorting did not take effect but no error was reported.
Since this release, an error is reported in such cases.
t=table(100:100, `col1`col2`blobv,[INT, INT, BLOB]) t[`col1] = rand(1..10,100) t[`col2] = 1..100 t[`blobv] = blob(string(rand("aa"+string(1..10),100))) select * from t order by blobv // In previous releases, the sorting did not take effect but no error was raised. // An error will be reported since this release: StringVector::sort not implemented yet select * from t order by col1, blobv // In previous releases, the sorting did not take effect but no error was raised. // An error will be reported since this release: Failed to sort vector blobv
-
Enhanced error messages when the order-by column has the same name as a built-in function:
In previous releases, the sorting did not take effect but no error was reported.
Since this release, an error "Failed to sort vector <functionName>" is reported in such cases.
n=1000 tmp=table(take(now()+1..100,n)as time,rand("sym"+string(1..100),n) as sym,rand(10.0,n) as price,rand(10.0,n) as val) select * from tmp order by time,symbol // In previous releases, the sorting did not take effect but no error was raised. // An error will be reported since this release: Failed to sort vector symbol
-
Added size constraints for STRING, BLOB, and SYMBOL data written to distributed databases.
In previous releases:
-
STRINGs over 64 KB might cause deserialization failures when replaying the redo log.
-
BLOBs over 64 MB could be written;
-
SYMBOLs over 255 bytes could be written.
Since this release:
-
STRINGs over 64 KB are truncated to 65,535 bytes;
-
BLOBs over 64 MB are truncated to 67,108,863 bytes;
-
SYMBOLs over 255 bytes will throw an exception.
-
-
Calculation rule change in function
wjwhen window is set to 0:0:- In previous releases, the windows over the right table are
determined by all matching records, i.e., the calculation rule of
ej. - Since this release, the windows over the right table are determined by the current timestamp in the left table and its previous timestamp.
- In previous releases, the windows over the right table are
determined by all matching records, i.e., the calculation rule of
-
Behavior change in function
addFunctionView:- Previous releases allowed creating multiple function views referencing the same user-defined function.
- Since this release, attempting to create a function view that
already exists will throw an error
The FunctionView [xxx] already exists, please drop it before adding a new one.
-
Behavior change in row-based vector functions:
- In previous releases, inputting a columnar tuple for row-based functions returned an array vector.
- Since this release, configuration parameter keepTupleInRowFunction is added to specify whether to return a columnar tuple (default) or an array vector.
-
Behavior change in functions
transFrep,resample,asFreq,temporalSeq,spline,neville,loess, anddividedDifference:- In previous releases, for the time precision of rule larger than day, any specified close and label values would be interpreted as the default value.
- Since this release, both 'right' and 'left' specified for close and label take effect.
temporalSeq(2023.01.01,2023.01.20,"2W","left") //Output(previous releases):[2023.01.01,2023.01.15,2023.01.29], closed = left 不生效 //Output(since this release):[2023.01.15,2023.01.29], closed = left 生效 -
Behavior change in functions
transFreq,resample, andasFreqwith parameter rule set as the identifier of the trading calendar:Since this release, naming the trading calendar identifier with digits is no longer permitted. The number specified before the code in rule is interpreted as the frequency for applying func.
Supposing a specified rule "10AIXK":
-
In previous releases, "10AIXK" means every trading day defined in trading calendar named "10AIXK".
-
Since this release, "10AIXK" means every 10 trading days defined in trading calendar named "AIXK". If you have a trading calendar "10AIXK" before, you can no longer read the data from "10AIXK". The result is returned based on "AIXK" now.
s =[2021.12.30, 2022.01.02, 2022.01.03, 2022.01.05, 2022.01.07, 2022.01.09] s.transFreq("10AIXK") //Output(previous releases): [2021.12.29,2021.12.31,2021.12.31,2022.01.04,2022.01.06,2022.01.06] //Output(since this release): [2021.12.30,2021.12.30,2021.12.30,2021.12.30,2021.12.30,2021.12.30] -
Version 2.00.11.1
System Impacts Caused by Bug Fixes
Behavior change on updating DFS tables using UPDATE statement together with aggregate, order-sensitive, and user-defined functions:
-
In previous releases, an incorrect result would be returned. It implemented the same behavior as UPDATEs that include a CONTEXT BY clause with all partitioning columns specified, which only updates data within partitions.
-
Since this release, such UPDATEs across partitions will throw an error.
dbName = "dfs://test_update" if (existsDatabase(dbName)) { dropDatabase(dbName) } // create a partitioned table with 2 partitions and 3 entries in each partition numParts = 2 numRowsPerPart = 3 numRows = numParts * numRowsPerPart t = table(stretch(1..numParts, numRows) as partCol, take(1..numRowsPerPart, numRows) as val); db = database(dbName, VALUE, 1..numParts, engine="TSDB") pt = db.createPartitionedTable(t, "pt", partitionColumns="partCol", sortColumns="partCol") pt.append!(t) //The previous releases only updated the data within the partition, not the entire table. update pt set val=prev(val) //It is equivalent to update pt set val=prev(val) context by partColOutput:
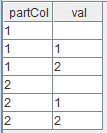
//Since this release, an error will be reported. update pt set val=prev(val) //prev(val) => Aggregate or order-sensitive functions are not allowed without context by clause when updating a partitioned table.-
New restrictions on ORDER BY clause behavior for DFS table queries:
-
Previous releases allowed order-sensitive or user-defined functions on ORDER BY columns, which resulted in inconsistent sort orders - computed differently within or across partitions.
-
Since this release, an error will be reported.
dbName = "dfs://test_orderby" if (existsDatabase(dbName)) { dropDatabase(dbName) } // create a partitioned table with 2 partitions and 3 entries in each partition numParts = 2 numRowsPerPart = 3 numRows = numParts * numRowsPerPart t = table(stretch(1..numParts, numRows) as partCol, take(1..numRowsPerPart, numRows) as val); db = database(dbName, VALUE, 1..numParts, engine="TSDB") pt = db.createPartitionedTable(t, "pt", partitionColumns=`partCol, sortColumns=`partCol) pt.append!(t) //In previous releases: //Scenario 1: Use ORDER BY to sort next(val) within a partition. select * from pt order by next(val) //Scenario 2: Use ORDER BY to sort next(val) across partitions. select *, next(val) from pt order by next(val)Output for scenario 1:
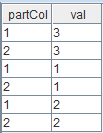
Output for scenario 2:
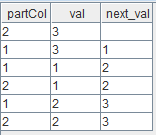
//Since this release, an error will be reported. //Order-sensitive or user-defined functions are not allowed in the order by clause [next(val) asc] for a query over a parti tioned table.'-
Behavior change in
wjwhen agg is specified ascountand no matches exist in right table:-
Previous releases returned null values.
-
Now returns 0.
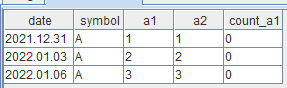
s1 = take([2021.12.31,2022.01.03,2022.01.06] ,3) s2 = take([2020.01.14],1) t1 = table(s1 as date, take("A", 3).sort() as symbol, 1..3 as a1,1..3 as a2) t2 = table(s2 as date, take("F", 1).sort() as symbol, 1..1 as a1, 1..1 as a2).sortBy!("date") select * from wj(t1, t2, 0:2,<[count(t2.a1)]> , ["symbol","date"]) order by symbol,dateIn previous releases, null values were output in the "count_a1" column:
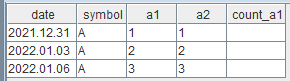
Since this release, 0 is returned in the "count_a1" column:
-
-
Behavior change in functions
each,eachPre,eachPost,eachLeft,eachRight,cross,reduce,accumulate,any,all,loop,ploopwhen args is an empty object:-
In previous versions, some functions threw exceptions and some returned null values (e.g.,
loop,ploop). -
Since this release, an empty tuple will be returned.
each(sum,[]) //In previous releases, an error will be reported. Empty object can't be applied to the higher order function 'each //Since this version, an empty tuple will be returned. -